
MOLAR NEWS
2020年第24期
MolarData人工智能每周见闻分享,每周一更新。
不再重复造轮子,AI 给你推荐更好的代码,还没bug
程序员的的代码大部分都不是如同写书法那般一挥而就,而需要反复地抠bug,抠到怀疑人生。


英特尔、麻省理工学院、佐治亚理工学院的研究人员合作开发了自动化代码相似性检测系统MISIM,该系统可以判断两段代码的相似性,即便这两段代码使用的是不同的结构和算法,也可以依据它们是否执行相似的任务、是否有相似的代码特征加以判断。代码相似性检测可以应用在代码推荐、自动修复bug中。在代码推荐的应用过程有点像输入法的词推荐,由于MISIM可以对不完整的代码片段进行评估,当它检测到不完整的、有bug的代码时,就会从其它地方选出功能一样的、没有bug的代码,来替换原来的代码。

并且,MISIM 还会将代码转换为统一的形式,确定代码功能,从而在不受编写方式的影响下进行代码片段的对比。由于MISIM不受编程语言限制,它还可以用于代码语言转换。在45,780个程序的实验评估中,MISIM识别C和C ++程序中的代码,这些程序是由学生编写的,旨在解决104个编码问题。如果一对程序都解决了相同的问题,则它们在数据集中被标记为相似。MISIM的表现始终好于三个当前最先进系统,最高达到40.6倍。自动代码生成一直是一个研究热点,产业界和学术界都在此方向上努力着。

当然,代码相似性检测也可以用于代码查重。

MISIM由两个核心组件组成。首先,MISIM具有新型的上下文感知语义结构(CASS),该结构通过捕获描述代码上下文的信息,使用机器学习算法来确定给定源代码的目的(例如,代码是一个函数调用、一个操作等)。其次,MISIM还具有基于神经网络的代码相似性评估算法,该算法可通过各种神经网络架构来实现。
研究人员仍然在扩展MISIM的特征集,目的是创建一个代码推荐引擎,它能够识别算法背后的意图,并提供语义上相似但性能有所提高的候选代码。系统可以指示程序员使用库函数,而不用再重复造轮子。像MISIM这样的以AI为动力的代码建议和审查工具有望大幅削减开发成本,同时使编码人员能够专注于更具创造性、减少重复性的任务。英特尔实验室首席科学家兼机器编程研究总监Justin Gottschlich表示:“如果该系统能取得成功,我们的最终目标之一就是实现全民编程。”或许有一天,代码相似性检测可以扩展到自然语言中,到时候要实现全民编程,就不再是难事。
来源:AI科技评论
你的《超级马里奥兄弟》通关了没?基于PPO强化学习算法的AI成功拿下29个关卡!

《超级马里奥兄弟》你能玩到第几关?
说起这款FC时代的经典游戏,大家可能再熟悉不过了,大鼻子、留胡子,永远穿着背带工装服的马里奥大叔,成为了很多80/90后的童年回忆。
最早发行的这版《超级马里奥兄弟》设置8个场景,每个场景分为4关,共32个关卡,相信很多朋友至今还没有完全通关。
Viet Nguyen就是其中一个。这位来自德国的程序员表示自己只玩到了第9个关卡。因此,他决定利用强化学习AI算法来帮他完成未通关的遗憾。
现在他训练出的AI马里奥大叔已经成功拿下了29个关卡。

Viet Nguyen使用的强化学习算法正是OpenAI研发的近端策略优化算法(Proximal Policy Optimization,简称PPO),他介绍,此前使用A3C代码训练马里奥闯关,效果远不及此,这次能够达到29关也是超出了原本的预期。
为了让AI掌握游戏规则,学会运用策略,强化学习是研究人员常用的机器学习方法之一,它能够描述和解决AI智能体(Agent)在与环境交互过程中通过学习策略实现特定目标的问题。近端策略优化算法(PPO)已成为深度强化学习基于策略中效果最优的算法之一。有关该算法的论文已经发布在arXiv预印论文库中。
论文中指出,PPO是一种新型的策略梯度(Policy Gradient)算法,它提出新的“目标函数”可以进行多个训练步骤,实现小批量的更新,解决PG算法中步长难以确定的问题。固定步长的近端策略优化算法如下:
 (每次迭代时,N个actor中的每个都收集T个时间步长的数据。然后在这些NT时间步长的数据上构建替代损失,并使用 minibatch SGD 进行K个epochs的优化。)研究人员表明,该算法具有信任区域策略优化(TRPO)的一些优点,但同时比它实施起来更简单,更通用,具有更好的样本复杂性(凭经验)。为了证实PPO的性能,研究人员在一些基准任务上进行了模拟测试,包括人形机器人运动策略和Atari游戏的玩法。在游戏角色的AI训练中,一种基本的功能是具备连续性的运行和转向,如在马里奥在遇到诸如地面或者空中障碍时,能够以此为目标进行跳转和躲避。论文中,研究人员为了展示PPO的高维连续控制性能,采用3D人形机器人进行了测试,测试任务分别为:
(每次迭代时,N个actor中的每个都收集T个时间步长的数据。然后在这些NT时间步长的数据上构建替代损失,并使用 minibatch SGD 进行K个epochs的优化。)研究人员表明,该算法具有信任区域策略优化(TRPO)的一些优点,但同时比它实施起来更简单,更通用,具有更好的样本复杂性(凭经验)。为了证实PPO的性能,研究人员在一些基准任务上进行了模拟测试,包括人形机器人运动策略和Atari游戏的玩法。在游戏角色的AI训练中,一种基本的功能是具备连续性的运行和转向,如在马里奥在遇到诸如地面或者空中障碍时,能够以此为目标进行跳转和躲避。论文中,研究人员为了展示PPO的高维连续控制性能,采用3D人形机器人进行了测试,测试任务分别为:
(1)仅向前运动;(2)每200个时间步长或达到目标时,目标位置就会随机变化;(3)被目标击倒后,需要从地面站起来。以下从左至右依次为这三个任务的学习曲线。

