
MOLAR NEWS
2020年第39期
MolarData人工智能每周见闻分享,每周一更新。
上海交大发布 MedMNIST 医学图像分析数据集 & 新基准
医学图像分析是一个非常复杂的跨学科领域,近日上海交通大学发布了 MedMNIST 数据集,有望促进医学图像分析的发展。
MedMNIST 是一个包含 10 个医学公开数据集的集合,且全部数据均已经过预处理,将其分为包括训练集、验证集、测试子集的标准数据集。数据来源包括 X 射线、OCT、超声、CT 等不同成像模式,得到了同一病灶的多模态数据。与 MNIST 数据集一样,MedMNIST 可以在轻量级 28*28 图像上执行分类任务。
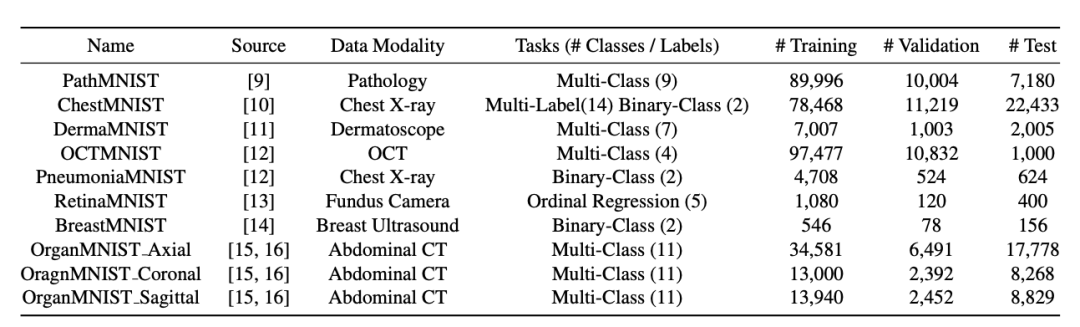

受《医学分割十项全能》(Medical Segmentation Decathlon)的启发,上海交通大学的科研人员还发布了《MedMNIST 分类十项全能》 (MedMNIST Classification Decathlon),作为医学图像分类中的轻量级 AutoML 基准。
来源:AI科技大本营
多语言互通:谷歌发布实体检索模型,涵盖超过100种语言和2000万个实体
谷歌最近提出了一个单一实体检索模型,该模型涵盖了100多种语言和2000万个实体,表面上表现优于有限的跨语言任务。

知识库本质上是包含实体信息的数据库,包括人、地点和事物等。2012年,谷歌推出了一个知识库的新概念:知识图谱,以提高搜索结果的质量。

这个知识库收集了来自 Wikipedia, Wikidata 和 CIA World Factbook 的数千亿事实。微软也曾推出一个知识库,其中有超过150,000篇文章是由为客户解决问题的支持专业人员创建的。谷歌的研究人员使用了所谓的增强型双编码器检索模型(enhanced dual encoder retrieval models )和 WikiData 作为他们的知识库,这些知识库包括大量不同的实体。

