特别活动!
欢迎观看大模型日报 , 如 需 进 入 大 模 型 日 报 群 和 空 间 站 请 直 接 扫 码 。 社 群 内 除 日 报 外 还 会 第 一 时 间 分 享 大 模 型 活 动 。
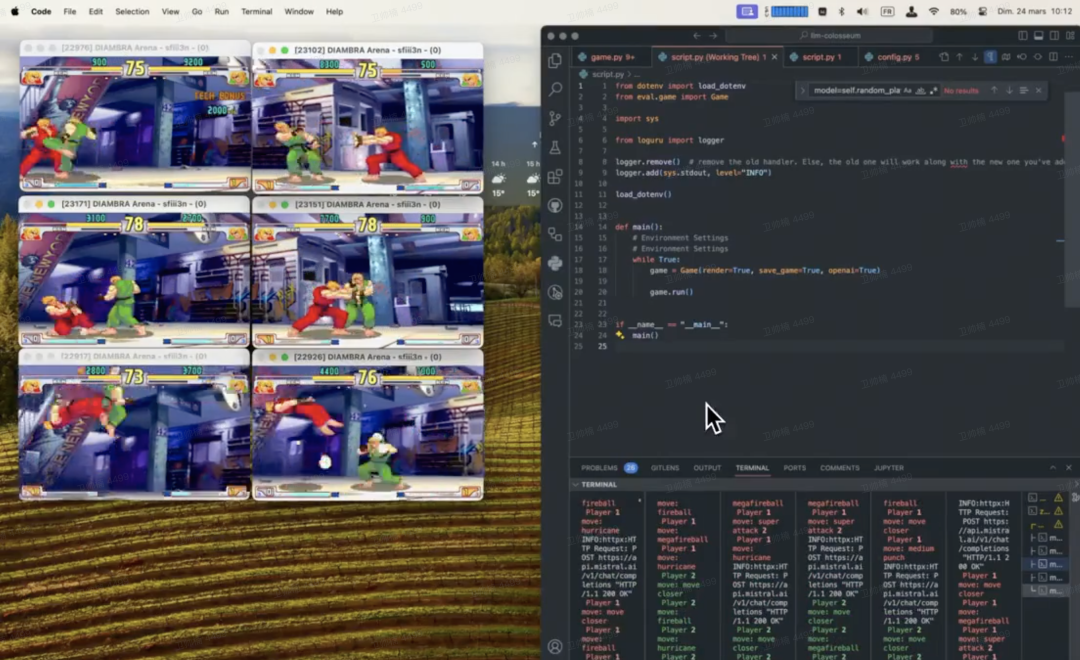
资 讯 准确率 >98%,基于电子密度的 GPT 用于化学研究,登 Nature 子刊 可合成的分子化学空间是巨大的。要想有效地驾驭这一领域,需要基于计算的筛选技术,如深度学习技术,以快速跟踪感兴趣的化合物发现。然而,使用算法进行化学发现需要将分子结构转换为计算机可用的数字表示形式,并开发基于这些表示形式的算法来生成新的分子结构。近日,来自英国格拉斯哥大学的研究人员,提出了一种基于电子密度训练的机器学习模型,用于生产主客体 binders。这些以简化分子线性输入规范 (SMILES) 格式读出,准确率 >98%,从而能够在二维上对分子进行完整的表征。 阿里等提出GraphTranslator,将图模型对齐大语言模型 图模型(GM)如图神经网络(GNN),利用节点特征和图结构来学习表征并预测,在多种领域表现出色,但 GM 通常局限于预定义任务如节点分类,难以适应新的类别和任务。而大型语言模型(LLM)如 ChatGPT,在处理开放式任务和理解自然语言指令方面显示了巨大潜力,推动了跨模态研究的发展。最近,将 LLM 应用于图的工作可分为两类,如下图 (a)-1 和 (a)-2 所示:1)利用 LLM 以其海量知识增强节点的文本属性,然后通过 GM 生成预测;2)或者是将节点以 token 或文本的形式,直接输入给 LLM 来作为独立的预测器。本文提出一个名为 GraphTranslator 的框架,结合预训练的图模型 (GM) 与大型语言模型 (LLM) 来处理预定义和开放式任务。GraphTranslator 中的「Translator」模块负责将图节点嵌入转换为 LLM 可理解的 token 嵌入,通过学习 graph queries 来提取语言信息并适配 LLM。 Sora落入电影人之手!首批专业AI微短片火了,实现创意再无阻碍 首批获得Sora访问权限的艺术家们创作的视频来了。OpenAI一口气发布了7个,每个视频都隐隐透露出了四个字:脑洞大开。创作者Paul Trillo是一名艺术家/作家/导演。其作品受到《滚石》和《纽约客》等媒体赞誉,并获得19次Vimeo员工精选奖,他表示:“通过使用Sora,作为电影制作者的我第一次感受到了真正的自由,我可以不受时间、金钱和他人的约束,大胆创新。当你不是在复制旧的事情,而是让新的、不可能的想法成为现实时,Sora的力量才最为强大,否则我们将永远没有机会见到这些想法。” 腾讯机器人研究登顶刊!能帮程序员安显示器,像真人一样协同干活 通用人形机器人无疑是近年来机器人与AI交叉领域的研究热点。其中的人形双臂系统直接承载着这类机器人操作任务的执行能力。