
MOLAR NEWS
2020年第47期
MolarData人工智能每周见闻分享,每周一更新。
清华、智源、协和联合开发乳腺癌AI诊断工具,可预测分子亚型,准确率高达76%
清华大学、北京智源人工智能研究院以及北京协和医院的研究团队进行合作,在2020年 6月份曾发布一项基于VGG模型,对超声影像进行良/恶性检测及分子亚型分类的深度神经网络模型SonoBreast,当时模型在乳腺癌分子分型上的准确率为56.3%,F1 Score为45.8%。研究团队经过数月对数据集预处理算法和训练模型的改进,根据近期公布结果,这一模型的分子分型准确率提升了近20个点,达到 76%;而在二分类问题上可以达到93%的准确率。
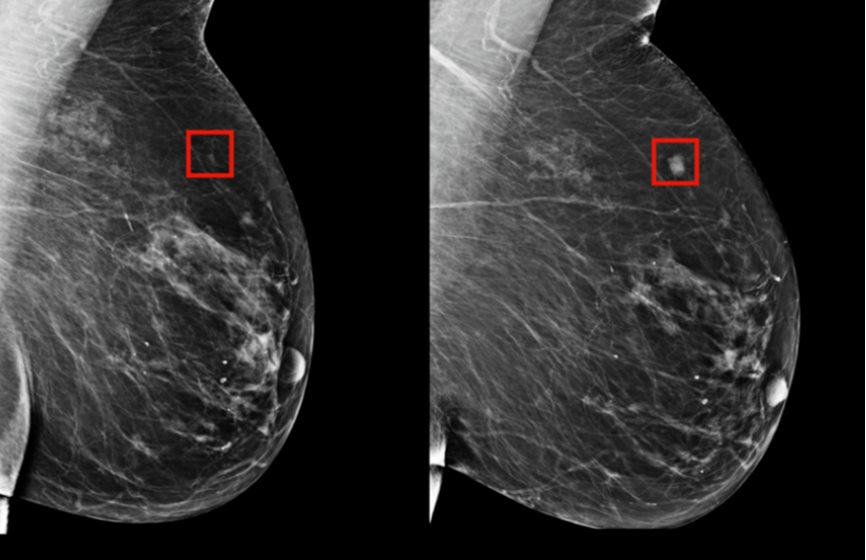

研究人员的数据主要来源于协和医院。在这次合作中,协和医院提供了750例乳腺癌病例,其中包括5000多张乳腺癌超声影像,并且对分子分型进行了标注。
与半年前的版本不同的是,最新版本的模型性能的提升很大程度上依赖于模型训练前期中对图像的处理。据毕明杰介绍,数据在输入到CNN模型之前,首先会使用一个被称为“自适应直方图均衡”的方法对特殊的图像进行变换,然后采用一个自主研发的切分算法对超声波图像中的不相关边界信息进行过滤和切除,这种边界的去除意义非常大,也是性能提升近 20%的关键点之一。
来源:AI科技评论
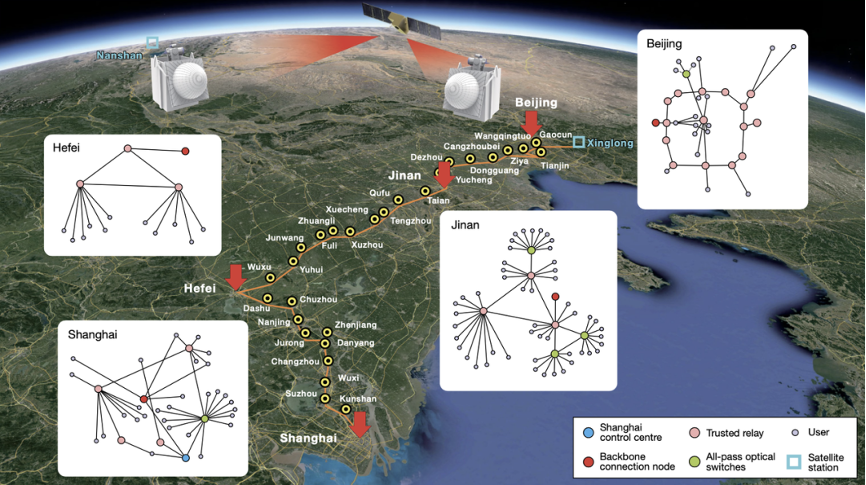
首次展现完整天地一体化广域量子通信网络,总长4600公里,实际应用已趋于成熟
1 月 6 日,潘建伟团队及其合作者又在量子通信方面推出了重磅成果,他们首次展现了一个完整的天地一体化量子通信网络,综合通信链路距离长达 4600 公里。
这项成果中展示的量子通信网络由 700 多个光纤量子密钥分发(QKD)链路和 2 个高速“卫星-地面”自由空间 QKD 链路组成。地面光纤网络采用可信中继结构,覆盖 2000 多公里,卫星对地面 QKD 的平均密钥传输速率达到每秒 47.8 kb,比之前提高了 40 倍以上,其信道损耗可与对地静止卫星和地面之间的信道损耗相比,从而使通过地球同步卫星构建更通用和超长的量子链路成为可能。
