
如文章太长,ChatGPT没法阅读?
拆分太累,写论文效率大打折扣?
接昨天发的一篇文章《赶紧拿下写论文必备ChatGPT Prompts拆分神器!》
再给大家分享一个工具,叫ChatGPT Splitter,它可以直接对代码文件进行分析!


ChatGPT Splitter顾名思义,仍然是Prompts拆分神器,但不同的是,该工具可以支持上传多个文件并自动将它们分成多个块,当然,也可以直接将文本将这些块加载到 ChatGPT。

可以支持上传的文件格式,包含代码、PDF、图像、docx,并点击处理,然后按照生成的部分,复制每个块并将其提供给 ChatGPT。
完成后,ChatGPT 将了解你所提供文档或内容的上下文,你便可以在后续提示中使用它!
这个是它提供的示范Prompts,和之前的工具提示非常相似:
Act like a document/text loader until you load and remember content of the next text/s or document/s.
There might be multiple files, each file is marked by name in the format ### DOCUMENT NAME.
I will send you them by chunks. Each chunk start will be noted as [START CHUNK x/TOTAL],
and end of this chunk will be noted as [END CHUNK x/TOTAL],
where x is number of current chunk and TOTAL is number of all chunks I will send you.
I will send you multiple messages with chunks, for each message just reply OK: [CHUNK x/TOTAL], don’t reply anything else, don’t explain the text!
Let’s begin:
能否处理大量代码?
我们直接尝试从Kaggle里取一段建模比赛代码,这是由Google发起的孤立的手语识别模型比赛。
该比赛的目标是对孤立的美国手语 (ASL) 标志进行分类,帮助失聪儿童的亲属学习基本手语并更好地与他们所爱的人沟通。 通过创建一个 TensorFlow Lite 模型,并使用 MediaPipe 整体解决方案提取的标记地标数据进行训练。

然后,我们取其中一位作者的代码,截取部分,并将其加载如下:

…

…

…


同样它将代码分成了8个块,并对每一个块提供相应的Prompts:

