
产品二姐
读完需要
分钟
速读仅需 6 分钟
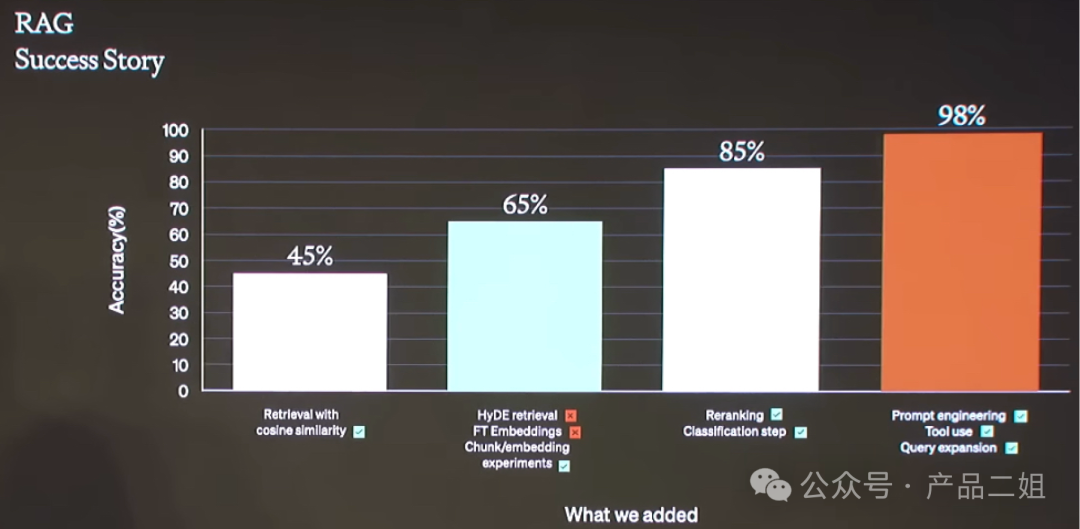
先说说标题中那个“40%”是怎么来的。下图是 open AI 开发者分享中提到的一个 RAG Success story, 他们利用 RAG 为金融领域的客户将问答准确率从原始的 45% 提升到 98%,这之间的差值是 53%,因为这是全球最佳案例,我们也没有 OpenAI 那么高的人才密度,打个八折大概是 40%,这就是40%的暴论来源。

之前有人提过在 AI 时代,大模型的能力占到 80%,意味着留给应用开发者的空间只有 20%。我没有那么悲观,根据上述案例,姑且粗暴给出如下的比例:
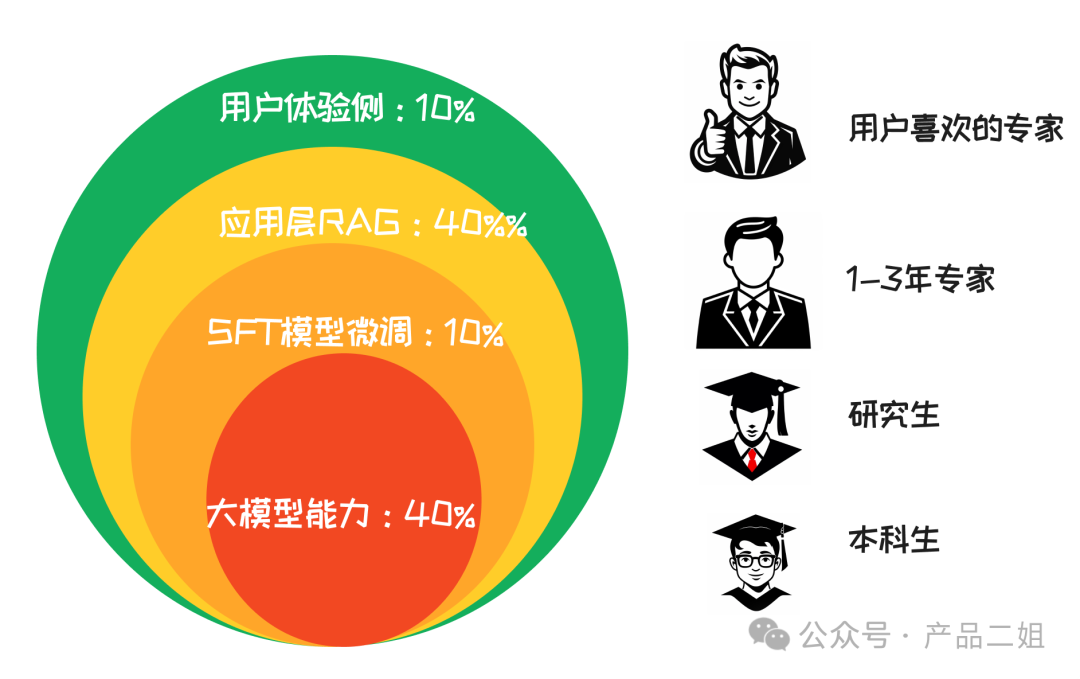
模型层LLM 的能力:影响为 40%。
模型层SFT 微调:影响为 10%。主要考虑微调投入的成本高,同时需要大量的高质量数据,因此可能不适用于大多数情况,所以定比例为 10%。
应用层RAG:影响为 40%,理由如上。且相对微调模型性价比更高,适用于更多的情况。
用户层:10%。不是说 UE 不重要,而是我们在移动互联网已经积攒了非常成熟的 UE 能力,做起来不会那么难了。
在重点讲 RAG 技巧前,我们介绍一下什么是 RAG,详细的解读网上已经很多,本文仅做简单介绍。
1
我们经常把大模型比作一个大学生。
没有 RAG:相当于面试的时候问大学生”你是如何看 xx 公司的?“。
有了 RAG:相当于对已经入职的大学生说“去我们公司的资料库里查查,出一个关于这个公司的调研报告”
“查阅资料库”就相当于是 RAG,它的全称是 Retrieval Argumented Generation — 检索增强生成。意思是:
把检索(资料库)的结果发给大模型,以增强大模型的生成能力。
说实话 RAG 入门很容易,我的开发伙伴(公众号 AI 小智)在带病情况下,大概用了一个周末完成 coding。不过要想做好可不容易。这大概就像:你把两批同样的资料派给不同的公司管理,还让不同人去查,二者都能得到答案,但要找到好答案可不是一件容易的事情。事实上,连 OpenAI 自己都说 RAG 比想象中困难,看到这里我也就释然了。

