
机器学习的基本原理,看这一张图就够了!刚在linkedin上看到一张不错的gif图,这里分享给大家。
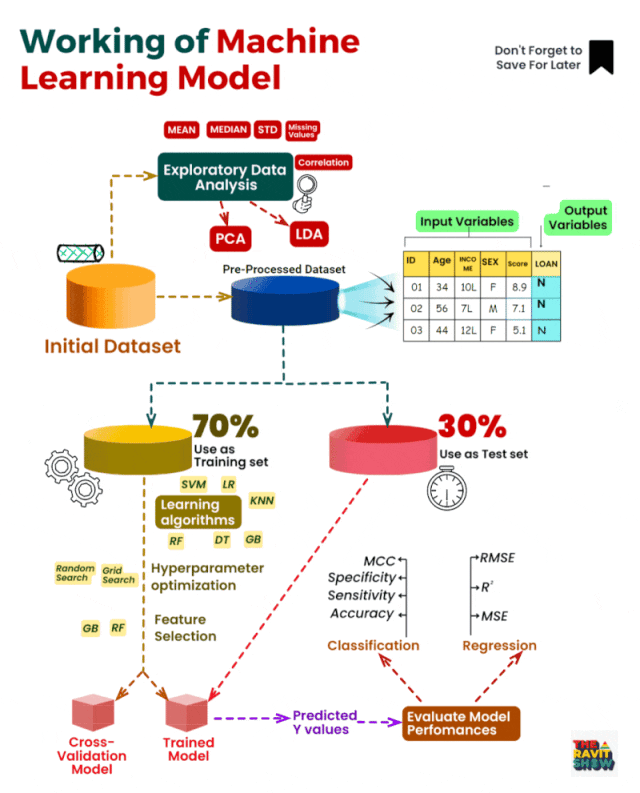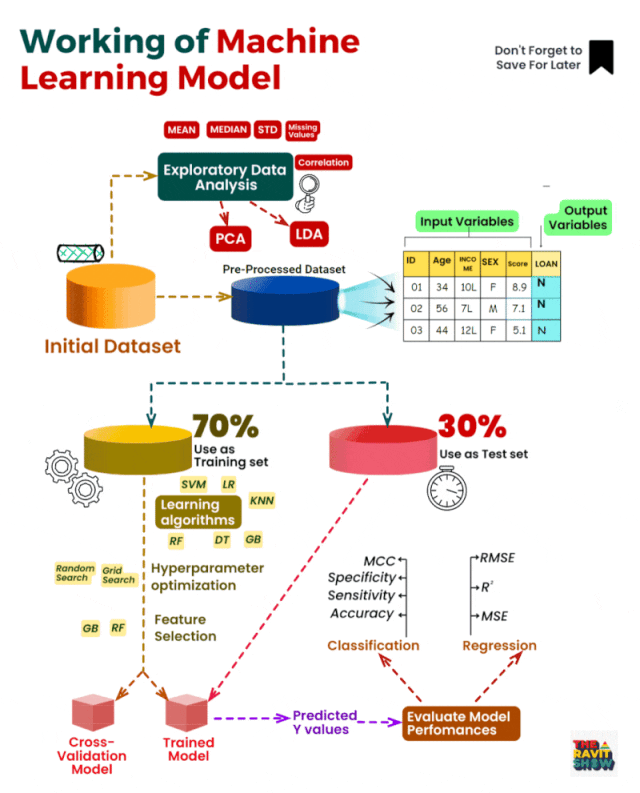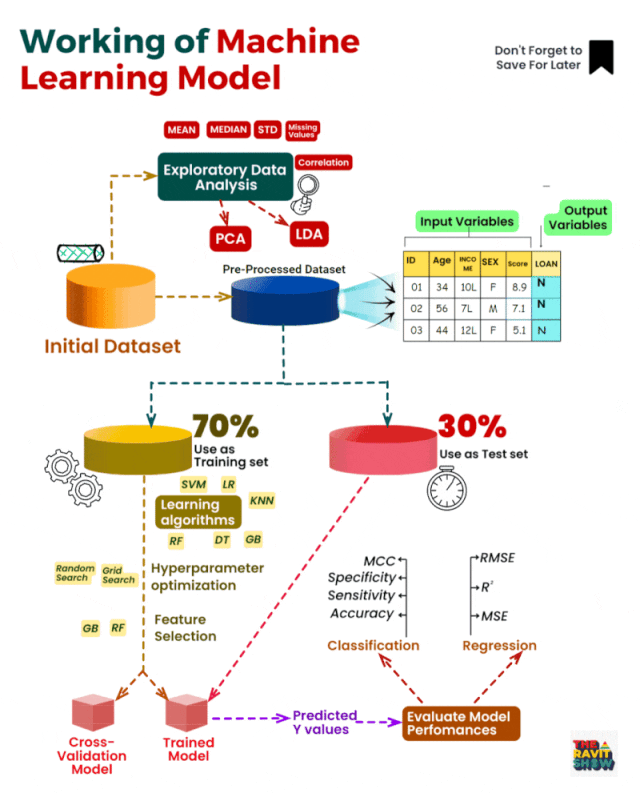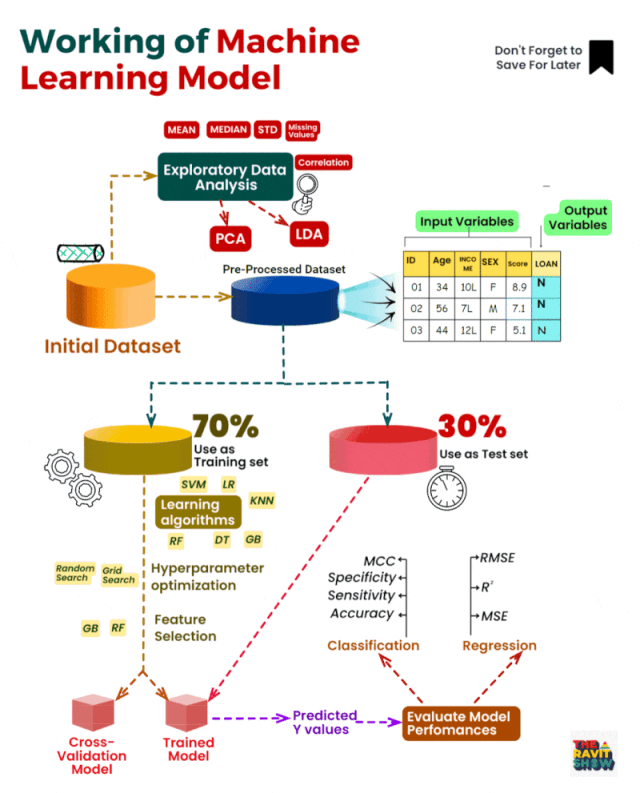

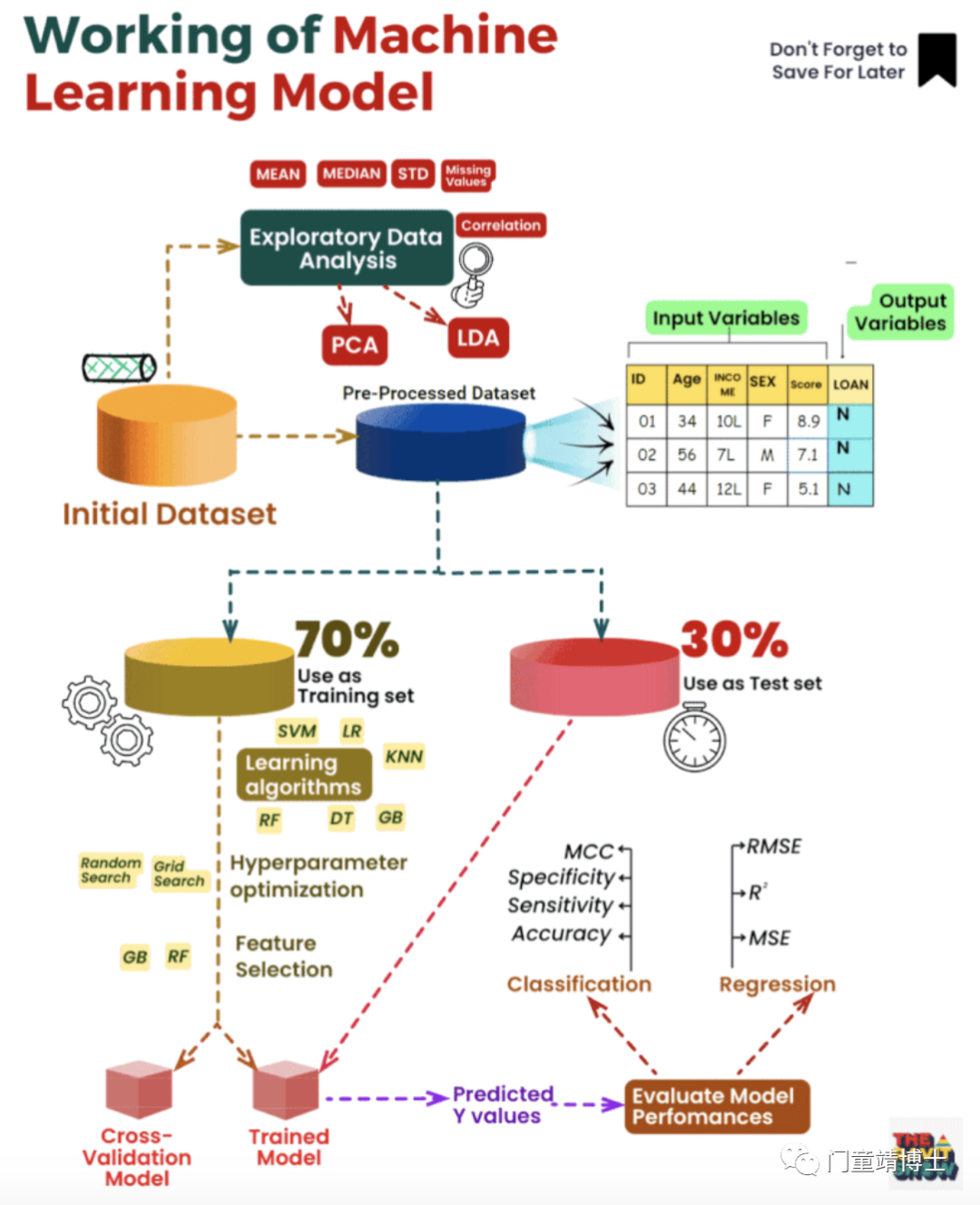
机器学习模型的内部工作原理如何工作?可以将下列场景代入到这个运行流程中。
代入案例:
收入(Income)和贷款(Loan)是我们用这个模型探索的两个基本变量。
目标是根据各种输入特征(Features)(包括年龄、性别和分数)以及他们的贷款状态来预测个人的收入。
以下是我们如何构建模型的分步细分:
1. 初始数据集(Initial Dataset):我们从一个包含个人信息的数据集开始,包括他们的收入、贷款状态、年龄、性别和分数。
2. 探索性数据分析 (EDA):我们执行彻底的 EDA,以深入了解数据、发现模式并识别潜在挑战。
3. 数据清理(Data Cleasing):我们确保数据集没有错误、不一致和缺失值。