…
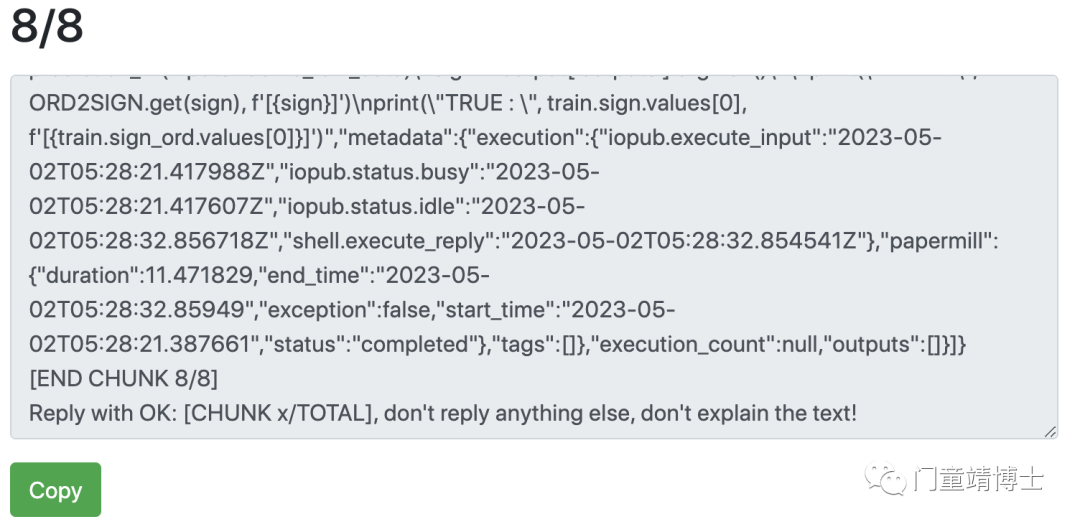
将其中第一个文字块输入至ChatGPT,It works!
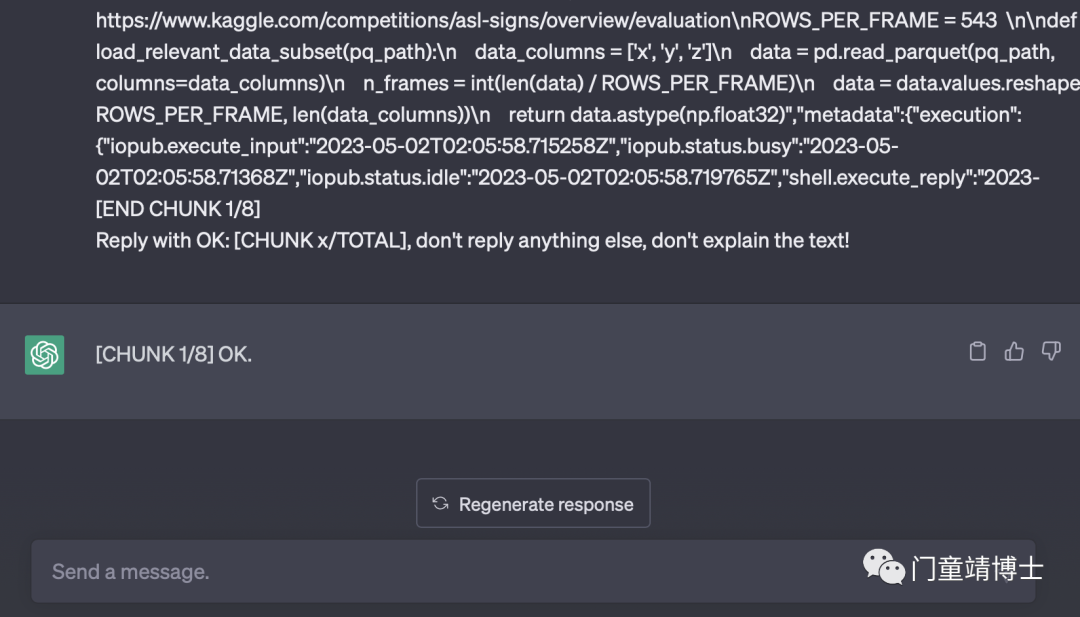
同理,将剩余的代码块输入,直至全部完成!
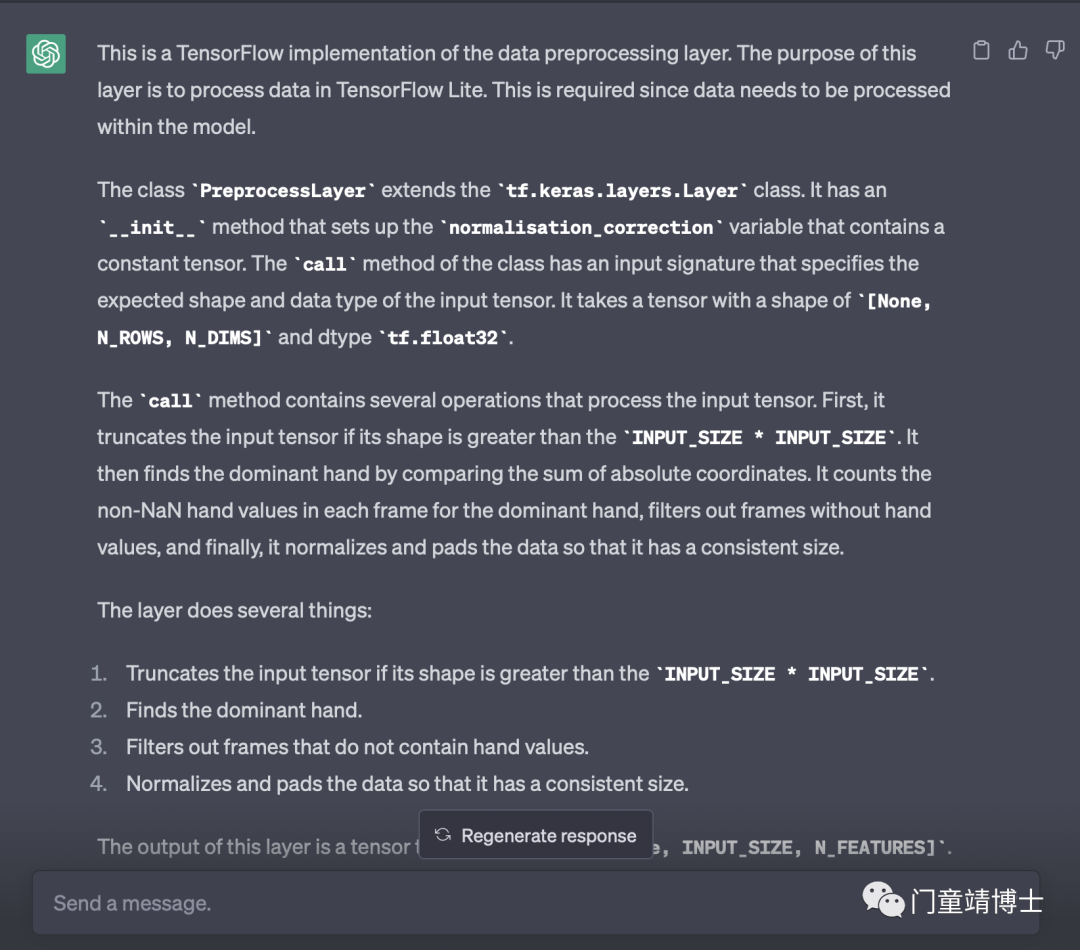
然后,询问ChatGPT代码的含义,它的回答如下:
(以下是针对1/8块的代码所进行的解释,主要做的工作是数据预处理)
这是数据预处理层的 TensorFlow 实现。该层的目的是处理 TensorFlow Lite 中的数据。这是必需的,因为需要在模型中处理数据。
PreprocessLayer 类扩展了 tf.keras.layers.Layer 类。它有一个 __init__ 方法来设置包含常量张量的 normalisation_correction 变量。类的调用方法有一个输入签名,指定输入张量的预期形状和数据类型。它采用形状为 [None, N_ROWS, N_DIMS] 和 dtype tf.float32 的张量。
call 方法包含几个处理输入张量的操作。首先,如果输入张量的形状大于 INPUT_SIZE * INPUT_SIZE,它会截断输入张量。然后,它通过比较绝对坐标之和来找到惯用手。它计算优势手在每个帧中的非 NaN 手值,过滤掉没有手值的帧,最后,它对数据进行归一化和填充,使其具有一致的大小。
该层做了几件事:
1. 如果输入张量的形状大于 INPUT_SIZE * INPUT_SIZE,则截断输入张量。
2. 找到优势手。
3. 过滤掉不包含手牌值的帧。
4. 规范化和填充数据,使其具有一致的大小。
