
1. 引言
大多数情况下,我们看到的AI 绘画都是极其炫彩的,特效感十足,比如下图这样。

但我个人还是偏好线条感强的,朴素的极简画风,比如下图这些。

我原本以为这种朴素画风对AI绘画来说会简单一些,但事实并非如此,后来我想通了。
-
一个素颜明星和一个浓妆艳抹的明星哪个更容易打造?
-
对于计算机来说,无论是一张简单线条画,还是酷炫特效图,背后都是m*n*3 的一个数学矩阵。计算量其实都是一样的。
如果你也喜欢这种风格的绘画,可以往下看,虽然最终结果距离设计师的水平差了一点,但经过几次的尝试,我也稍稍总结了一些经验,和大家分享。
2. 场景描述:科学人物肖像设计
先说说我做极简线条漫画的应用场景, 我的目的是用漫画讲人工智能科普故事(可以翻阅公众号中讲人工智能历史的文章)。因为是知识为主,漫画是辅助、强化读者记忆的,所以画面不能太酷炫导致喧宾夺主,故事中的科学家的角色,我也希望用极简漫画表示。我先放几张成品图来表达一下这个意思(当然距离我的理想效果还有差距,相信随着AI技术的深入,会有改进)。



不难看出,在这种场景下,作为知识博主对AI绘画人物有几个诉求:
-
能根据真人图片提取出面部特征。
-
同一人物能展现不同表情,比如科研受阻时的失望,取得成功时的喜悦。
-
同一人物能展现出年轻到年老的不同阶段。
我们一个个来说。
3. 第一步:根据真人图片提取面部特征
这一步是最重要,也是最费时的一步。我们先不要夹杂动作、表情等复杂描述, 就像在动画制作流程中,我们会先给每个人物做个T-pose,然后才开始修改面部表情和动作。

3.1 首先,准备垫图
垫图有两种:一是角色本人的真实照片,二是直接使用提示词生成的“大众脸”照片。
真人相片的垫图准备上有几点注意:
-
露出五官的人物照片的正面照片,以我的体会目前对图片的分别率其实要求并不高,当然在允许范围内尽可能找五官清晰的照片。这些科学人物一般都可以google 搜索到。
-
我的插画中一般都是黑白线条,所以先对图片进行黑白处理。
-
裁去人物身体部分,只露出肩膀与头的部分。
举例如下,左图为深度学习教父Geoffrey年轻时的一张真人照,右图为处理后的垫图。

直接使用提示词生成的“大众脸”照片在说完提示词后的3.3部分有示例图展示。
3.2 撰写提示词
提示词分文字描述中变化的部分(主要是人物描述部分)、不变的部分(主要是风格描述)以及参数部分(可选部分)
1)提示词中变化的部分
-
身份:身份有助于对人物气质的塑造,比如我的文中大多数是名校博士生,或者是教授等科研工作者。身份就是“a MIT male student in 1980s” ,当然我的角色不一定都来自于麻省理工,只是麻省理工比较出名,大模型很容易就可以识别。
-
性别:male,这属于基础逻辑,不做过多说明。
-
发型, 穿着描述。
为什么强调发型和穿着?在服饰方面:因为要保持极简风格,一般会让角色穿着纯白白色T恤衫这种百搭基础款。提示词为:wearing clean white T shirt with crewneck(穿着纯白圆领T恤衫)。其次是因为发型和服饰比五官更能塑造视觉印象。我们不妨再仔细看看开头极简风这张图片,你会发现人物的五官大体是一致的,只是发型、服饰大不相同,从视觉上就能将人区分开。所以在提示词当中稍微加重发型、服饰的比例,使得人物更容易识别。

2)提示词中不变化的部分
不变的部分主要是风格限定,我写的是以下提示词:
-
保持背景单一:100% white background
-
手绘线条风格:hand-drawing style, hand illustration ,simple fine line art,line drawing portrait of a <woman/man>, black and white illustration
-
极简风格:minimalism style, –no details
3.3 生成“大众脸”垫图与真人垫图融合
首先用3.2中的提示词不加任何垫图生成照片如下,当然这一轮你可以看到四张图片差异非常大,这一步重复几次,找到最接近你预期的“大众脸”照片,这一步有点像“抽卡”,随机性很强。
然后将刚刚生成“大众脸”照片和真人照片使用Blend命令融合,mid journey中的Blend的命令非常稳定,可控性非常强,这一点绝对不是“抽卡”实验。
以上两步的示例图如下:

(注:因为文中使用的人物都是侧面出现,所以在blend 之后加了side view-侧面照作为提示词)
3.4 参数部分(可选步骤)
这一部分不是在所有图中有用到,如果前两部分可以满足诉求,这一步可以省略,但这一部分在很多情况下还是很重要的。
1)使用种子参数(推荐用此方法来控制风格)
当你得到了一个人物的风格之后,想以此风格做出其他角色,目前我的测试结果是以已确定的图片作为种子方式来设定能最快达到你想要的风格。
比如下图中,我们将已经确定的角色风格作为种子,和待转换风格的人物原图,再加上必要的提示词,就可以得到风格一致的另外一个角色。