任意抓取和操作具有各种几何和物理特性的任意物体则是这类系统通用化的技术体现。而现有研究工作大多专注解决某一特定层级的问题,例如环境-物体的感知、推理与策略生成、机器人系统的规划或操作控制。并且方案通常与特定的被操作物体或任务强相关,难以迁移和泛化。腾讯Robotics X实验室指出,要想实现这样的通用化双臂系统,需要解决现有研究工作中三个关键的共性问题。首先,如何基于视觉感知实现未知物体的双臂协同最优抓取。其次,如何确保工作空间高度重叠的双臂机器人在动态协同过程中的系统安全性。最后,如何将丰富的人类技能转移到仅拥有有限跟踪接口类型的机器人系统中。在此,腾讯Robotics X实验室提出的包含两个相互耦合关联的子框架:1、基于学习的灵巧可达感知子框架采用端到端评估网络和机器人可达性概率化建模,实现对未建模物体的最优协同抓取。2、基于优化的多功能控制子框架则采用层级化的多优先级优化框架,并通过嵌入基于学习生成的轻量级距离代理函数和黎曼流形上的速度级跟踪控制技术。 快手:快意通用大语言模型能力已超GPT-3.5,营销能力齐平GPT-4 快手商业化算法负责人江鹏在2024快手磁力大会上表示,快意通用大语言模型能力超过GPT-3.5,通过对快意大模型进行千亿级Token商业知识预训练、百万级商业指令对齐等,快手进一步研发了业界领先的营销域大语言模型,该模型能生成真正符合快手风格的素材,在营销领域的能力已与GPT-4齐平。快手女娲数字人平台能支撑超过2200路数字人24小时同时开播,盘古视频AIGC能够让营销转化率提升33%。 https://finance.sina.com.cn/7×24/2024-03-26/doc-inaprmts0685258.shtml 消息称苹果正准备在 WWDC 2024 上推出 AI 应用商店 正如许多其他大型科技公司那样,苹果也在努力为用户提供 AI 产品和技术。根据目前已知信息,苹果将会在 WWDC 2024 为大家展示这些全新融入 AI 元素的系统和软件。不过,苹果的 AI 策略可能不仅仅只是局限于自家 AI 应用,而是为开发者和用户提供一个更大的平台,从而能够使其更好地从中获利。Melius Research 主管 Ben Reitzes 周一在接受 CNBC 采访时表示,苹果可能会在 6 月份 WWDC 上推出一个全新的 AI 应用商店,预计将包括各大供应商提供的 AI 应用。 https://www.ithome.com/0/758/056.htm 高通携手英特尔向英伟达“下战书”! 欲打破CUDA“一家独大”之势 全球AI芯片领域当之无愧的“霸主”英伟达(NVDA.US),凭借着两大“核心吸金利器”:基于突破性的Hopper GPU架构的AI芯片——H100 AI GPU无与伦比的销售额,以及深耕高性能计算领域多年所倾力打造的CUDA运算平台——CUDA可谓是AI训练/推理等高性能计算领域首选的软硬件协同系统,英伟达当前市值已经攀升至2.4万亿美元,总市值位列全球第三,与市值排名第二的苹果之间的距离越来越小。