
MOLAR NEWS
2020年第41期
MolarData人工智能每周见闻分享,每周一更新。
全英雄池解禁!腾讯AI“绝悟”升级至完全体,研究入选NeurIPS 2020


11月28日腾讯宣布,由腾讯 AI Lab 与王者荣耀联合研发的策略协作型 AI“绝悟”推出升级版本。“绝悟”一年内掌握的英雄数从1个增加到100+个,实现了王者荣耀英雄池的完全解禁,此版本因此得名“绝悟完全体”。
团队的长期目标,就是要让“绝悟”手握强兵,学会所有英雄的技能,且每个英雄都能达到顶尖水平,因此在技术上做了三项重点突破:
首先,团队构建了一个最佳神经网络模型,让模型适配MOBA类任务、表达能力强、还能对英雄操作精细建模。模型综合了大量AI方法的优势,具体而言,在时序信息上引入长短时记忆网络(LSTM)优化部分可观测问题,在图像信息上选择卷积神经网络(CNN)编码空间特征,用注意力(Attention)方法强化目标选择,用动作过滤(Action Mask)方法提升探索效率,用分层动作设计加快训练速度,用多头值估计(Multi-Head Value)方法降低估计方差等。
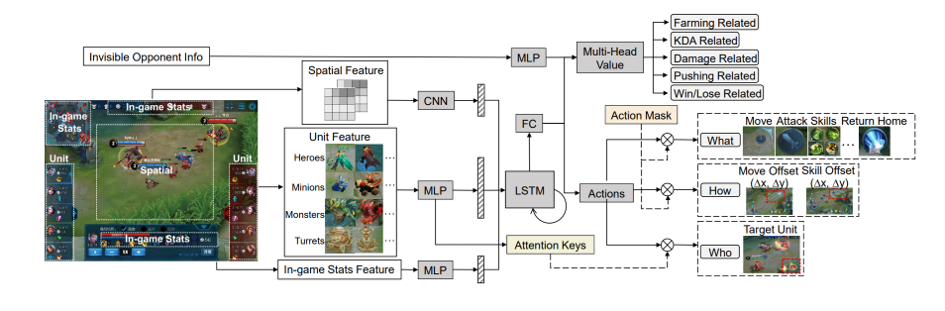
其次,团队研究出了拓宽英雄池,让“绝悟“掌握所有英雄技能的训练方法——CSPL(Curriculum Self-Play Learning,课程自对弈学习)。
最后,团队还搭建了大规模训练平台——腾讯开悟(aiarena.tencent.com),依托项目积累的算法经验、脱敏数据及腾讯云的算力资源,为训练所需的大规模运算保驾护航。
来源:AI科技评论
TKDE | 中科大提出RiskSeq:第一项针对时空多粒度城市交通风险预测的工作