研究人员从以上学习曲线中,随机抽取了任务二在某一时刻的性能表现。如下图:

可以看出,在第六帧的放大图中,人形机器人朝目标移动,然后随机改变位置,机器人能够跟随转向并朝新目标运行。说明PPO算法在连续转控方面具备出色的性能表现。那么它在具体游戏中“获胜率”如何呢?研究人员运用Atari游戏合集(含49个)对其进行验证,同时与A2C和ACER两种算法进行了对比。为排除干扰因素,三种算法全部使用了相同的策略网络体系,同时,对其他两种算法进行超参数优化,确保其在基准任务上的性能最大化。
 如上图,研究人员采用了两个评估指标:(1)在整个训练期间每集的平均获胜数;(2)在持续100集训练中的每集的平均获胜数。前者更适合快速学习,后者有助于最终的比赛表现。可以看出PPO在指标一种的获胜次数达到了30,在小样本下有更高的胜率。最后研究人员还强调,PPO近端策略优化的优势还在于简洁好用,仅需要几行代码就可以更改为原始策略梯度实现,适用于更常规的设置,同时也具有更好的整体效果。
如上图,研究人员采用了两个评估指标:(1)在整个训练期间每集的平均获胜数;(2)在持续100集训练中的每集的平均获胜数。前者更适合快速学习,后者有助于最终的比赛表现。可以看出PPO在指标一种的获胜次数达到了30,在小样本下有更高的胜率。最后研究人员还强调,PPO近端策略优化的优势还在于简洁好用,仅需要几行代码就可以更改为原始策略梯度实现,适用于更常规的设置,同时也具有更好的整体效果。
来源:AI科技评论
靠「老板语音」骗走182万!音频版Deepfake让员工真假难辨乖乖转账,专家:目前无解
Deepfake模仿生成人脸效果出众,真假难辨。

由此引发的争议和担忧,使得各大平台先后封杀了Deepfake。
但最近,外媒又报道了不法之徒用音频版Deepfake开始了新的诈骗活动,“一血”就拿下24.3万美元(约182万人民币)。
棘手的是,目前安全专家毫无破解之法。
今年6月,一家美国的科技公司员工收到了“自家”CEO发来的语音邮件,要求他“马上协助完成一笔紧急的生意”。
但是,这次CEO的声音听起来却有一点怪。员工觉得是boss的声音没错,但是感觉机械了点,尖锐了点,而且这种语音邮件的联系方式也很反常。
这位员工还是比较机敏,把事情上报给了公司法务,终于证实这是一起合成人类语音的诈骗事件。
随后,这家公司把相关资料提供给了美国安全咨询公司Nisos来调查,但结果却无法令人满意。
Nisos使用Spectrum3d音频频谱图工具分析了Deepfake语音邮件的音频记录。
技术人员注意到了音频频谱图中的峰值反复出现。Nisos怀疑是Deepfake创作者用多个轨道的声音合成后播放,以此来伪造某一目标人物的音色。
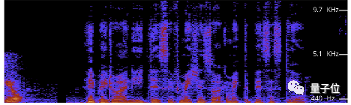
此外,音频频谱断断续续,与正常的人类录音不一致。以1.2倍速度播放时,这段音频听起来更像是文本转语音的软件合成结果。
最重要的一点,研究人员没有在这段音频中检测到任何背景噪音。
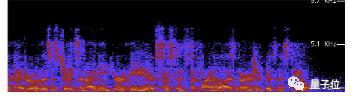
比较Deepfake音频和正常人类录音,可以发现真实情况下,频谱的音高和音调更加平滑,而且背景中总能检测到噪音。
但是,Nisos的分析也只能到此为止了,因为缺乏更多的数据样本,研究人员无法知晓或推测生成音频的算法模型细节。
Nisos找到了一个疑似诈骗犯使用的电话号码,但是没有任何注册身份信息,出于法律原因,Nisos没有回拨号码去联系。