近期包括高通、谷歌和英特尔等科技巨头,正计划通过开发一套能够支持多种AI芯片的软件和系统化工具,来打破英伟达在AI领域的软硬件主导地位。这个项目名为UXL,旨在创建一个开放源代码的AI软硬件生态系统,使计算机代码能够在任何芯片架构和任何硬件上运行,从而解决目前由少数几家芯片公司所主导的AI生态。 https://www.zhitongcaijing.com/content/detail/1091869.html 推特 真 · LLM竞技场:让OpenAI和Mistral AI在《街头霸王 III》中实时对战 介绍 LLM 竞技场!通过让它们在《街头霸王 III》中实时对战来评估 LLMs 的质量!谁是最强的?@OpenAI 还是 @MistralAI?让它们一决高下吧!开源代码和排名 由 phospho 和 @quivr_brain 制作 https://github.com/OpenGenerativeAI/llm-colosseum https://x.com/_StanGirard/status/1772023888211571197?s=20
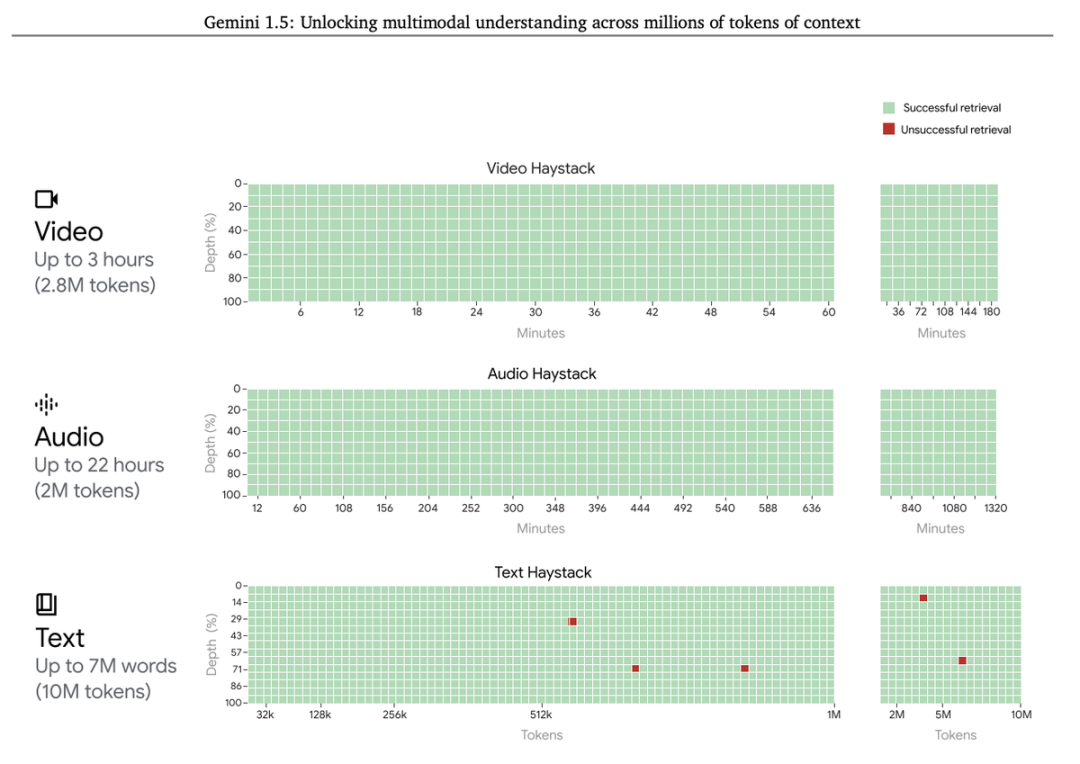
Shaun:作为一名AI创业者,分析为什么“RAG可能已经过时了” 警告:在阅读了58页的Gemini 1.5 Pro技术报告后,我认为RAG可能已经过时了。作为一名AI创业者,我的想法如下:
像向量数据库相似性搜索这样的简单RAG系统将会过时。但更加定制化的RAG仍将存在。RAG的目标主要是检索相关信息。在阅读报告后,我确信LLM可以在检索方面做得非常好。
RAG本身可能不会完全消亡,但90%的人不再需要它了。大多数数据集可以容纳在100万个token中。就像OpenAI的助手API一样,一旦Gemini API可以处理大文件,唯一重要的就是成本。然而,根据报告,1.5 Pro的训练成本和推理成本要比Gemini 1.0低得多📉
LLM检索默认是多模态的。它适用于任何数据格式、代码、文本、音频和视频!是的,Gemini可以以每秒1帧的速度检索视频中的关键帧。🤯 当大多数RAG系统难以处理不同的数据格式时,Gemini已经在模型级别解决了这个问题。
检索 != 推理。LLM在检索方面越来越好,但推理才是圣杯。
如果你想亲自阅读技术报告 -> https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf https://x.com/agishaun/status/1758561862764122191?s=20 Jim Fan评Evolutionary Model Merge:最富有想象力的LLM论文之一 这是我最近读过的最富有想象力的LLM论文之一:使用进化来合并来自HuggingFace的模型,以释放新的功能,例如日语理解。