4. 数据管理(Data Curation):删除冗余功能以简化数据集并提高模型性能。
5. 预处理数据集(Data Preprocessing):我们使用PCA(主成分分析)和LDA(线性判别分析)等技术对数据进行预处理,以减少维度并提取有意义的特征。
6. 用作训练集(Use as Training Set):预处理后,我们将数据集拆分为训练集和测试集。训练集用于教授数据中的模型模式和关系。
7. 学习算法和超参数优化(Learning Algorithms & Hyperparameter Optimization):我们应用各种学习算法,如SVM(支持向量机),LR(逻辑回归),KNN(K-最近邻),DT(决策树)和RF(随机森林)。这些模型的超参数使用网格搜索进行微调,以实现最佳性能。
8. 特征选择(Feature Selection):我们选择对结果有重大影响的最相关的特征,以避免过度拟合并提高可解释性。
9. 交叉验证模型(Cross-Validation Model):为了验证模型的稳健性,我们采用交叉验证技术来衡量其泛化性能。
10. 训练模型和预测的Y值(Trained Model & Predicted Y values):训练模型后,我们使用测试集对看不见的数据进行预测。
11. 评估指标(Evaluation Metrics):我们使用各种指标来评估模型的性能,例如分类准确性、灵敏度、特异性、MCC(马修斯相关系数)、RMSE(均方根误差)、MSE(均方误差)和 R²(R 平方)回归任务。
12. 回归(Regression):我们通过回归分析探索输入特征与收入之间的关系。
13. 评估模型性能(Evaluate Model Performances):我们评估模型在给定数据集上的表现,并在需要时进行必要的调整。
14. 其他模型(Additional Models):我们还尝试了随机搜索和梯度提升(GB),以比较它们与RF的性能。
15. 最终模型(Final models)已准备好对新数据进行预测,帮助我们深入了解个人的收入水平及其贷款状况。
以上,最好的方法还是实践,不妨用python执行一遍上述过程,相信你必定会成就感爆棚!
参考文献:
[1]https://www.linkedin.com/posts/ravitjain_how-does-the-inner-workings-of-a-machine-activity-7094543927134842880-RIFy/?utm_source=share&utm_medium=member_ios
原创文章,作者:门童靖博士,如若转载,请注明出处:https://www.agent-universe.cn/2023/08/10921.html