 来源:学术头条
来源:学术头条
药物重定位新框架,人工智能使「旧药新用」研究取得进展
俄亥俄州立大学的研究人员创建了一个框架,该框架将庞大的患者治疗相关的数据集与强大的计算功能相结合,从而得出经过重新调整用途的候选药物以及这些现有药物对一组预定结果的估计效果。
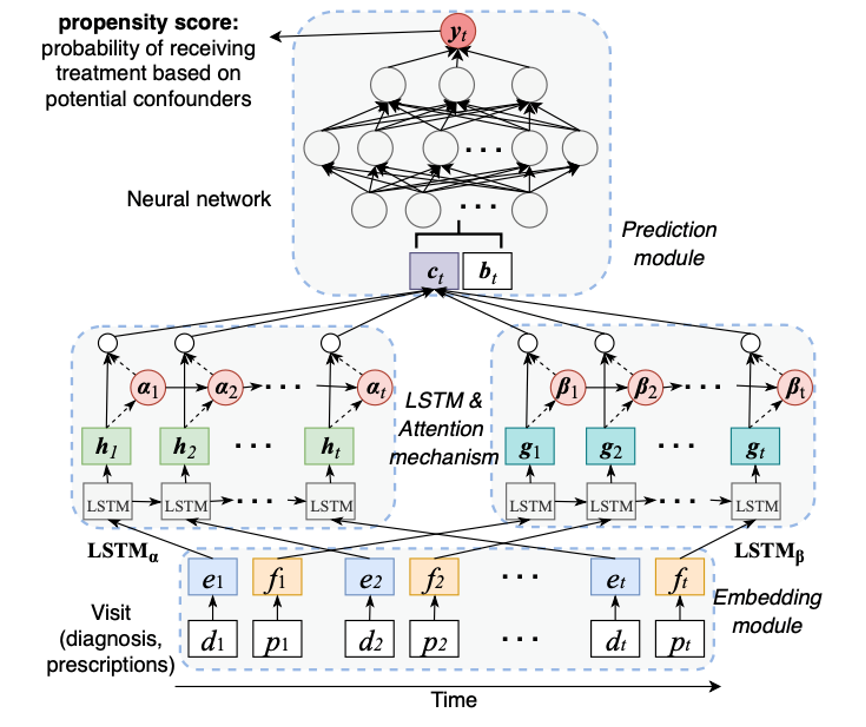
该研究小组使用了近 120 万心脏病患者的保险索赔数据,这些数据提供了有关他们被分配的治疗方法、治疗结果以及潜在干扰因素的各种价值的信息。深度学习算法还具有在每次就诊、处方和诊断测试中考虑每位患者经验中时间流逝的能力。药物的模型输入基于其有效成分。
该模型产生了九种被认为可以提供治疗的药物,其中三种目前正在使用中,这意味着该分析确定了六种重新定位的候选药物。除此之外,该分析还表明,用于治疗抑郁症和焦虑症的糖尿病药物——二甲双胍和依他普仑可以降低模型患者心衰或中风的风险。研究人员目前正在测试这两种药物对心脏病的功效。
来源:机器之心
Nature重磅:用“光”加速AI,基于光的并行卷积神经网络有望彻底“变革”AI硬件
过去几年来,光学频率梳(Optical Frequency Combs)的发展为集成光子处理器带来了新的机会。光学频率梳是一组光源,其发射光谱由数千或数百万条频率均匀且间隔紧密的清晰谱线组成。这些器件在光谱学、光学时钟计量和电信等领域取得了巨大的成功,其可以集成到计算机芯片中,并用作光学计算的高效能源,非常适合采用波分复用技术(WDM)进行数据并行处理。
研究人员成功研制了一个集成光子处理器,该处理器可以对跨越二维空间的光信号进行卷积处理。该设备在基于相变材料(一种可以在非晶相和晶相之间切换的材料)的“内存”计算架构中使用光学频率梳。
通过波长复用,该处理器可以对输入数据进行充分的并行化处理,并利用相变材料的集成单元阵列进行类似的矩阵矢量乘法运算。
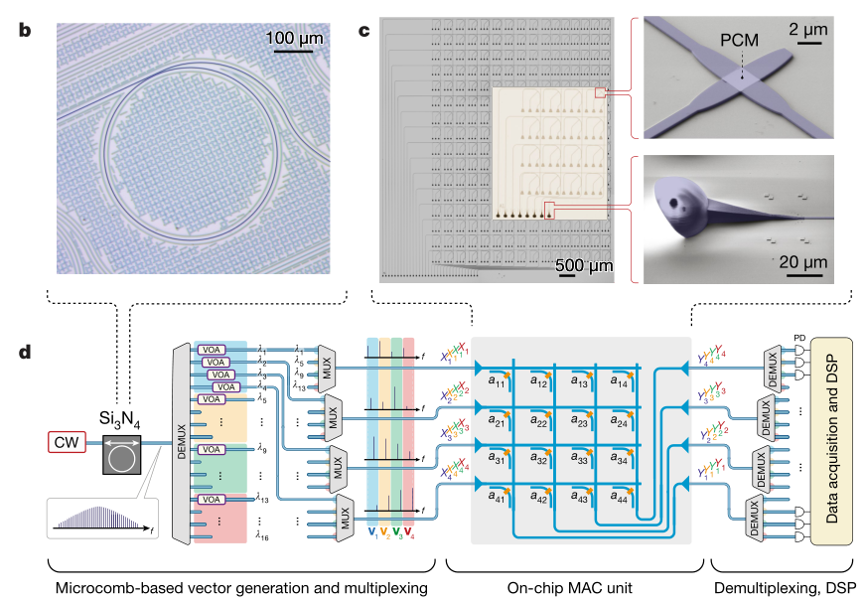