这是一种复杂的模型手术形式,所需的计算量比传统的LLM训练小得多。这项工作正是由@hardmaru完成的,他曾提出了许多鼓舞人心的”元技术”,如HyperNet和权重无关的神经网络。 只有两种方法可以随着计算能力无限扩展:学习和搜索(@RichardSSutton,《痛苦的教训》)。基础模型社区几乎只关注学习,但并没有太强调搜索。我相信后者在训练(进化算法)和推理(AlphaGo风格的搜索)阶段都有巨大的潜力。 https://x.com/DrJimFan/status/1771927650883522899?s=20 claude-journalist:Claude 3 记者代理 介绍 claude-journalist 第一个 Claude 3 记者代理。只需提供一个主题,它将: https://x.com/mattshumer_/status/1772286375817011259?s=20
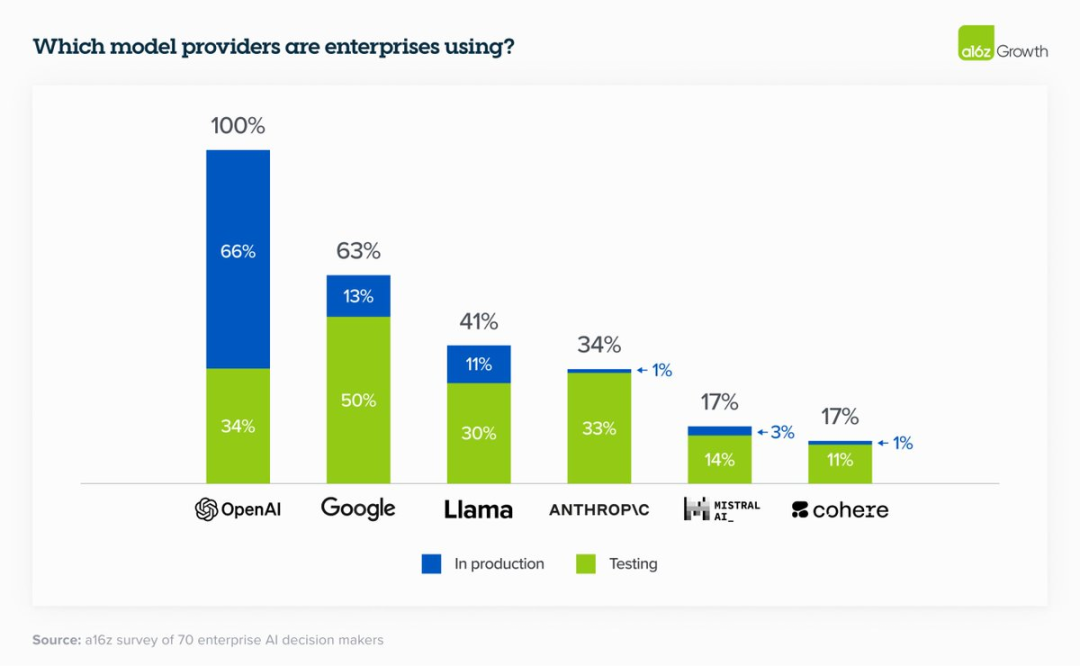
a16z企业AI报告:对于生产用例,OpenAI 仍占据主导市场份额 a16z 在与数十家财富 500 强公司交谈后发布了一份企业 AI 报告。
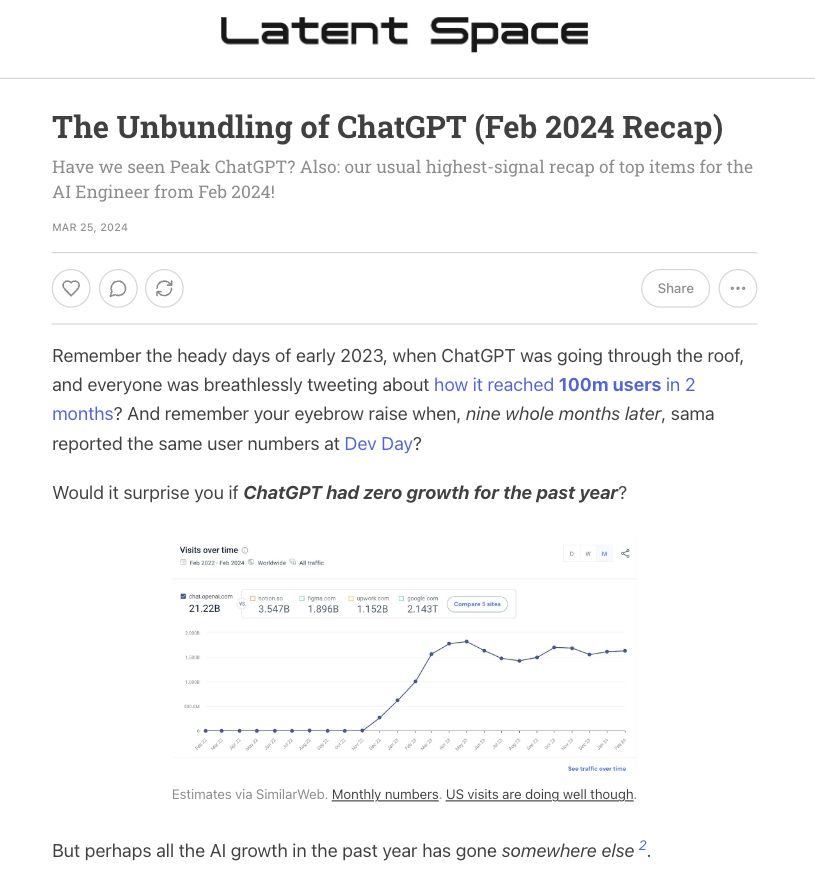
https://x.com/chiefaioffice/status/1771884750589841823?s=20 Shawn Wang“ChatGPT 的解绑”:整整一年过去了,ChatGPT 的用户数量几乎没有增长 https://latent.space/p/feb-2024 整整一年过去了,ChatGPT 的用户数量几乎没有增长。相反,用户正在探索大量垂直领域的玩家,涉及图像生成、写作、编码、研究、智能体、语音和 RAG。 在这种情况下,@OpenAI 仍然是赢家,但可能需要尽快发布 Sora 和 GPT-5,以阻止 ChatGPT 大量取消订阅。 https://x.com/swyx/status/1772305930836918656?s=20 Mistral AI三藩黑客松奖项获得者内容一览:生成式提示创建器、AI 销售人员等 Mistral AI 刚刚举办了迄今为止最大的 OSS LLM 黑客马拉松。超过 2000 名申请参加,争夺 10,000 美元的奖金。 生成式提示创建器,通过提示、计算与评估的损失以及更新提示来不断改进”学习” AI 销售人员,使用逼真的生成语音和视频回答有关您业务知识库的问题 将视频游戏截图输入 LLaVA1.5,并指示 Mistral 进行游戏 在你的代码库上微调 Mistral,并在其上创建类似 Devin 的功能 https://x.com/Alex Reibman/status/1772164601666314316?s=20
