


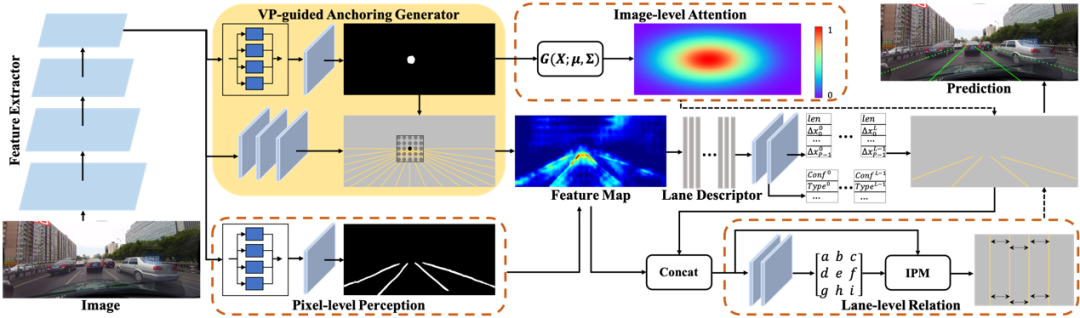
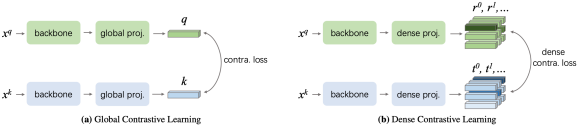
具体而言,该方法去掉了已有的自监督学习框架中的全局池化层,并将其全局映射层替换为密集映射层实现。在匹配策略的选择上,研究者发现最大相似匹配和随机相似匹配对最后的精度影响非常小。与基准方法 MoCo-v2[1] 相比,DenseCL 引入了可忽略的计算开销(仅慢了不到 1%),但在迁移至下游密集任务(如目标检测、语义分割)时,表现出了十分优异的性能。DenseCL 的总体损失函数如下:
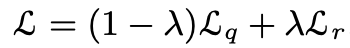

END






原创文章,作者:整数智能,如若转载,请注明出处:https://www.agent-universe.cn/2021/05/8441.html