

关于首个大规模桌面物体数据集TO_Scene,从产品设计逻辑到团队背景,你想知道的一切都在这里,或许能帮助你正在进行的算法训练,提高模型3D语义分割和对象检测任务质量。
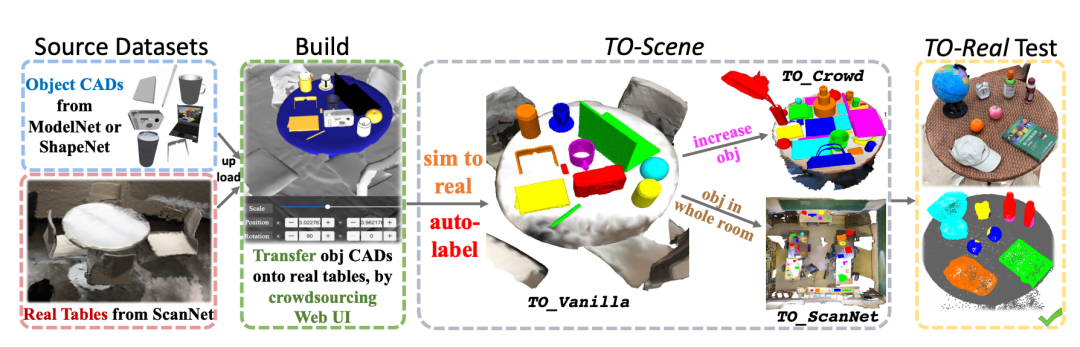
注:TO_Scene数据集概览

注:方便标注员放置模型的交互界面

注:两组合成的数据集TO_Vanilla及TO_Crowd
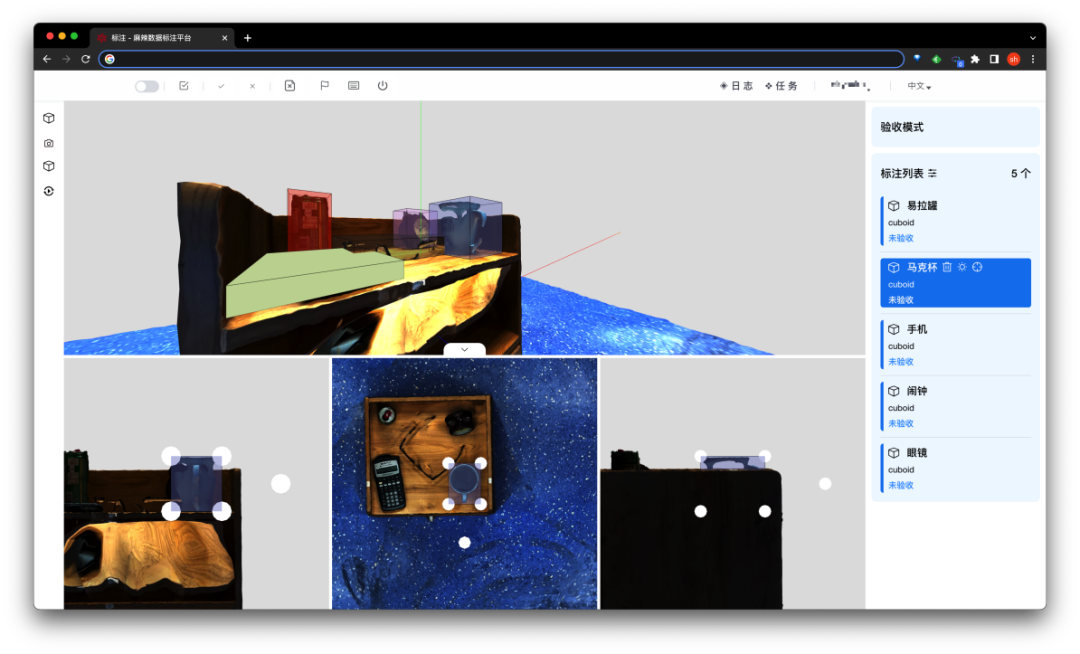
注:整数智能为TO_Real提供专业的数据标注服务
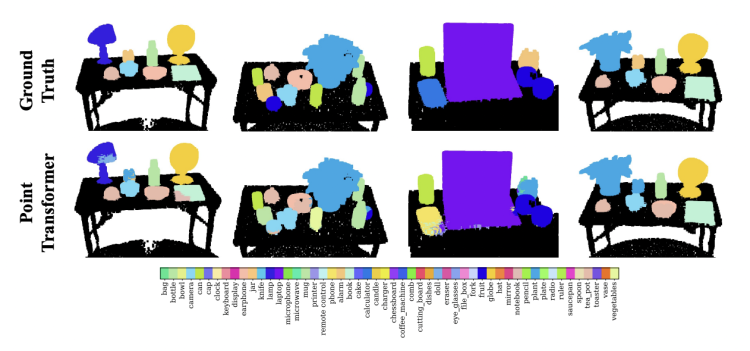
注:TO_Real上的3D语义分割测试结果

关于首个大规模桌面物体数据集TO_Scene,从产品设计逻辑到团队背景,你想知道的一切都在这里,或许能帮助你正在进行的算法训练,提高模型3D语义分割和对象检测任务质量。
注:TO_Scene数据集概览
注:方便标注员放置模型的交互界面
注:两组合成的数据集TO_Vanilla及TO_Crowd
注:整数智能为TO_Real提供专业的数据标注服务
注:TO_Real上的3D语义分割测试结果
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。 「奇绩大模型日报」知识库现已登陆飞书官方社区: https://www.feishu.…
Gamma是AIPPT断档式的存在,为了更深度的理解这款最强产品,我特别约了即刻@余一 聊了两次,和她专门也录了一期播客,比如这句话其实点出了Gamma并不是AIPPT的关键: A…
Z Talk 是真格分享认知的栏目。 潞晨科技创始人尤洋是加州大学伯克利分校博士,曾被 UC Berkeley 提名为 ACM Doctoral Dissertation Awar…
更多被投新闻 依图科技 | Momenta | Nuro | 云天励飞 禾赛科技 | 晶泰科技&nb…
“上课用AI生成思维导图,下课找AI学伴答疑,写论文靠AI速读文献,连选修课表都是AI帮我排的!” 最近,浙江大学自主研发的“大先生”智能体(基于DeepSeek大模型)火出圈了。…
封面由 DeepSeek 给的文字版灵感,由抽象画手特工小宝制作 内容编辑丨特工少女 特工小天 模型测评丨特工小宝 特工小嘉 在那个年味虽然不浓但班味十足的除夕,我们依然“天涯共此…
David Pierce站在街头,胸前别着一枚精致的小装置——AI Pin,这是一款被设计来解放双手、提升生活效率的革命性产品。在他的想象中,这款设备将成为他日常生活的智能伙伴。 …
米哈游大伟哥在一条朋友圈下面评论,「我就在这里暴言一句,过去五年中国游戏行业最强投资人:Daniel,没有之一。」 发这条朋友圈的人叫吴旦(Daniel),他是第一个投资《黑神话:…
MOLAR NEWS 2021年第7期 MolarData人工智能每周见闻分享,每周一更新。 270亿参数、刷榜CLUE,阿里达摩院发布最大中文预训练语言模型PLUG 4 月 …