
MOLAR NEWS
2020年第52期
MolarData人工智能每周见闻分享,每周一更新。
国科大、北方电子设备研究所联合提出首个多模态无人机跟踪数据集
近日,中国科学院大学视觉实验室和北方电子设备研究所的一项联合研究工作取得了新进展。该项研究致力于基于机器视觉与多模态互感技术实时监控无人机空间位置和运动轨迹等信息,并首次提出了「反无人机」这一研究课题,同时,为推动领域进展,还发布了首个 Anti-UAV 多模态数据集——研究人员使用多种目前市面上常见的商用小型无人机型,采集并标注了超过 300 段可见光 / 红外视频对(含超过 58 万个目标),涵盖白昼、黑夜条件下云层、楼宇、丛林等复杂背景及飞鸟、空飘物等虚假目标带来的挑战。

 此外,研究人员还针对「反无人机」问题提出了一种有效的基线方法——复杂环境下多模态小目标跟踪 DFSC 算法,并与超过 40 种的 State-of-the-Art tracker 算法模型进行了测试对比,结果表明,所提出的 DFSC 算法在该问题上取得了目前最优的性能表现。
此外,研究人员还针对「反无人机」问题提出了一种有效的基线方法——复杂环境下多模态小目标跟踪 DFSC 算法,并与超过 40 种的 State-of-the-Art tracker 算法模型进行了测试对比,结果表明,所提出的 DFSC 算法在该问题上取得了目前最优的性能表现。
在数据归一化之后,数据被「拍扁」到统一的区间内,输出范围被缩小至 0 到 1 之间。人们通常认为经过如此的操作,最优解的寻找过程明显会变得平缓,模型更容易正确的收敛到最佳水平。
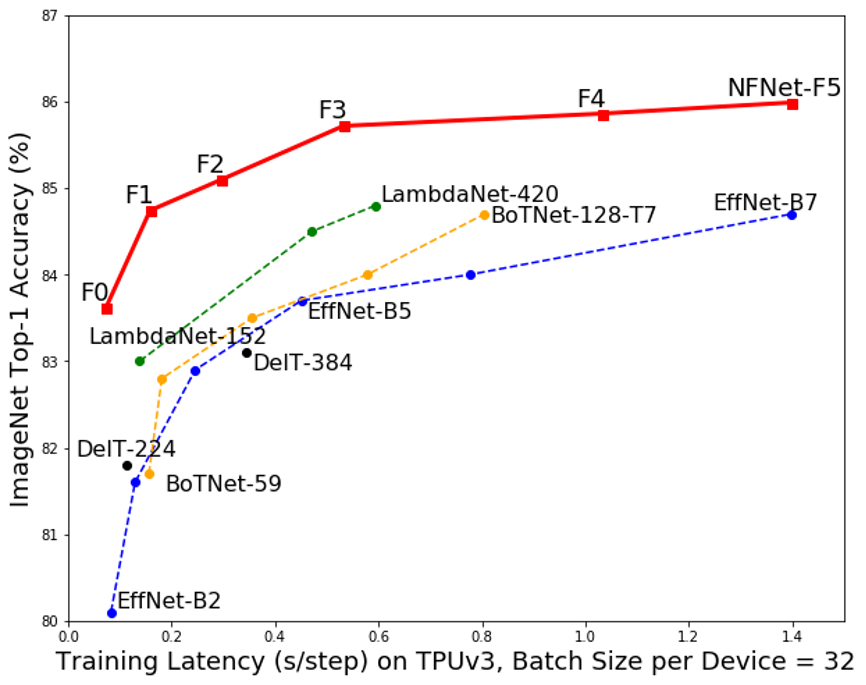
然而这样的「刻板印象」最近受到了挑战,DeepMind 的研究人员提出了一种不需要归一化的深度学习模型 NFNet,其在大型图像分类任务上却又实现了业内最佳水平(SOTA)。
该论文的第一作者,DeepMind 研究科学家 Andrew Brock 表示:「我们专注于开发可快速训练的高性能体系架构,已经展示了一种简单的技术(自适应梯度裁剪,AGC),让我们可以训练大批量和大规模数据增强后的训练,同时达到 SOTA 水平。」
NFNet 是不做归一化的 ResNet 网络。具体而言,该研究贡献有以下几点:
-
提出了自适应梯度修剪(Adaptive Gradient Clipping,AGC)方法,基于梯度范数与参数范数的单位比例来剪切梯度,研究人员证明了 AGC 可以训练更大批次和大规模数据增强的非归一化网络。
-
设计出了被称为 Normalizer-Free ResNets 的新网络,该方法在 ImageNet 验证集上大范围训练等待时间上都获得了最高水平。NFNet-F1 模型达到了与 EfficientNet-B7 相似的准确率,同时训练速度提高了 8.7 倍,而 NFNet 模型的最大版本则树立了全新的 SOTA 水平,无需额外数据即达到了 86.5%的 top-1 准确率。
-
如果在对 3 亿张带有标签的大型私人数据集进行预训练,随后针对 ImageNet 进行微调,NFNet 可以比批归一化的模型获得更高的 Top-1 准确率:高达 89.2%。
来源:机器之心
一个不认识牛顿的AI,绕开所有物理定律,从数据到数据就能预测行星轨道!