接下来就来重点讲讲在这 40%空间中,我们能折腾些啥东西(包括 openAI 开发者分享中提到的几个手段),较长建议收藏。
2
首先 RAG 不是一个单项技术,它是一个流水线,行话叫 pipeline。只有对流水线上的每一步骤都进行精细打磨,最后才能出来效果,我们的目标就是努力使每个环节都达到尽可能准确,努力向 openAI 的最佳实践案例接近,从而保证最终的结果。
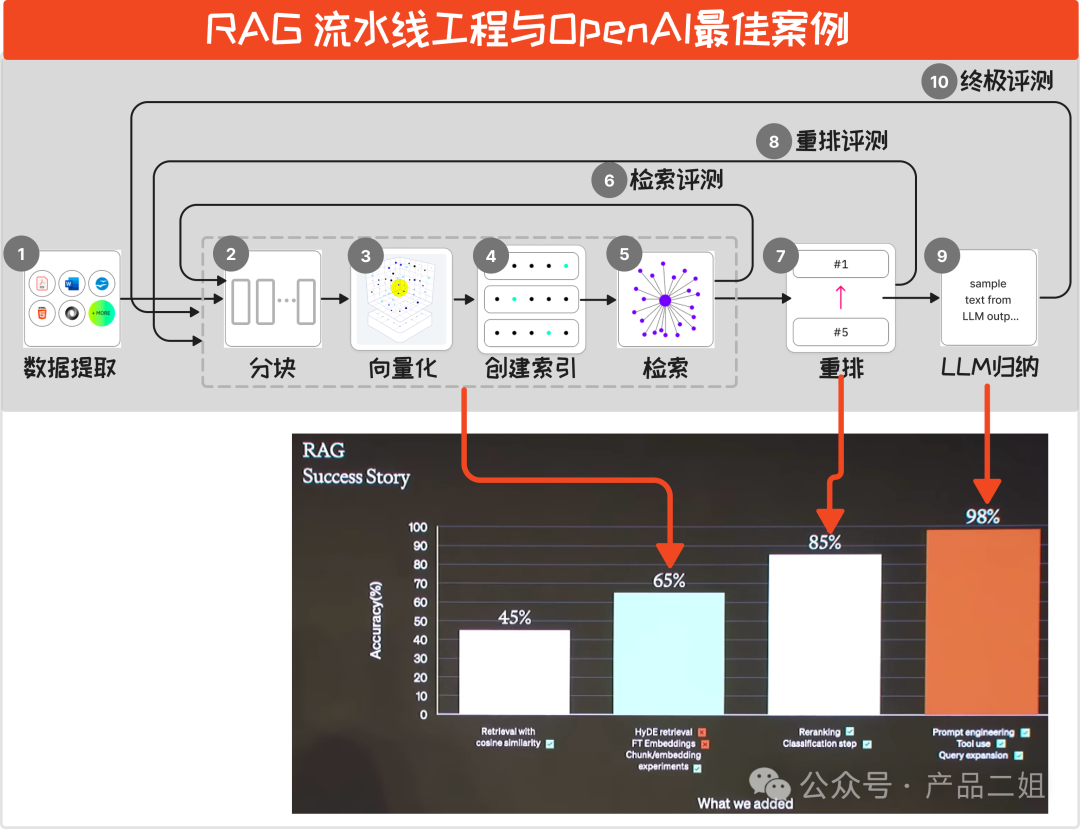
接下来我们对这个 RAG Pipeline 中的各个环节做一个概念介绍。为了便于理解,这里都会拿“查阅资料库”来类比。
1.数据提取:类比于资料库的资料来源。主要目标是确保资料数据完整,除此之外,还可以新生成一些数据,比如利用大模型对资料进行 summary,打标签,以便于后续处理更高效。
2.分块(Chunking) :类比于资料应该拆分到多细来存储,用梗话来说就是“对齐颗粒度”。比如按段落拆,按句子拆,按单词拆等等。
3.向量化(Embedding):类比于把拆分后的内容转换为计算机可处理的向量,向量化就是把一个物体拆成多个维度表达。举个例子,假设书可以从以下八个维度去表达。
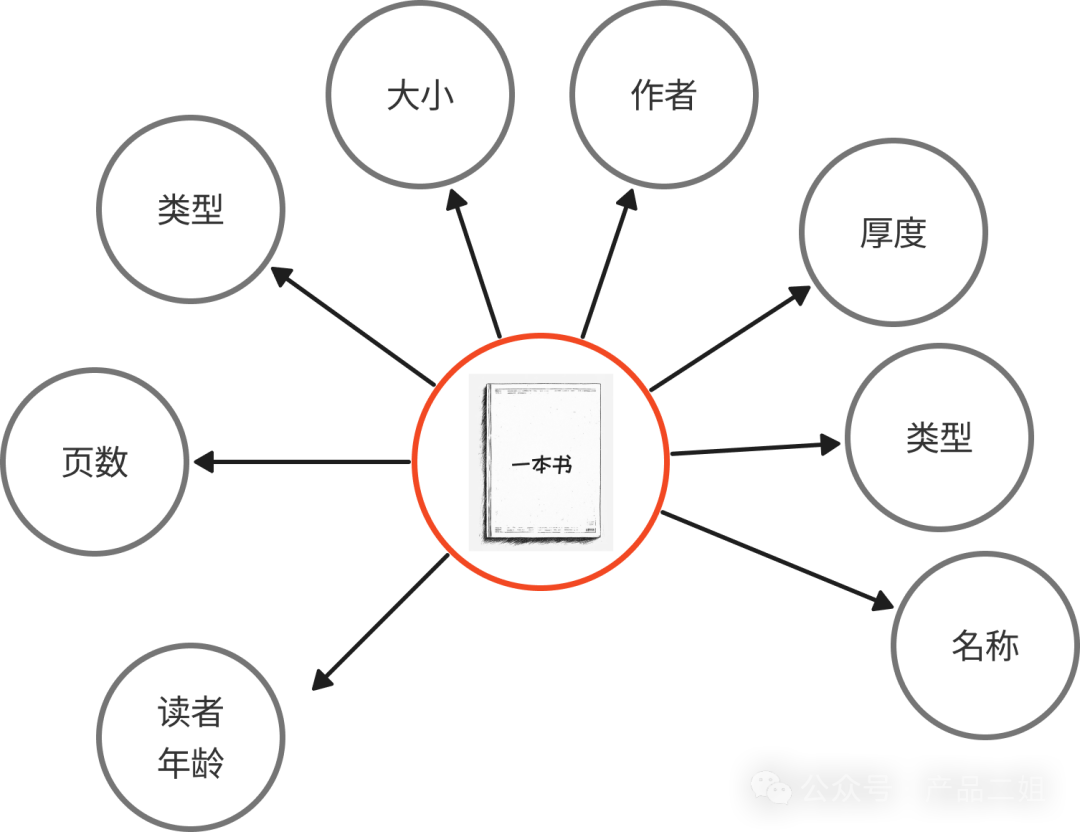
那么对于某一本特定的书《思考的快与慢》对应的向量值就是八维空间的一个点,计算机就是通过这些点来定义事物。同样,语言文字也可以被向量化,且语言都已经有成熟的向量模型,比如智源的开源 embedding 模型 bge-large-zh-v1.5 有 1024 个维度。在 RAG 做向量化中,我们可以直接使用这些成熟的语言向量模型,也可以对这些模型微调后再使用。
4.创建索引:类比于把向量化后的资料块进行分类、整理,按照一定顺序放在对应位置后给出序号,方便后面的检索查找。索引可以建多个,比如书可以按照图书分类排序,也可以按照出版时间排序。至此,你的资料库终于建好了,接下来就是根据具体问题在这些资料库中查找了。
5.检索环节(Retriever):类比于在资料库找相关资料。系统会根据用户的提问,在索引中查找最相关的数据块。主要目标就是找到和问题匹配度高的资料(注意此时还没有形成答案)。