关于种子的介绍,稍后会有详细分享,之后会把链接更新在这里,也欢迎大家关注,随时发现我的更新。
2. 指定垫图比例(可选):
MJ中用双冒号指定比例,[普通人原图]::<所占比例> [风格参考图片]::<所占比例>。
这里使用另外一篇文章中的图片作为示例,下图中真人原图比例为3, 参考图片比例为1。使用过程中可以调整比例值来得到想要的效果。

第二步:同一人物能展现不同表情
这里只需要采用第一步生成的图像作为垫图,把第一步生成的图像种子作为Seed 参数加进去,然后加上表情表述,就可以得到比较好的结果。
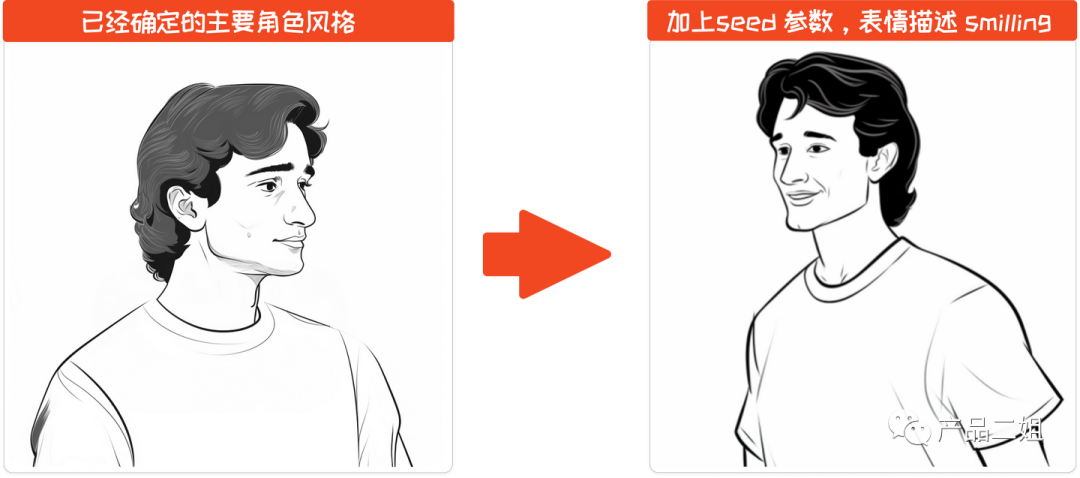
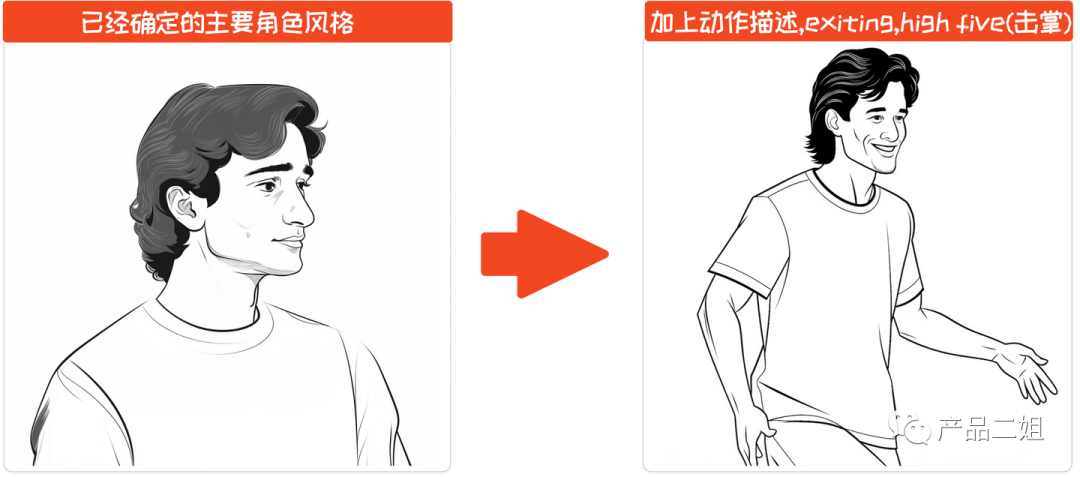
如果需要动作,加上动作描述。如果你的动作需要肢体,而第一步生成的图像没有肢体部分,可以考虑去掉Seed 参数。
第三步 展现出年轻到年老的不同阶段