该层的输出是一个形状为 [None, INPUT_SIZE, N_FEATURES] 的张量。None 维度表示批量大小,不固定。INPUT_SIZE 维度是固定的,表示已处理视频中的帧数。N_FEATURES 维度也是固定的,表示已处理视频中的特征数。
总体而言,该层对输入数据进行预处理,以便将其用作 TensorFlow Lite 模型的输入。
大功告成!
至于其他文件格式,如PDF, Word等大家可以自行尝试一下,基本过程其实就是将文件内容转化成文本,再将文本分块进行处理。
大概总结几点如下:
1. 优势就是可以直接处理文件,对代码文件可以直接进行拆分;
2. 文本操作和ChatGPT Prompts Splitter 基本一样,文本的话,我个人还是喜欢用《赶紧拿下写论文必备ChatGPT Prompts拆分神器!》
3. 该工具非开源,也没有API可供应用开发;
对于Prompts Splitter, 亦有嵌入浏览器的工具,比如下面这个,所以,大家也可以自行尝试,哪一种方式更适合自己平日的工作。
HAVE FUN!

参考文献:
[1] https://chatgptsplitter.com/
[2] https://www.kaggle.com/code/cdeotte/improve-best-public-notebook-lb-0-76
[3] https://chrome.google.com/webstore/detail/split-long-text-for-chat/ninfbacppokhhaekjbgfhemhmlalfmmn
原创文章,作者:门童靖博士,如若转载,请注明出处:https://www.agent-universe.cn/2023/05/11691.html