
产品二姐
读完需要
分钟
速读仅需 4 分钟
1
先给大家先算个账:假设我要 GPT4 Turbo 帮我总结一篇 5000 字的文章,生成的总结是 500 个汉字,总共需要多少钱?这是一道数学题。
已知条件是:
一个汉字约等于 2 个 token
OpenAI GPT 4 Turbo 的价格是:输入$0.01/K token,输出$0.03/K token
解答:
总结 5000 字的文章总金额 = 0.01 ✖️ 输入 token 数/1000 + 0.03 ✖️ 输入 token 数/1000 = $0.13,也就是 9 毛钱。
如果按照我每天 10 篇文章的阅读量,每年要 9✖️365 = 3285 元,这个数字对我来说还是太贵了(也许某些媒体机构可能会使用)。
看来要大规模应用 LLM,降低算力成本也是首要任务,这个话题非常广泛,比如:
做芯片的人可以思考怎么在芯片制造领域降本
做模型的人可以思考怎么在模型侧降低预训练成本
以上两者让科学家们去搞,那么做 AI 应用的是不是没有办法呢,也不全是,所以就构成了这篇文章的副标题:
作为 AI 应用开发者,目前以及未来有什么方法降低算力成本?
目前这方面的探讨不多,大家多多指正。按照之前一篇讲大模型 AI 应用架构中提到的四层结构,我认为AI 应用开发人员的降本方式集中在模型的选择和应用层的使用上。
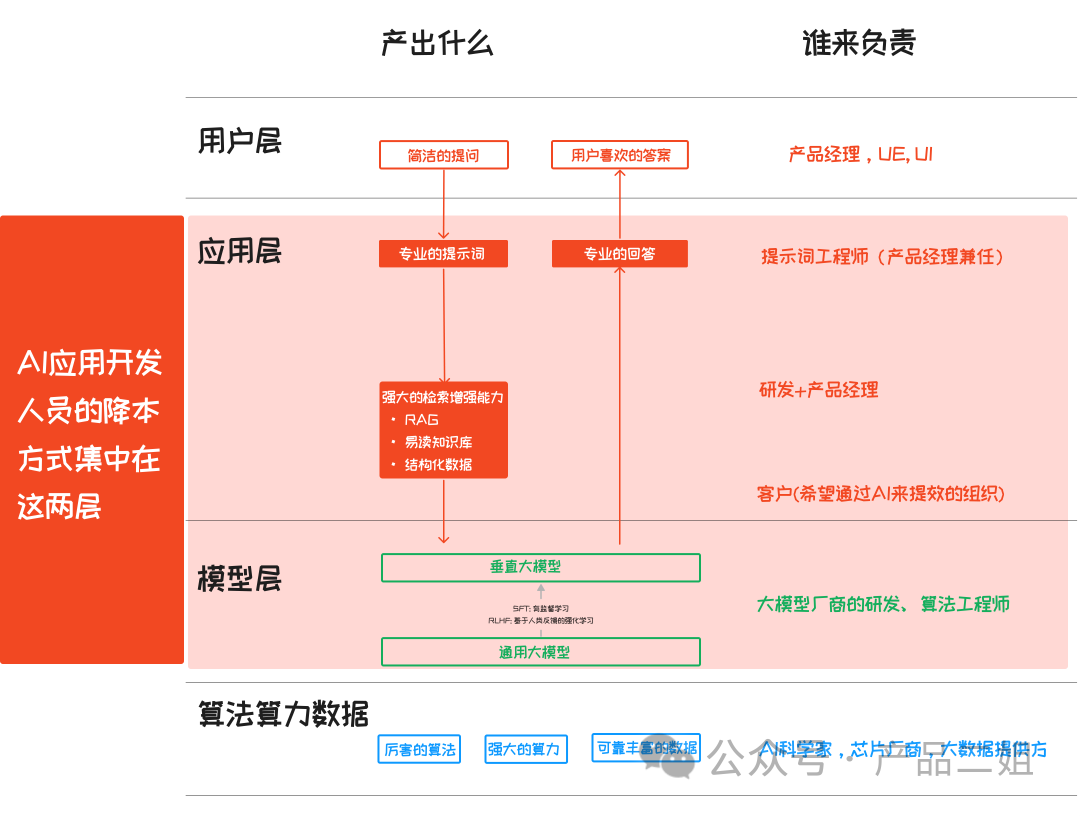

这一篇我们来讲模型层的成本计算,应用层的下一篇来讲。