其实和之前的方法类似,提示词中加上年龄,比如45-years-old, 或者年轻照片中提示词输入 —no wrinkles, 这里输入 with wrinkles,这里不再举例。
第四步 不同角色合成一张图片
这一步使用的都是传统工具,主要是完成以下工作:
-
把图像做镜像转换,这样看起来两人是面对面在说话。
-
加上气泡,文字。
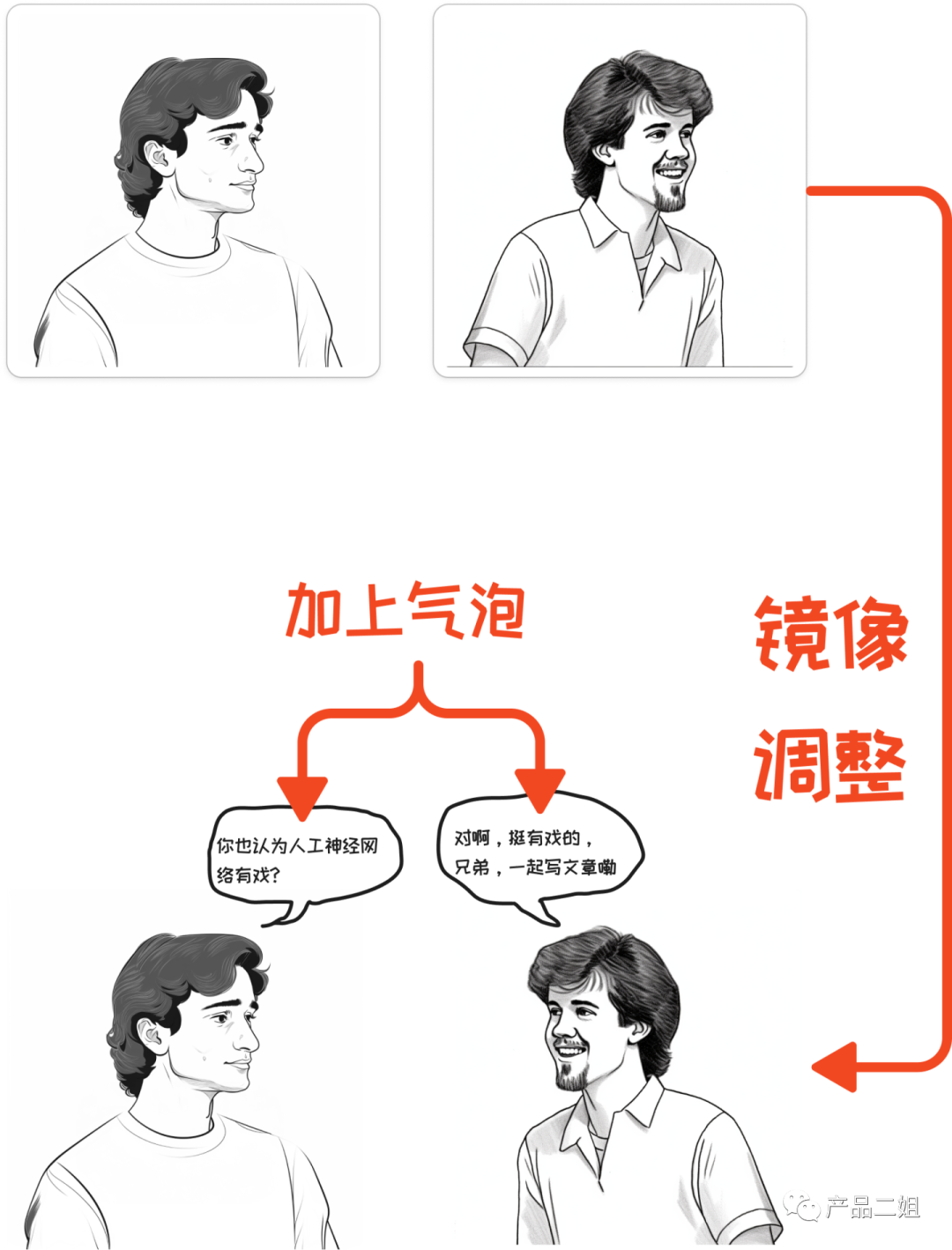
我自己体验了一些传统工具,最好的是figma-jam工具,免费版可以有三个画板,对于一个小知识博主来说,目前够使用了。
总结
刚开始使用Mid-journey的时候,总觉得是在“抽卡”,也被人物风格不一致所困扰,但是在真正深入使用之后,在抽卡的同时的确有些方法来控制。相信AI工具在确定性和不确定性之间会有一个平衡,来满足不同应用的诉求。
我是关注AI产品的产品二姐,致力于带来丰富的AI学习分享、体会,欢迎关注、点赞、转发、收藏。
原创文章,作者:产品二姐,如若转载,请注明出处:https://www.agent-universe.cn/2023/12/8550.html