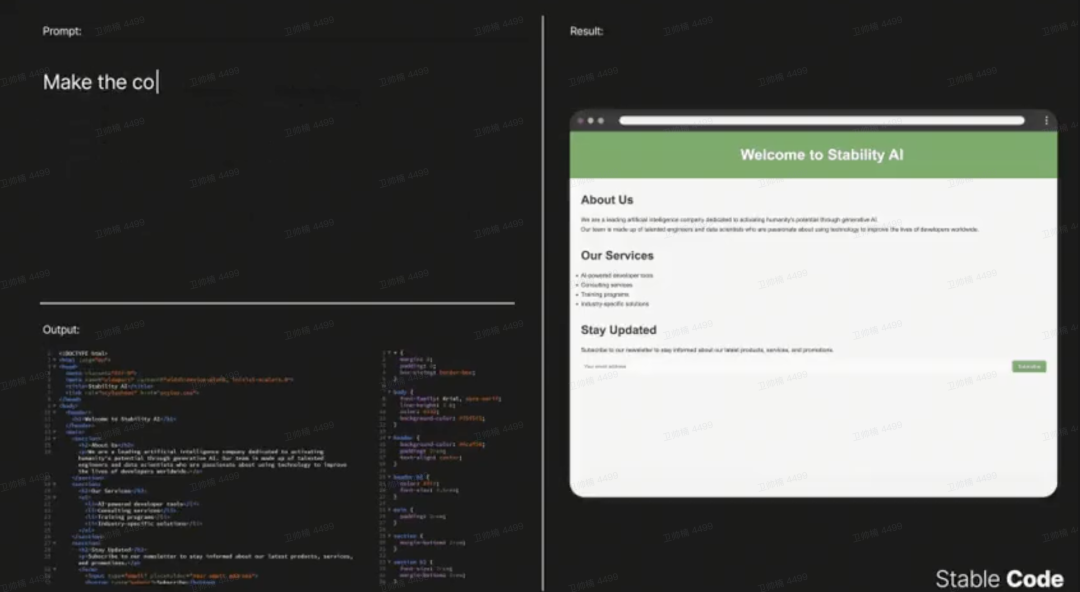
Stability AI发布Stable Code Instruct 3B,指令调优,可以和更大规模模型媲美 介绍 Stable Code Instruct 3B,我们基于 Stable Code 3B 新推出的指令调优 LLM。通过自然语言提示,该模型可以处理各种任务,如代码生成、数学和其他软件工程相关的输出。该模型的性能可与类似或更大规模的模型相媲美,包括 Codellama 7B Instruct 和 DeepSeek-Coder Instruct 1.3B。该模型现已可供 Stability AI 会员进行商业和非商业使用。在此了解更多信息并阅读研究论文: http s://x.com/StabilityAI/status/1772345514023116828?s=20
Stability AI发布Stable Code Instruct 3B,指令调优,可以和更大规模模型媲美 今天,我开始接受 Compass 的预订 – 一款售价 99 美元的开源指南。 Compass 通过转录你的现实生活对话来了解你。这使你能够重温生命中的重要时刻,做出更好的决定,并实现你设定的目标。 由于 30 小时的电池续航时间,这一切都成为可能。 https://x.com/ItsMartynasK/status/1771890769865187648?s=20
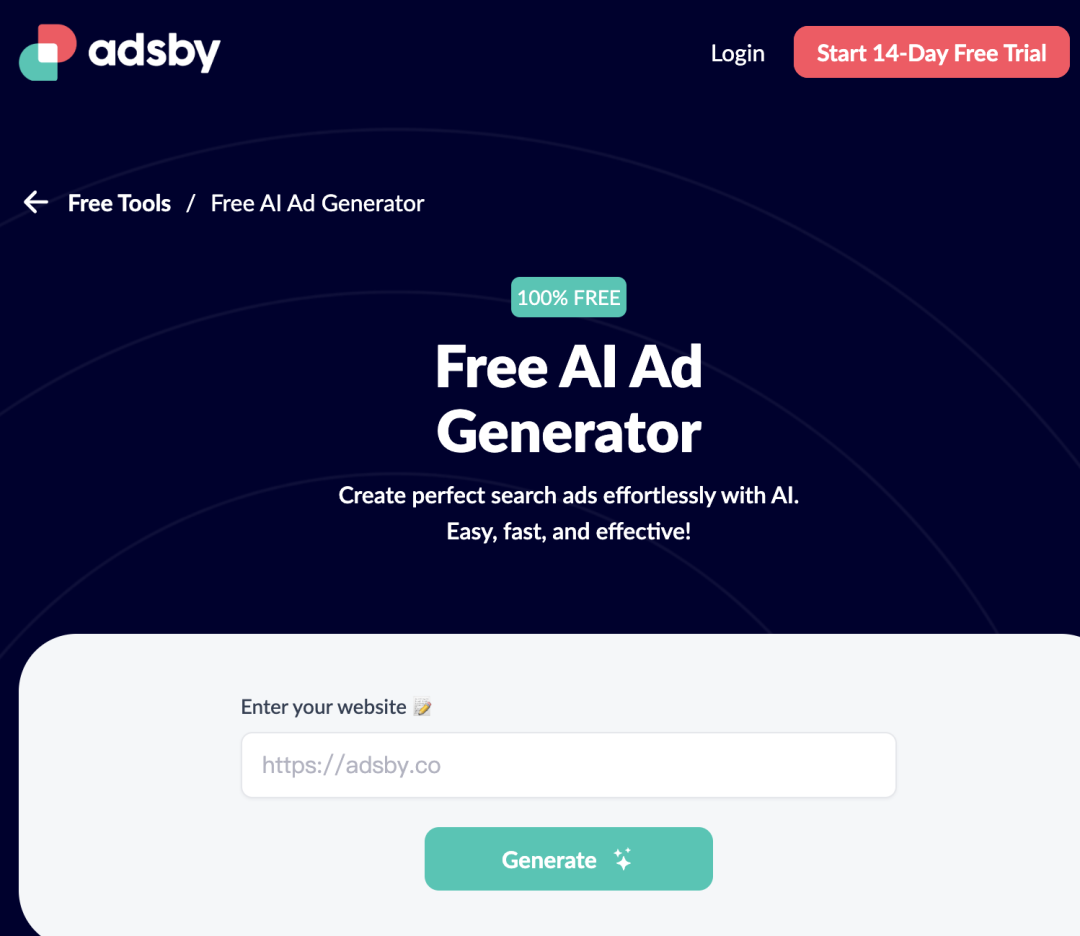
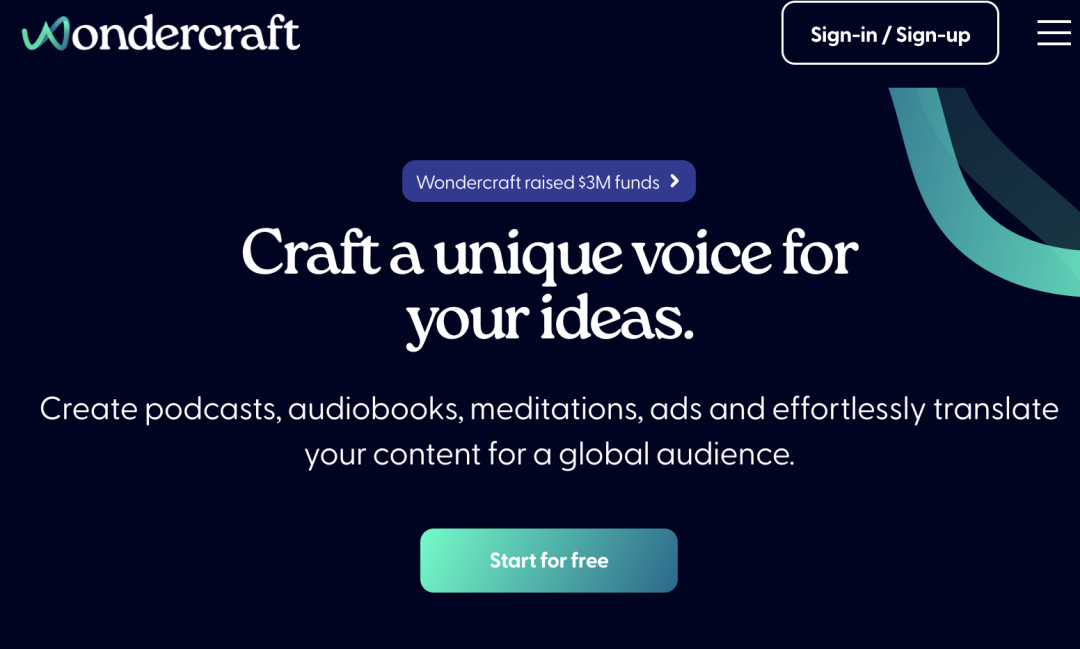
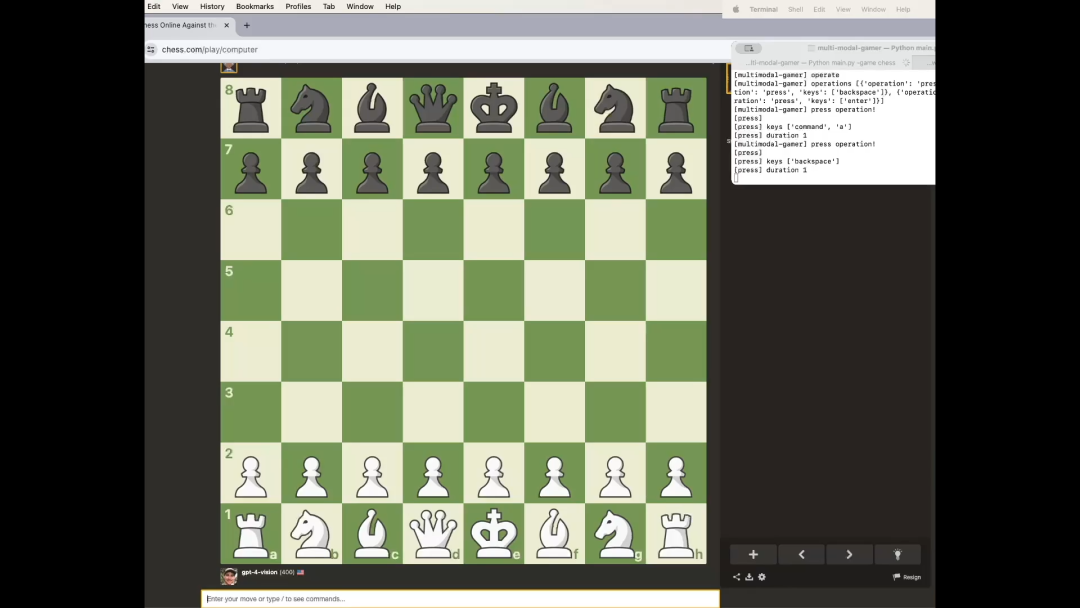
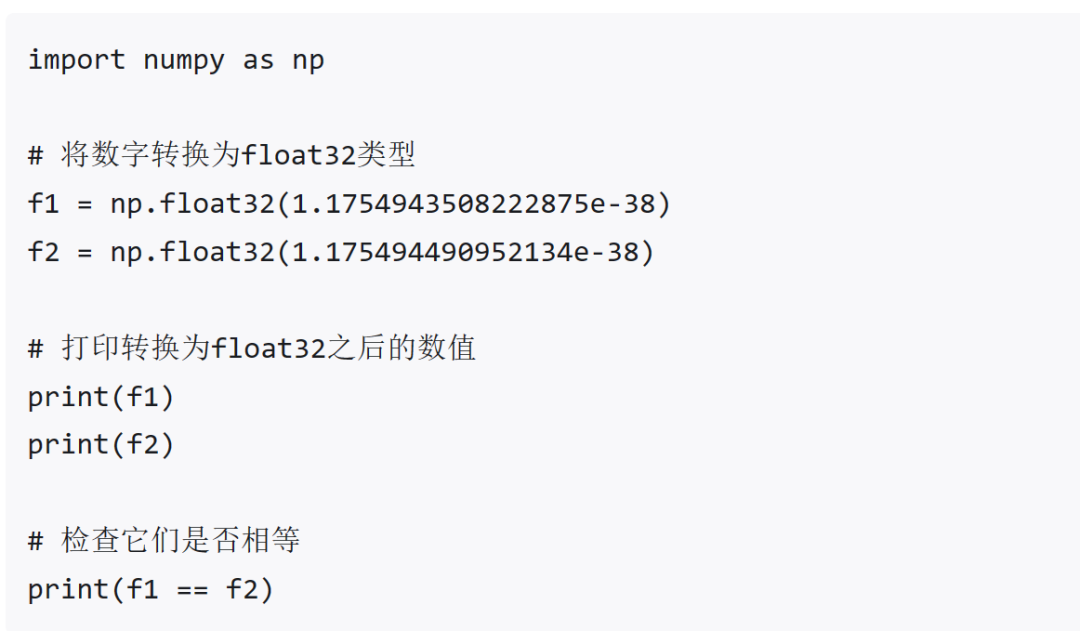
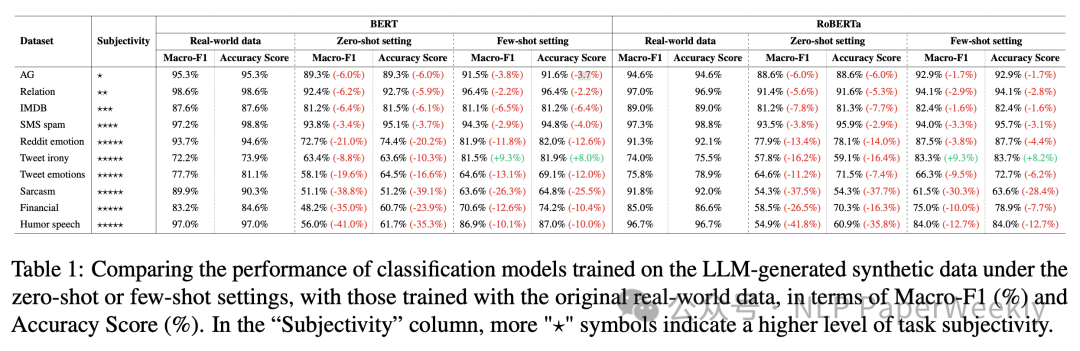
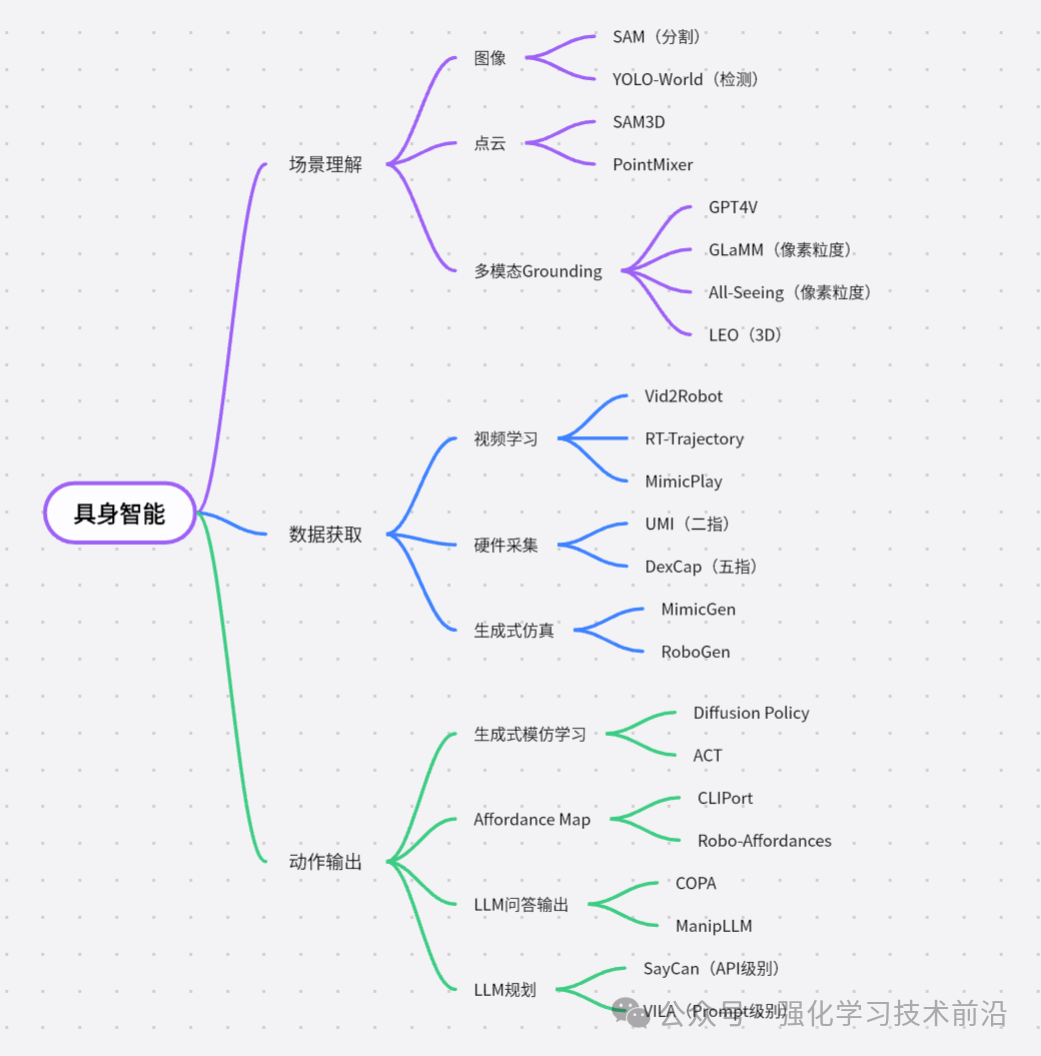
论文 稀疏模型混合:通过模型平均改进修剪的秘诀 神经网络通过剪枝显著压缩,生成稀疏模型,减少存储和计算需求,同时保持预测性能。模型汤(Wortsman等,2022)通过将多个模型的参数平均到一个单一模型中,增强泛化和超出分布(OOD)性能,而不增加推理时间。然而,既要实现稀疏性,又要进行参数平均是具有挑战性的,因为对任意稀疏模型进行平均会减少整体稀疏性。本研究通过展示,在迭代幅值剪枝(IMP)的单一重新训练阶段中探索不同的超参数配置(如批量订购或权重衰减),产生适合平均的模型,通过设计具有相同稀疏连接性。对这些模型进行平均显著增强了泛化和OOD性能。在此基础上,我们引入了稀疏模型汤(SMS),一种新颖的方法,通过从上一阶段的平均模型开始每次剪枝重新训练循环。SMS保留稀疏性,利用稀疏网络的优势,具有模块化和全并行化特性,并大大改进IMP的性能。