6.第一轮检索评估 : 大多数文章中会漏掉评估的环节,往往被开发者忽视,没有评估等于盲走。这里的评估可以是手动评估,也可以是机器评估。机器评估就是魔法打败魔法,比如用 GPT4-tubo 根据你的资料给生成问答对,然后再让它给检索结果打分。openAI 的案例中到达这一步将准确率提升到了65%。
讲到这里我们停一下。实际上到这一步之前,在技术上和互联网的搜索逻辑是类似的(其中有少部分措施比如 HyDE 是大模型之后才出来的 embedding 方法),我们统称为“语义检索” 阶段。意味着如果你公司内部的知识库已经具备“语义搜索”能力,那么通过嫁接下面两步就可以实现基于 LLM 的问答应用了。这也是 Rerank 模型 cohere 在官网上的建议 。
接下来的环节就是大语言模型 LLM 出来后特有的阶段。
7.重排序(Rerank):语义检索出来的结果相当于是资料初筛,讲究的是效率。重排序顾名思义就是对初步检索结果进行重排序,以便得到更精确的结果。如果说第一轮检索是初赛,那么重排序就是复赛。Rerank也有大型机构给出的重排序模型。
8.重排评测:和语义检索阶段一样,在重排序之后,我们也应该有一个评估机制。目前看到机构的实验结果可以将命中率提升至 90% ,而 openAI 的案例中是 85%。
9.生成(Generator):这一步对应的就是系统终于找到了最准确的资料,将资料整理总结,形成完整报告。实际上就是将重排序后的资料片段加上用户的提示词,提供给大型语言模型LLM,由 LLM 根据上下文生成最终的输出。在这个过程中,主要在提示词、上下文、意图识别方面下功夫。
10.终极评估:这一轮的评估指标和检索、重排序指标不一样,现在有专门用于评估 RAG 的框架 RAGAS 等,后面会讲到。目前 openAI 的案例中最终结果是 98%。
总的来说,RAG 流程玩的是一条流水线上的组合拳(此处不是互联网黑话),对于应用开发者来说,比拼的就是对不同的场景该怎么打这套组合拳。接下来我们详细在每一步看看都有哪些组合拳,不一定全,但大体可以把它当做一个手册随时对比查看。
接下来请欣赏 RAG 组合拳大串烧~~ 其中会有大量的参考文章(包含代码干货示例),值得收藏当作手册查阅。
3