所以,目前来看,还没有识别和追踪诈骗者的技术手段。
但研究人员总结了Deepfake音频的特点。Deepfake音频创作者为了创建更为逼真的音频,通常需要满足如下几个条件:
1、截获目标人物几乎没有背景噪音的高质量音频;
2、在对方不需要或无法回电、交谈的情况下发送音频;
3、以留言的形式避免与音频接收者实时交谈。
2019年9月,英国出现了第一起Deepfake音频诈骗事件。
犯罪分子使用音频版Deepfake对英国一家能源公司高管的声音进行模仿。
该公司的执行董事在接听诈骗电话后将超过24.3万美元汇入了一个匈牙利账户。
第一笔进账后,骗子接着打了第二个要求转账的电话,这才引起了怀疑。
目前,该罪犯仍未被抓获,但据外媒报道,这起案件中的Deepfake音频效果及其逼真,不仅模仿了音色,对于标点、语调的把握也十分到位,甚至还学会了公司boss的德国口音。

今年2月,互联网安全公司Symantec报告了三起Deepfake音频诈骗案例,犯罪分子通过电话会议、YouTube、社交媒体以及TED演讲获得了公司高管的音频,然后用Deepfake算法复制高管的声音,致电财务部门的高级成员要求紧急汇款。
骗子一般利用VoIP网络电话账号联系攻击对象,绕过通话,直接使用语音邮件功能发送合成音频。
Nisos认为,现在的小规模发送Deepfake音频,可能只是犯罪分子在“试水”,随着Deepfakes的创建或购买变得越来越容易,音频、视频的合成处理质量不断提高,此类电子诈骗将更为普遍。
来源:量子位
人工情报分析能力不敌AI,摄星智能打造超强军事指挥“大脑”
纵观人类战争史,前沿科技往往首先应用于军事领域。如今,人工智能已经成为新一轮军事革命的核心驱动力,未来的军事战争也在强烈呼唤AI与军事深度融合。
2016年,美国辛辛那提大学研发的“阿尔法”人工智能软件,在模拟空战中操控三代机击败了由退役空军上校驾驶的战机。可以预见,人工智能将成为未来战争的核心武器。
近几年,中国意识到人工智能的战略地位,并注重新兴科技在军事领域的应用。在此背景下,南京摄星智能科技有限公司(以下简称“摄星智能”)于2018年9月成立。自成立以来,摄星智能便专注在人工智能技术在军事防务领域的应用,将最先进的算法模型与国防场景深度融合。

经过两年的积累,摄星智能自主研发了防务领域的专用算法,并在2020年相继发布了“星智”算法平台和“星河”军事知识图谱。其中“星智”算法平台更是解决了当前军事智能应用国产自主开发环境缺失、基础算法模型重复开发、专用算法模型库空白等问题。

从机械化、信息化到智能化,战争形态已经发展到新阶段,军事智能可能成为决定未来战争胜负的关键要素。而且,军事智能化要渗透到军事系统的方方面面,如军队指挥决策、战法运用、部队控制等环节。在这些环节中,“作战指挥”是核心。
“有时,作战参谋制定作战方案可能需要花费1天时间。”张亚琦讲述道。很多时候,作战参谋为了想出更好的作战方案,会查阅大量资料,如军事网站新闻、军事书籍、武器装备图册等。
如果摄星智能想为机器安装“智能大脑”,辅助参谋智能分析军事情报,全面支撑“军事辅助决策”。那么,摄星智能需要整理海量数据,并为“智能大脑”建设“知识库”。
由于摄星智能长期专注防务领域应用场景,且防务专用语料数据丰富。因此,“星智”算法平台相比其它算法平台还具有更强的领域专业性和更高的模型准确度,部分基础算法如领域知识问答、搜索、装备能力对比分析等算法准确率可达95%。
如今,摄星智能已经成功进入到防务领域,并衍生出多重服务内容。摄星智能已推出知识、情报、策略和反深度伪造四大领域产品解决方案。之后,摄星智能还将陆续推出情报、辅助决策等业务领域的智能产品与技术解决方案,为防务领域用户提供一站式AI辅助决策解决方案和全栈技术产品。
来源:量子位
手机NFC瞬间不香了!红外拍摄+皮肤下特征识别 刷手就能坐公交!
随着技术的进步,自动驾驶技术也加快了落地的速度。相较于私家车辆,商用运营车辆的自动驾驶落地要更快一些。
日前,我们于网络渠道了解到,深兰科技研发的“熊猫智能公交车”正在做开放道路自动驾驶里程测试,这也是上海进行开放道路测试的首辆无人驾驶公交车。
同其自动驾驶技术具有一样的看点,这款自动驾驶公交车外形也很是新颖独特,外观酷似国宝大熊猫,前脸除了两个“黑眼圈”大灯之外,车顶还有两个熊猫耳朵,造型时尚可爱。
原创文章,作者:整数智能,如若转载,请注明出处:https://www.agent-universe.cn/2020/08/8509.html