来源:新智元
谷歌发布Objectron数据集,推进三维物体几何理解的极限
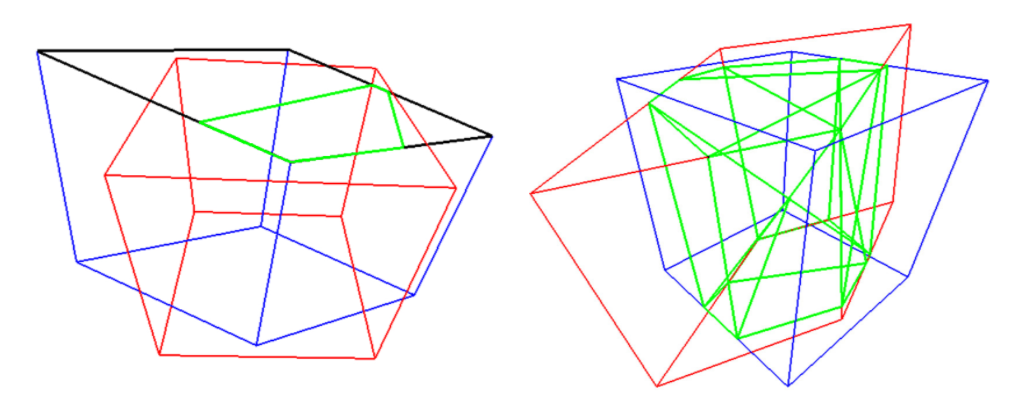
谷歌人工智能实验室近日发布 Objectron 数据集,这是一个以3D目标为中心的视频剪辑的集合,这些视频剪辑从不同角度捕获了较大的一组公共对象。数据集包括 15K 带注释的视频剪辑,并补充了从地理多样的样本中收集的超过 4M 带注释的图像
有了真实的注释,我们就可以使用 3D IoU(intersection over union)相似性统计来评估 3D 目标检测模型的性能,这是计算机视觉任务常用的指标,衡量bounding box与ground truth的接近程度。谷歌提出了一种计算一般的面向三维空间的精确 3D IoU 的算法。首先使用 Sutherland-Hodgman Polygon clipping 算法计算两个盒子面之间的交点,这类似于计算机图形学的剔除技术(frustum culling),利用所有截断多边形的凸包计算相交的体积。最后,通过交集的体积和两个盒子的并集的体积计算 IoU。谷歌表示将随数据集一起发布评估的源代码。
来源:新智元
忒修斯之船启发下的知识蒸馏新思路 | EMNLP 2020
基于 Transformer 的预训练模型也在自然语言理解和自然语言生成领域中成为主流。然而,这些模型所包含的参数量巨大,计算成本高昂,极大地阻碍了此类模型在生产环境中的应用。为了解决该问题,来自微软亚洲研究院自然语言计算组的研究员们提出了一种模型压缩的新思路。
受到著名哲学思想实验“忒修斯之船”的启发(即如果船上的木头逐渐被替换,直到所有的木头都不是原来的木头,那这艘船还是原来的那艘船吗?),研究员们在 EMNLP 2020 上发表了 Theseus Compression for BERT (BERT-of-Theseus),该方法逐步将 BERT 的原始模块替换成参数更少的替代模块。
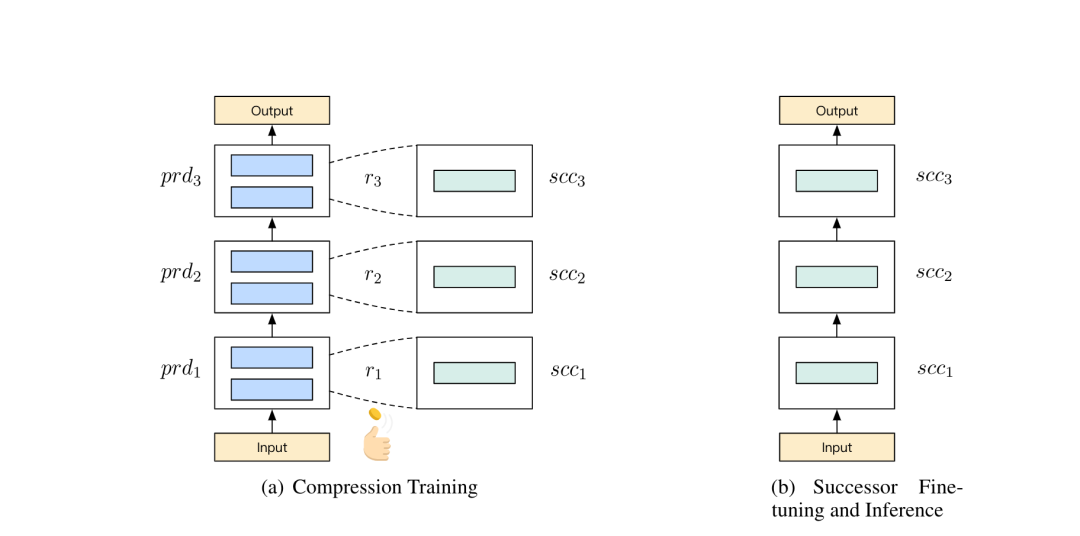
该方法的工作流程如下图所示。首先为每个前辈模块指定一个接替者模块,然后在训练阶段中以一定的概率(如抛硬币)决定是否用替代模块随机替换对应的前辈模块,并按照新旧模块组合的方式继续训练。
在模型收敛后,将所有接替者模块组合成接替者模型,进而执行推断。这样就可以将大型前辈模型压缩成紧凑的接替者模型了。
来源:新智元
Facebook AI指出:CNN的padding机制,存在一大缺陷
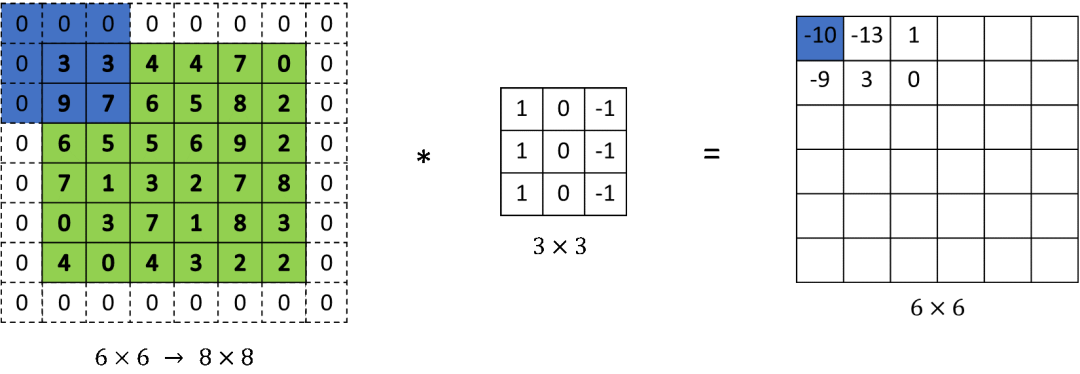
Facebook AI近期提出一项新研究,表明CNN中常用的padding机制存在重大缺陷,会导致特征图中出现伪影,从而影响CNN的应用。作者把这种伪影称为空间偏差,这种偏差对于某些任务特别是小目标检测是有害的,偏差会导致特征图上的伪影,而处于伪影中的物体无法被检测到,从而导致盲点或误检测。此外,该机制还会导致学习的权重出现不对称。为此,作者提出了减轻空间偏差的解决方案,实验结果表明这有助于提高模型的准确率。

来源:新智元
AI资讯
掌握最新时事新闻
长按扫码关注我们

原创文章,作者:整数智能,如若转载,请注明出处:https://www.agent-universe.cn/2020/11/8485.html