在 RAG 流水线中,数据提取是第一步,相对其他步骤来说这一步较为可控。它的目标是保证数据完整、准确、易读,包括:
内容完整:不要漏掉内容,包括图片、文本、表格等。
内容准确:比如 PDF 文件中使用 OCR 识别时,尽可能避免识别错误。
关系完整:比如要保留段落层级关系、图片与图片说明的关系。
元数据完整:即数据本身的属性,比如文档标题、生成时间,某段字的字体大小、颜色等。
在参考文章《用 python 提取 PDF 中各类文本内容》中以 PDF 为例,通过 OCR 技术进行完整的数据采集方法,并附有代码,大家可以参考。文章作者土猛的员外推荐大家关注,我的很多内容是从他那里习得的。
除此之外,我们也可以利用大语言技术通读文章,生成文章标签、文章 summary 等附在元数据中。
4
分块简单来说就是对齐颗粒度。举个例子,针对同样一篇文章,用户提出如下两个问题,需要检索的内容颗粒度可能是完全不一样的:
ChatGPT 是哪天发布的?
ChatGPT 的发布对人类有什么影响?
第一个问题是快问快答,简明扼要回答就好,需要分块到句子单位。第二个问题需要详细陈述,可能需要分块到段落单位。如何分块也是个技术活,主要考虑以下几个重要因素,我个人按照重要程度排序如下:
1.用户诉求的长度和复杂性:这将影响分块策略的选择,以确保查询结果的相关性和准确性。比如刚刚提到的例子,但问题是这种例子在同一产品中会混合存在,那么就需要同一资料有不同的分块策略。
2.资料库内容本身的长短:比如对于微博、小红书这类的资料库,内容本身就短小精悍,分到句子、甚至短语,可能都不具备分块到段落的程度。对于博客、论文就可以采用不同的分块方法。
3.根据你选择的 Embedding 模型匹配的最佳块大小:不同的embedding模型可能在不同大小的块上表现最佳。例如,某些embedding模型在单个句子上表现良好,而另一些则可能在较大块上效果更好。并且现在也有些 Embedding 模型本身就会支持不同量级的分块,以便达到更好的检索结果。比如智源的 BGE-M3 embedding 模型就会支持不同颗粒度的输入,参考《新一代通用向量模型BGE-M3》。

原创文章,作者:产品二姐,如若转载,请注明出处:https://www.agent-universe.cn/2024/02/8534.html