论文的第一作者之一 Johannes Feldmann 表示:“输入数据和一个或多个过滤器之间的卷积运算非常适合我们的矩阵体系结构。利用光进行信号传输使处理器能够通过波分多路复用执行并行数据处理,这保证了更高的计算密度,并且仅需一个时间步长就可以进行许多矩阵乘法。与通常在较低频率工作的传统电子设备相比,光调制速度可以达到 50-100GHz 范围。”
这种高度并行化的框架,有可能在单个步骤中高速处理整个图像。在不久的将来,该系统可以通过使用商业制造程序和辅助现场机器学习来进行大规模扩展。
来源:学术头条
怎样预训练GNN能实现更好的迁移效果?北邮等提出自监督预训练策略
图神经网络(GNN)已经成为图表示学习的实际标准,它通过递归地聚集图邻域的信息来获得有效的节点表示。尽管 GNN 可以从头开始训练,但近来一些研究表明:对 GNN 进行预训练以学习可用于下游任务的可迁移知识能够提升 SOTA 性能。但是,传统的 GNN 预训练方法遵循以下两个步骤:
-
1)在大量未标注数据上进行预训练;
-
2)在下游标注数据上进行模型微调。
近日,来自北京邮电大学和腾讯等机构的研究者进行了分析研究以显示预训练和微调之间的差异。为了缓解这种差异,研究者提出了 L2PGNN,这是一种针对 GNN 的自监督预训练策略。
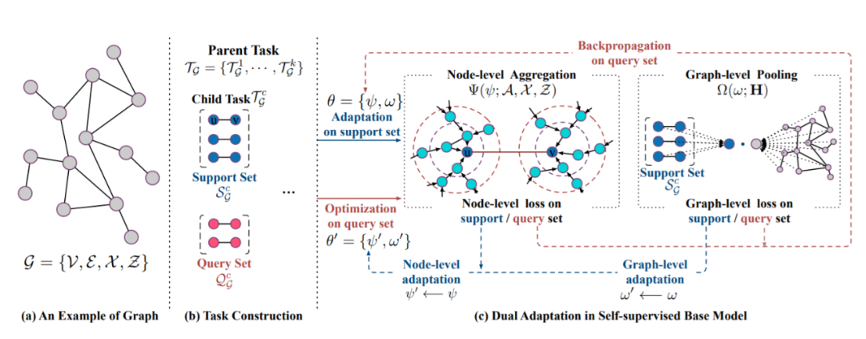
该方法的关键点是 L2P-GNN 试图学习在预训练过程中以可迁移先验知识的形式进行微调。为了将局部信息和全局信息都编码为先验信息,研究者进一步为 L2P-GNN 设计了在节点和图级别双重适应(dual adaptation)的机制。最后研究者使用蛋白质图公开集合和书目图的新汇编进行预训练,对各种 GNN 模型的预训练进行了系统的实证研究。实验结果表明,L2P-GNN 能够学习有效且可迁移的先验知识,从而为下游任务提供强大的表示。
来源:机器之心
AI资讯
掌握最新时事新闻
长按扫码关注我们

原创文章,作者:整数智能,如若转载,请注明出处:https://www.agent-universe.cn/2021/01/8469.html