


MOLAR FRESH 2021年第12期
人工智能新鲜趣闻 每周一 更新
2021年机器学习什么风向?谷歌大神Quoc Le:把注意力放在MLP上
MLP→CNN→Transformer→MLP 似乎已经成为一种大势。最近一段时间,多层感知机 MLP 成为 CV 领域的重点研究对象。谷歌大脑首席科学家、AutoML 鼻祖 Quoc Le 团队提出了一种仅基于空间门控 MLP 的无注意力网络架构 gMLP,并展示了该架构在一些重要的语言和视觉应用中可以媲美 Transformer。
研究者将 gMLP 用于图像分类任务,并在 ImageNet 数据集上取得了非常不错的结果。在类似的训练设置下,gMLP 实现了与 DeiT(一种改进了正则化的 ViT 模型)相当的性能。不仅如此,在参数减少 66% 的情况下,gMLP 的准确率比 MLP-Mixer 高出 3%。
他们还将 gMLP 应用于 BERT 的掩码语言建模(MLM)任务,发现 gMLP 在预训练阶段最小化困惑度的效果与 Transformer 一样好。

该研究的实验表明,困惑度仅与模型的容量有关,对注意力的存在并不敏感。随着容量的增加,研究者观察到,gMLP 的预训练和微调表现的提升与 Transformer 一样快。随着数据和算力的增加,gMLP 等具有简单空间交互机制的模型具备媲美 Transformer 的强大性能,并且可以移除自注意力或大幅减弱它的作用。不过,对于这项研究中提出的基于空间门控单元的 gMLP 架构,有网友质疑:「gMLP 的整体架构难道不是更类似于 transformer 而不是原始 MLP 吗?」
(来源:深度学习技术前沿)
无监督学习站起来了!Facebook第三代语音识别wav2vec-U,匹敌监督模型,Lecun看了都说好
Facebook开发了一个全新的语音识别系统,wav2vec Unsupervised (wav2vec-U) ,这是一种完全不需要转录数据的语音识别系统的方法。wav2vec-U已经成功在斯瓦希里语、塔塔尔语等多种小众语言上进行测试,因为缺乏大量的标记训练数据,这些语言目前还没有高质量的语音识别模型。
与之前的 ASR 系统相比,Wav2vec-U的框架采用了一种新颖的方法: 该方法首先从未标记的音频中学习语音的结构。
使用自监督模型 wav2vec 2.0和一个简单的 K平均算法方法,能够将录音分割成与单个声音松散对应的语音单元。(例如,单词 cat 包括三个发音: “/k/”、“/AE/”和“/t/”。)
wav2vec-U 在 TIMIT 基准上对它进行了评估,与第二好的无监督方法相比,它将错误率降低了57% 。
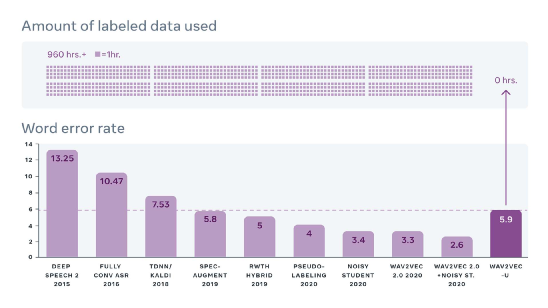
除此之外,研究人员还对将 wav2vec-U 与 Librispeech 基准上的监督模型进行性能对比。
在没有标注数据的情况下, wav2vec-U 与几年前的最新技术一样准确。这表明语音识别系统在没有监督的情况下可以达到很好的质量。
(来源:新智元)
7秒钟的记忆?Facebook提出DL新算法
当前的AI机制过去常常选择性地专注于其输入的某些部分,因此会减慢其处理新信息和执行其设计任务的能力,会导致更高的计算成本。
近日,Facebook的研究人员提出一种深度学习算法:Expire-Span。教深度学习模型如何以及何时大规模地忘记某些细节。
研究人员为神经网络提供时间序列,例如单词、图像或视频帧。每次显示新信息时,Expire-Span会针对每种隐藏状态计算信息的过期值,并确定该信息作为内存保存的时间。