2
先说结论:
1.大概率来说,模型的定价和模型参数量、训练数据的 token 量成正比。所以模型参数量越小,训练数据的 token 量越小,成本越低。
2.参数量小,并不意味着模型能力也会低。评估小模型是否适用于你的场景,一看机构评测,二看垂直度,三亲手实验。
3.训练数据的 token 量越小,也并不意味着模型能力低。训练数据的质量比数量更重要,使用时要考察数据质量和数据垂直度。
4.可以尝试采用“联邦小模型”的方式,在应用侧做好分发,从而达到”花小模型的钱,享大模型的福”。
我们一个个来看。
3
注:这一部分的计算量有点大,不过都是加减乘除,大家轻松看待。
首先对于模型厂商来说:模型算力成本 = 预训练成本 + 推理成本 。
3.1
预训练成本
即训练一个模型所需成本,按照过去 openAI 的节奏是每半年训练一次。预训练成本计算如下:
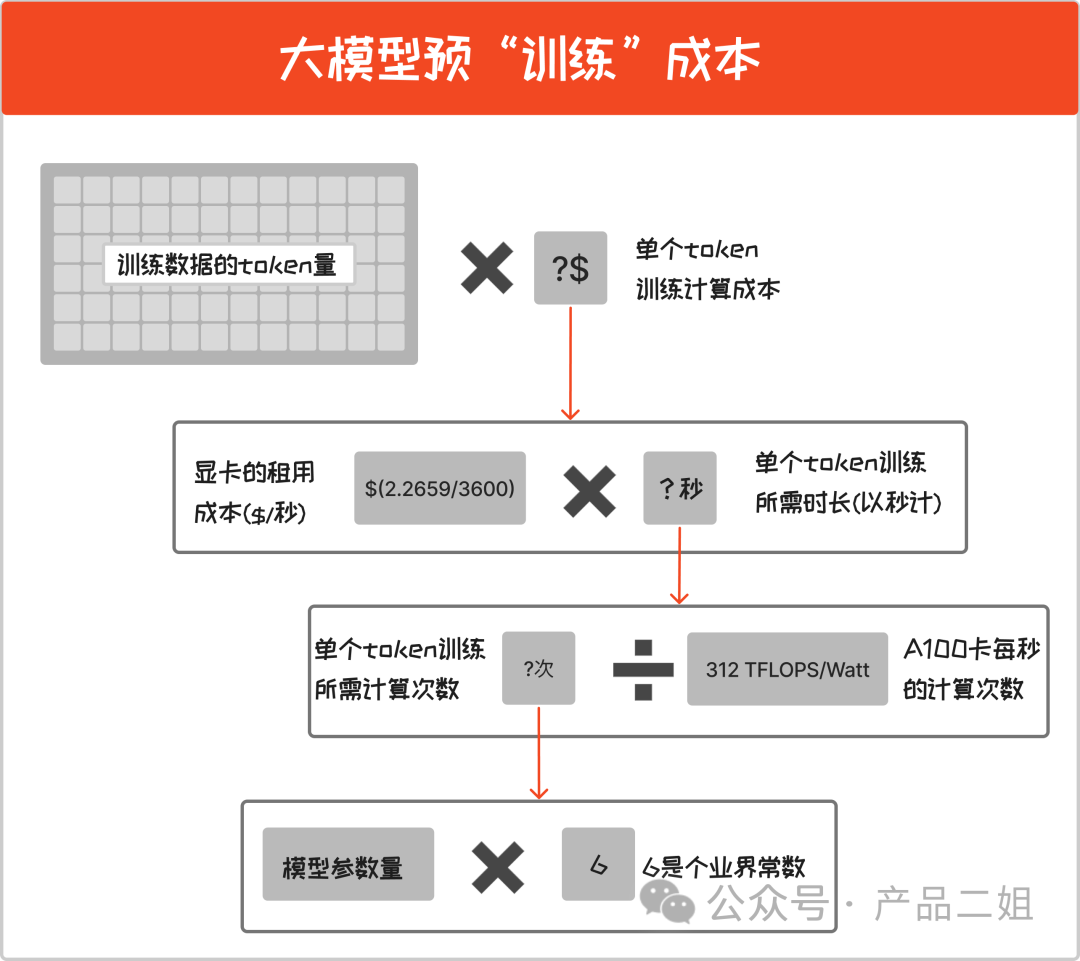
预训练成本 = ( 模型参数量 ✖️ 6 /A100 卡每秒的计算次数) ✖️ 显卡的租用成本 ✖️ 训练数据的 token 量
在这里有两个两个常量:
A100 卡每秒的计算次数 = 312 TFLOPS/Watt (官方公布,每秒可以进行 312T 次浮点数计算)