「在物理学中,通常你会进行观测,根据观测结果创建一个理论,然后用这个理论来预测新的观测结果,」秦宏说,「我所做的是用一种黑匣子来代替这个过程,它可以在不使用传统理论或规律的情况下产生准确的预测。」
 这个黑盒过程也出现在哲学思想实验中,比如John Searle提出著名的中文屋(Chinese Room)思想实验。
这个黑盒过程也出现在哲学思想实验中,比如John Searle提出著名的中文屋(Chinese Room)思想实验。
在实验中,一个不懂中文的人却可以通过使用一套指令或规则,将一个中文句子翻译成英文或任何其他语言,从而代替理解。
 这个思想实验认为任何机器都不可能理解人类语言的真正含义,否决了图灵测试的有效性。即使计算机通过图灵测试,也不算真正具有智能。
这个思想实验认为任何机器都不可能理解人类语言的真正含义,否决了图灵测试的有效性。即使计算机通过图灵测试,也不算真正具有智能。
秦宏的灵感部分来自于牛津大学哲学家Nick Bostrom的哲学思想实验,即宇宙是一个计算机模拟程序。
来源:新智元
更精准地生成字幕!哥大&Facebook开发AI新框架,多模态融合,性能更强
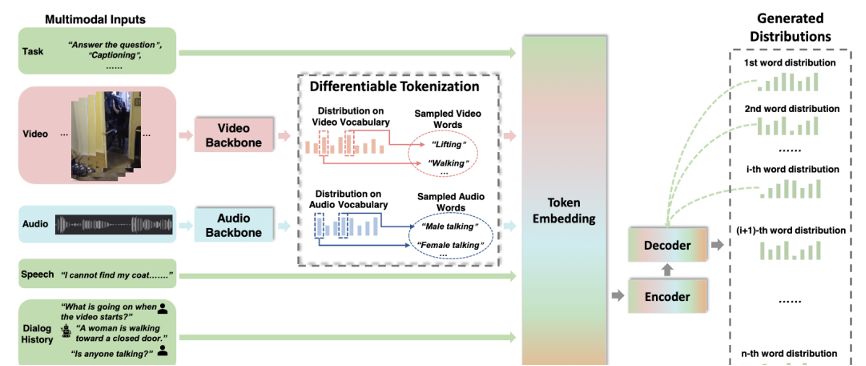
Vx2Text是从多模态输入(由视频、文本、语音或音频组成)中提取信息,再以人类可以理解的方式,生成自然语言文本(例如:字幕、回答问题等)。
研究团队通过引入大型基准,来评估Vx2Text解释信息和生成自然语言的能力。
这些基准主要包括:用于图像或视频字幕、问答(QA)和视听对话的数据集。
为了在这些基准测试中表现出色,Vx2Text必须完成几个目标:
-
从每个模态中提取重要信息;
-
有效地组合不同线索,以解决给定的问题;
-
以可理解的文本形式,将结果生成和呈现出来。
并且,将这些目标嵌入一个统一的、端到端的可训练的框架中。
整个过程可以分为三步:
-
多模态输入及识别;
-
将不同模态嵌入同一语言空间;
-
融合多模态信息。
来源:机器之心
AI资讯
掌握最新时事新闻
长按扫码关注我们

原创文章,作者:整数智能,如若转载,请注明出处:https://www.agent-universe.cn/2021/02/8459.html