我们进一步证明,SMS可调整以增强最先进的剪枝训练方法。 http://arxiv.org/abs/2306.16788v3 一个用于异构集群中大模型训练的调度和并行化的代码设计 联合考虑调度和自适应并行性为在异构GPU集群上训练大型模型的效率提供了巨大机会。然而,将自适应并行性整合到集群调度器中会扩展集群调度空间。这种新空间是原始调度空间和自适应并行性的并行性探索空间(也是管线,并行性、数据和张量并行性的乘积)的产物。指数级扩大的调度空间和来自自适应并行性的不断变化的最佳并行计划导致在有效集群调度中低开销和准确性性能数据获取之间的矛盾。本文提出Crius,一个用于在异构集群中高效调度多个大型模型的训练系统。Crius提出了一种称为Cell的新颖调度粒度。它表示具有确定性资源和管线阶段的作业。Cell的探索空间缩小到仅数据和张量并行性的乘积,从而展示了准确和低开销性能估计的潜力。Crius然后准确估计Cells并高效地调度训练作业。当选择一个Cell作为调度选择时,它所代表的作业将以探索出的最佳并行计划运行。实验结果显示,Crius将作业完成时间缩短了高达48.9%,并且提高了高达1.49倍的集群吞吐量。 http://arxiv.org/abs/2403.16125v1 语言修正流:用概率流推进扩散式语言生成 最近的研究表明,基于扩散语言模型成功地控制了句子属性(如情感)和结构(如句法结构)。驱动生成高质量样本的关键组件是通过数千步迭代去噪。本文提出了Language Rectified Flow(我们的方法)。我们的方法基于标准概率流模型的重构。语言修正流学习(神经)普通微分方程模型来传输源分布和目标分布,从而提供了生成建模和领域转移的统一有效解决方案。实验证明我们的方法在三个挑战性的精细控制任务和多项高质量文本编辑方面始终优于基线方法。大量实验和消融研究表明,我们的方法对许多自然语言处理任务都具有普适性、有效性和益处。 http://arxiv.org/abs/2403.16995v1 一个专家价值一个 Token: 通过专家 Token 路由将多个专家 LLM 综合成通用器 我们提出了Expert-Token-Routing,这是一个统一的通用框架,可以无缝集成多个专家LLM。我们的框架将专家LLM表示为元LLM词汇中的特殊专家token。元LLM可以路由到专家LLM,比如生成新token。Expert-Token-Routing不仅支持从现有指令数据集中学习专家LLM的隐式专业知识,还允许以即插即用的方式动态扩展新的专家LLM。它还从用户视角隐藏了详细的协作过程,使互动看起来像是一个单一的LLM。我们的框架在融合多个专家LLM的情况下优于各种现有的多LLM协作范式,在涵盖六个不同专家领域的基准测试中展示出了通过协同作用多个专家LLM建立通用主义LLM系统的有效性和稳健性。 