现有的交通事故预测任务大多分为长期预测和短期预测,前者是预测下一周每日的事故总数,形成事故风险图,但空间尺度是固定的;后者是预测1小时后的事故总数,只有单步预测,缺点是不能感知到路网未来多步的实时变化。长期预测方式对于实时智能交通系统作用甚微,因此本文着眼实时系统,研究短期交通事故预测。
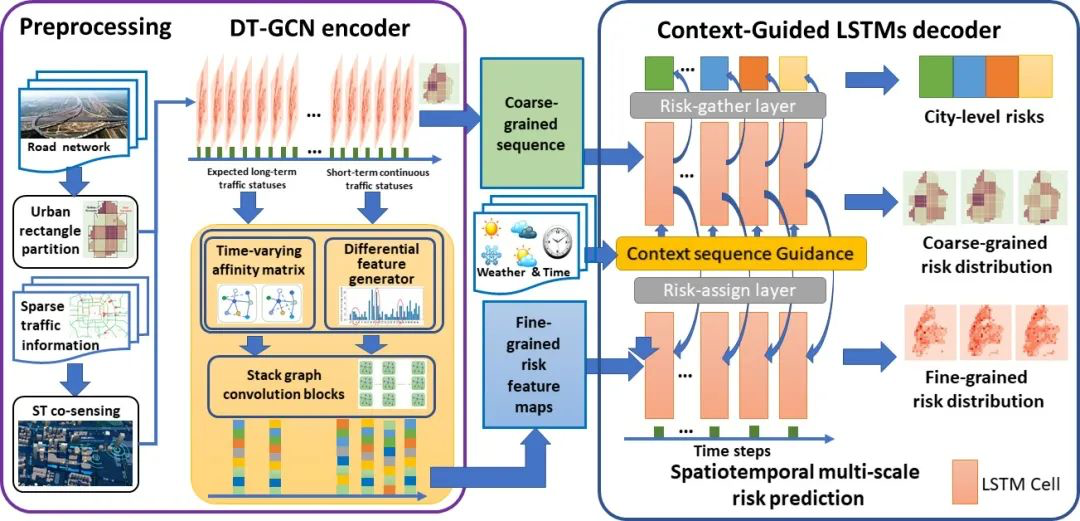
伪稀疏指的是数据本身存在,因为外界原因而未被感知或探测,如处处存在的交通流量、速度信息、天气信息,由于传感器布置的昂贵代价而不能采集到所有区域,该类数据可以通过捕获其时空模型进行数据增强和推断。
在缓解稀疏问题之后,团队设计了DT-GCN,通过捕获城市交通的短期变化来增强时间敏感的图表示,其设计受到了交通事故特点和事故相关的交通模式的启发;团队还设计了CG-LSTM,以实现多尺度和多时间步预测。
在两个真实数据集上的实验结果证明了团队所提出的包含DT-GCN和CG-LSTM集成结构的RiskSeq框架的优越性。并且,这也是第一项针对时空多粒度城市交通风险预测的工作。
来源:AI科技评论
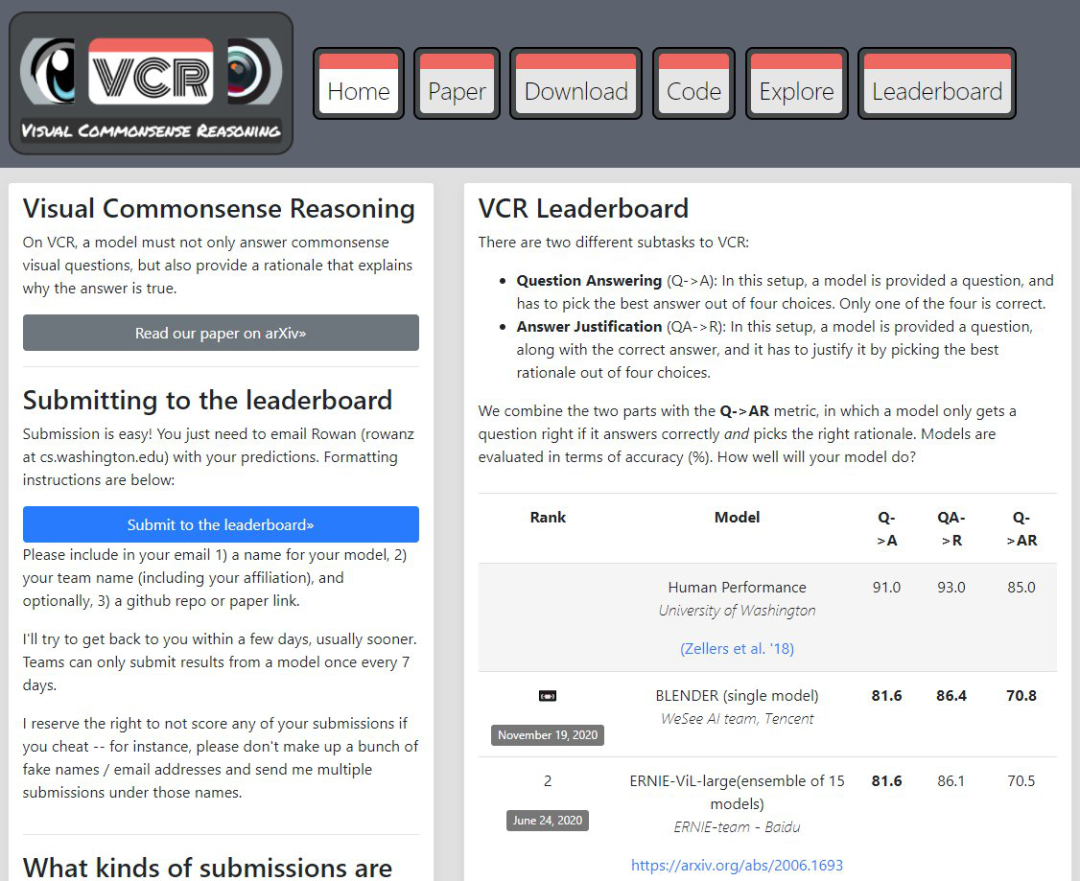
单模型史上最佳成绩,腾讯微视BLENDer模型登顶权威榜单VCR
2020 年 11 月 19 日,腾讯微视「BLENDer」模型凭借「81.6,86.4,70.8」的成绩,登上了多模态领域权威榜单 VCR 的榜首。这项最新成果来自腾讯微视视频理解团队。在这个之前,榜单的纪录保持者是百度、微软、Facebook 等知名机构。
BLENDer 基于当前主流的 one stream 的视觉语言 BERT 模型,该模型的学习过程分为三个阶段:
第一阶段在大约 150w 对图片及其描述的样本上进行预训练,采纳了 Masked Language Modeling (MLM), Masked Region Modeling (MRM)和 Image-Text Matching (ITM)三组预训练任务,如图所示。
第二阶段在 VCR 的训练集上进行进一步的预训练,继续采用第一阶段的 MLM 和 MRM 任务。
第三阶段进行最后的 finetune,输入 VCR 提供的 question, answer 和 rationale 以及 box feature,在[CLS] token 的输出进行 Q->A 和 QA->R 的二分类。以上所有阶段的 box feature 都采用的 BUTD 算法提取的 res-101 feature,除了 flip 没有采用其他增强手段。
相比以往的参赛模型,BLENDer 加入了人物物体关系推理、噪声对抗训练以及针对性更强的 MLM,最终,BLENDer 将三项问答准确率提高到了 81.6, 86.4, 70.8 的水平,单模型表现即超越此前单、多模型效果。
来源:机器之心
目标检测新范式:Sparse R-CNN,港大同济伯克利联合工作
目标检测领域中主流的两大类方法。第一大类是从非Deep时代就被广泛应用的dense detector,例如DPM,YOLO,RetinaNet,FCOS。
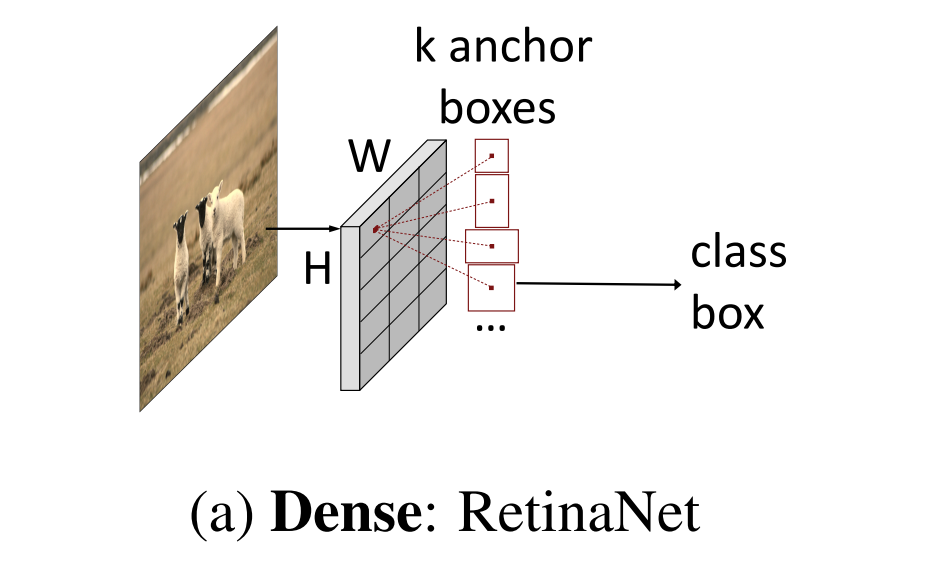
在Dense detector中, 大量的Object candidates例如sliding-windows,anchor-boxes, reference-points等被提前预设在图像网格或者特征图网格上,然后直接预测这些candidates到gt的scaling/offest和物体类别。第二大类是Dense-to-sparse detector,例如,R-CNN家族。