显卡租用成本:暂时以微软 Azure 云上公布的 Nvdia A100 的三年期租用价格$2.2659/小时计算,本文按秒来计算,就是每秒租用价格为$(2.2659/3600) (参考 https://azure.microsoft.com/en-us/pricing/details/virtual-machines/linux/#pricing)
常量之外,还有两个变量,他们与预训练成本成正比:
模型参数量
训练数据的 token 量
拿 openAI 的模型举个例子大家感受一下(考虑到这里的显卡成本是按照租用成本来计算的,openAI 作为显卡消耗大户,咱们可以直接打个五折):
-
GPT3 的参数量是 175B,训练数据的 token 量 500B,约 105 万美元*5 折,约 372.75 万元。
-
GPT4 的参数量是 1800B,训练数据的 token 量 13T, 费用是 GPT3 的 280 倍,约 1.45 亿美元,人民币 10 亿元。
-
GPT4 Turbo 的参数量是 8*222B ,训练数据的 token 量 13T,费用与 GPT4 差不多。
注:GPT4 和 GPT4 Turbo 的参数量和训练数据 token 量均为坊间普遍传闻,并未得到 openAI 证实。
预训练成本算出来之后,我们看看算力成本的另外一项:推理成本。
3.2
推理成本
即每次用户问答时消耗的算力成本,是按用量来消耗的,我们就按照 open AI 的定价单位:每千个 token 来算。
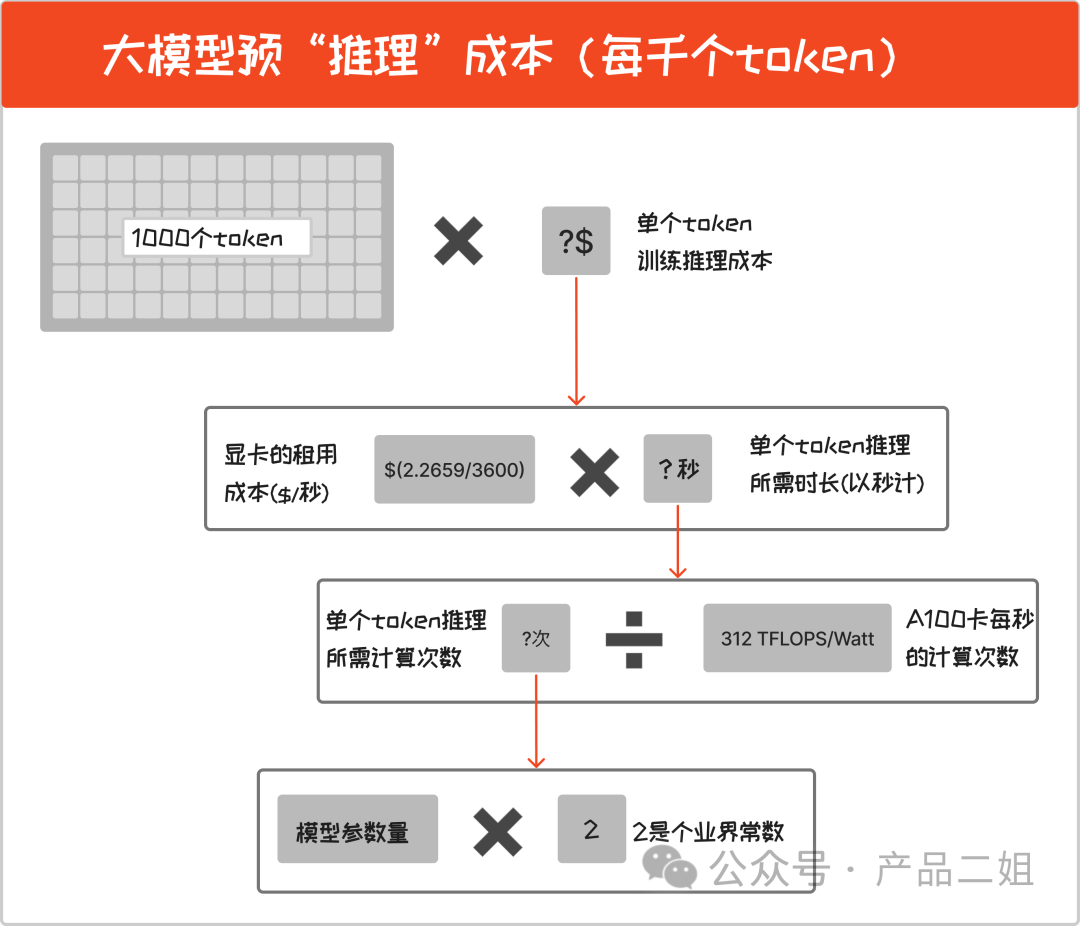