http://arxiv.org/abs/2403.16854v1 迭代改进项目级代码上下文,以便利用编译器反馈实现精准代码生成 大语言模型(LLM)在自动生成代码方面取得了显著进展。然而,将基于LLM的代码生成应用于实际软件项目时面临挑战,因为生成的代码可能包含API使用、类、数据结构或缺少项目特定信息的错误。这篇论文提出了一种名为ProCoder的新方法,通过迭代优化项目级代码上下文,以精确生成代码,受编译器反馈指导。ProCoder首先利用编译器技术识别生成的代码与项目上下文之间的不匹配,然后通过从代码库中提取的信息迭代对齐和修复识别的错误。将ProCoder与两种代表性的LLM整合,即GPT-3.5-Turbo和Code Llama(13B),并将其应用于Python代码生成。实验结果表明,ProCoder在生成依赖于项目上下文的代码方面显著改善了基本LLM超过80%,并始终优于现有的基于检索的代码生成基线。 http://arxiv.org/abs/2403.16792v1 从损失的角度理解语言模型的涌现能力 最近的研究质疑了涌现能力只存在于大型语言模型中的信念。这种怀疑源于两个观察结果:1)较小的模型也可以展现出涌现能力的高性能,2)对用于衡量这些能力的不连续度量标准存在疑问。本文提出通过预训练损失而不是模型大小或训练计算量来研究涌现能力。我们证明,具有相同预训练损失但不同模型和数据大小的模型在各种下游任务上表现出相同的性能。我们还发现,当模型的预训练损失低于特定阈值时,该模型在某些任务上展现出涌现能力,而不受度量的连续性的影响。在达到此阈值之前,其性能保持在随机猜测的水平。这启发我们重新定义涌现能力为表现在具有较低预训练损失的模型中的能力,强调这些能力不能仅通过对具有更高预训练损失的模型的性能趋势进行外推来预测。 http://arxiv.org/abs/2403.15796v1 数据混合定律:通过预测语言建模性能优化数据混合 摘要:大语言模型的预训练数据涵盖多个领域(如网络文本、学术论文、代码),其混合比例至关重要,影响最终模型的能力。我们发现模型性能与混合比例之间存在数量可预测性,即数据混合定律。拟合这些函数可以揭示模型在未知混合情况下的表现,从而指导选择理想的数据混合。此外,我们提出嵌套使用训练步骤、模型大小和数据混合定律的缩放定律,能够仅通过小规模训练预测大规模数据下各种混合情况下大模型性能。实验结果证实,我们的方法有效优化了在RedPajama中训练的100B token的1B模型的训练混合,达到与默认混合训练了48%更多步骤的模型相当的性能。将数据混合定律应用于连续训练可以准确预测避免灾难性遗忘的关键混合比例,并展望动态数据调度的潜力。 http://arxiv.org/abs/2403.16952v1 与人类判断相一致:大语言模型评估中的两两偏好的作用 大语言模型(LLMs)已经表现出很有希望的能力,作为评估生成的自然语言质量的自动评估器。