这类方法的特点是对一组sparse的candidates预测回归和分类,而这组sparse的candidates来自于dense detector。
这两类框架推动了整个领域的学术研究和工业应用。目标检测领域看似已经饱和,然而dense属性的一些固有局限总让人难以满意:
· NMS 后处理
· many-to-one 正负样本分配
· prior candidates的设计
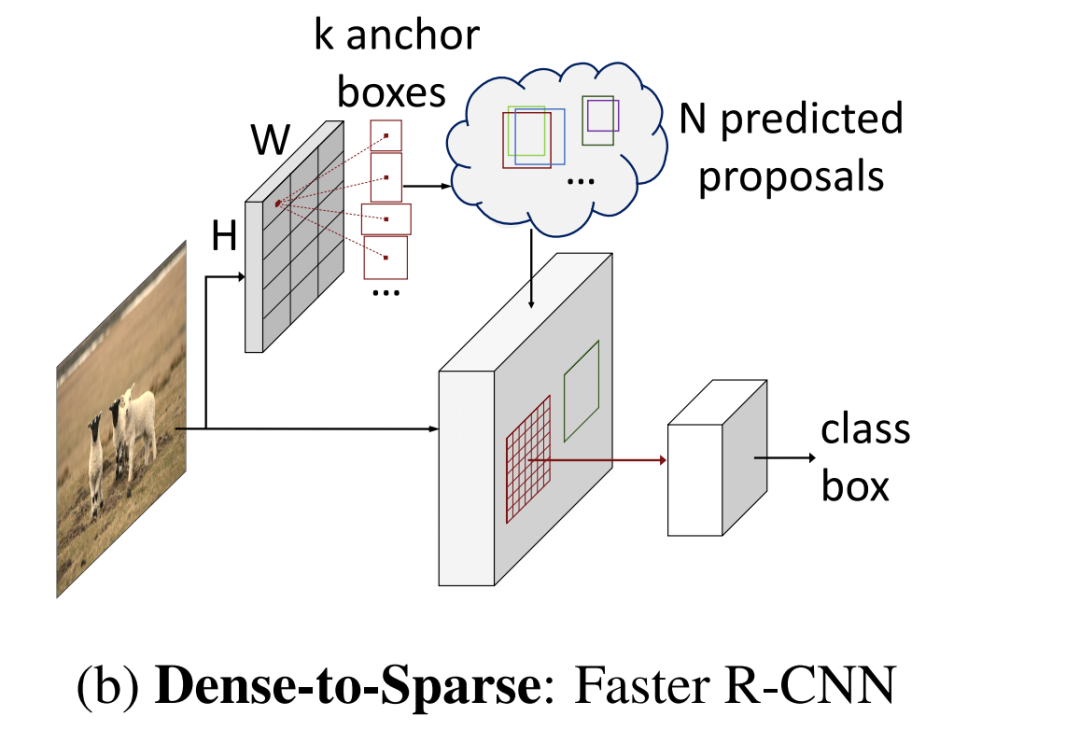
Sparse R-CNN抛弃了anchor boxes或者reference point等dense概念,直接从a sparse set of learnable proposals出发,没有NMS后处理,整个网络异常干净和简洁,可以看做是一个全新的检测范式。
来源:AI科技评论
突破AI和机器理解的界限,牛津CS博士143页毕业论文学习重建和分割3D物体
今年九月毕业于牛津大学计算机科学系的博士生 Bo Yang 在其毕业论文《Learning to Reconstruct and Segment 3D Objects》中对这一主题展开了研究。与传统方法不同,作者通过在大规模真实世界的三维数据上训练的深度神经网络来学习通用和鲁棒表示,进而理解场景以及场景中的物体。
总体而言,本文开发了一系列新型数据驱动算法,以实现机器感知到真实世界三维环境的目的。作者表示:「本文可以说是突破了人工智能和机器理解的界限。」
来源:机器之心
AI资讯
掌握最新时事新闻
长按扫码关注我们

原创文章,作者:整数智能,如若转载,请注明出处:https://www.agent-universe.cn/2020/11/8481.html