每千个 token 推理成本 = 1000✖️( 模型参数量✖️2 /A100 卡每秒的计算次数)✖️显卡的租用成本
推理成本仅与模型参数量成正比,拿 OpenAI 最新的 GPT4 Turbo 模型举例:
GPT4 Turbo 的参数量是 8✖️222B,按照上述公式计算,每千个 token 推理成本 = $0.0071656。
到这里大家可能会好奇:openAI 到底要有多少使用量、多少用户才能收回成本?这个问题我放在文末。我们先来总结一下这一部分的核心:
模型的算力成本与模型参数量和所使用训练数据使用的 token 量成正比,大概率来说(因为定价不一定总是以成本为标准):
模型参数量越少,成本越低
训练数据的 token 数量越少,成本越低
但是模型参数量变小了,训练数据的 token 数量越少,是不是意味着效果也会变差?当然不是,比如 9 月份发布的 Mistral 7B,只有 70 亿参数,就能匹敌 Llama 1 34B(拥有 340 亿参数)。当然,目前来说,GPT4 Turbo 是公认的一骑绝尘,但在 GPT4 之下:
没有最大的模型,只有最合适的模型。
因为从产品角度,我们有时并不需要模型有那么多的参数量,也不需要模型训练那么多数据,这时候我们就需要评估:
参数量小的模型能不能满足我们的使用场景?
预训练数据量低的模型能不能满足我们的使用场景?
原创文章,作者:产品二姐,如若转载,请注明出处:https://www.agent-universe.cn/2024/01/8536.html