Expire-Span根据从数据中获悉并受其周围存储器影响的上下文来计算预测。例如,如果模型正在训练以执行单词预测任务,则可以教AI记住诸如名称之类的稀有单词,而忘记诸如and的非常常见的填充词。Facebook表示,Expire-Span在跨语言建模,强化学习,对象碰撞和算法任务的多个不同的长上下文任务中提高了AI的效率。
(来源:新智元)
类脑科学:帮助人工智能走得更远
清华大学精密仪器系教授、类脑计算中心主任施路平表示:“作为一种借鉴人脑存储处理信息方式发展起来的新技术,类脑计算将是人工通用智能的基石。”
类脑计算芯片是一项新兴技术,是借鉴人脑处理信息的基本原理,面向类脑智能而发展的新型信息处理芯片。按数据表达分类,目前类脑计算芯片架构分为数字型架构、模拟型架构和数模混合型架构。
利用超大规模集成电路来实现神经网络模型,用于构建类脑的感知和计算系统,是由 Carver A. Mead 等人在20世纪80年代末提出的。现有主流方案代表有:英国曼彻斯特大学的 SpiNNaker 是程序级的代表,IBM的TrueNorth、Intel的 Loihi和清华大学的Tianjic是架构级的代表,德国海德堡大学的BrainScaleS 是电路级的代表,美国斯坦福大学的 Neurogrid 是器件工作状态级的代表。
学习大脑的信息处理机制,建立更强大和更通用的机器智能是非常有前景的。通过多学科交叉和实验研究获得的人脑工作机制更具可靠性,有望为人工智能未来发展提供基础。
(来源:数据实战派)
AttendSeg:一个新的深度学习模型,将图像分割带到边缘设备
DarwinAI 和滑铁卢大学的科学家们已经成功地创建了一个神经网络,它提供了图像分割的近乎最优解,并且足够小,适合资源有限的设备。
AttendSeg 深度学习模型执行语义分割的精确度几乎与 RefineNet 相当,同时将参数数量减少到 119 万个。有趣的是,研究人员还发现,将参数的精度从 32 位(4 字节)降低到 8 位(1 字节)不会导致显著的性能损失,同时使他们能够将 AttendSeg 的内存占用空间缩小四倍。该模型需要的内存仅略高于 1 兆字节,这足以适合大多数边缘设备。
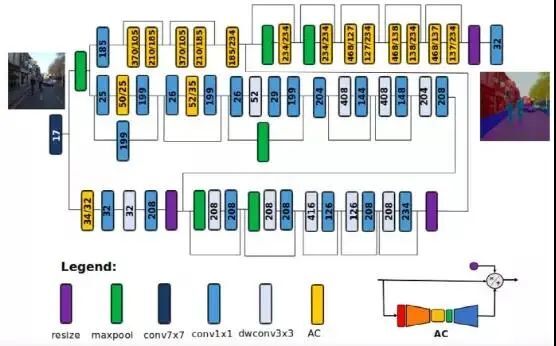
AttendSeg 利用 “注意力冷凝器”(Attention condensers)来缩小模型尺寸而不影响性能。注意力冷凝器使深度神经网络架构非常紧凑,但仍然可以实现高性能,这使得它们非常适合边缘设备或微型机器学习模型应用。
DarwinAI 联合创始人、滑铁卢大学副教授 Alexander Wong 说:“从本质上讲,与先前提出的网络相比,AttendSeg 神经网络能在大多数边缘硬件上快速运行。但是,如果要生成针对特定硬件量身定制的 AttendSeg,则可以使用机器驱动的设计探索方法为其创建一个新的高度定制化的神经网络。”
(来源:学术头条)
END






掌握AI咨询
了解更多科技趣闻
长按扫码 关注我们
原创文章,作者:整数智能,如若转载,请注明出处:https://www.agent-universe.cn/2021/05/8560.html