然而,LLMs在评估中仍然表现出偏见,经常难以生成与人类评估一致的连贯评价。在这项工作中,我们首先对LLM评估器和人类判断之间的不一致进行了系统研究,揭示了现有的旨在减少偏见的校准方法并不足以有效对齐LLM评估器。受RLHF中使用偏好数据的启发,我们将评估问题形式化为一个排名问题,并引入了Pairwise-preference Search (PAIRS),一种基于不确定性引导的搜索方法,利用LLM进行两两比较,高效排名候选文本。PAIRS在代表性评估任务上实现了最先进的表现,并且比直接评分取得了显著改进。此外,我们提供了对LLMs的传递性量化中两两偏好作用的见解,并展示了PAIRS如何受益于校准。 http://arxiv.org/abs/2403.16950v1 产品 AI Ad Generator AI Ad Generator 让用户通过自己的网址就可以利用 AI 技术来创造引人注目且符合品牌特色的广告标题和描述,同时确保这些广告内容符合谷歌的广告政策。通过 AI 处理广告文案,可以帮助企业节省时间和精力,让他们专注于发展业务,从而获得更高的转化率和更好的营销效果。 https://adsby.co/free-ai-ad-generator Wondercraft Wondercraft AI是一个使用生成式 AI 语音的播客构建工具,帮助用户轻松创建和发布播客。正如Canva 让每个人都能使用图形设计一样,Wondercraft 简化了音频内容的创建,允许用户通过打字、使用逼真的 AI 声音甚至他们自己的克隆声音来制作播客、有声读物、广告等。它旨在将现有内容转化为吸引人的播客,只需几分钟即可完成。 https://www.wondercraft.ai/ H uggingFace&Github InternVideo2 此存储库将即将提供“InternVideo2:扩展视频基础模型以进行多模态视频理解”的代码和模型。 https://github.com/OpenGVLab/InternVideo2/ Champ—具有 3D 参数化引导的可控且一致的人体图像动画 这项研究介绍了一种人类图像动画的方法,利用3D人体参数模型来增强当前的人类生成技术。该方法使用SMPL模型作为3D人体参数模型,结合渲染的深度图像、法线贴图、语义贴图和基于骨架的运动引导,以丰富的条件生成具有全面的3D形状和详细姿态属性的潜在扩散模型。通过多层运动融合模块,融合形状和运动潜在表征,实现高质量人体动画生成,并能准确捕捉姿势和形状变化。 https://fudan-generative-vision.github.io/champ/#/ multimodal-gamer https://github.com/joshbickett/multimodal-gamer ThemeStation 这项研究介绍了一个名为ThemeStation的新方法,用于主题感知的 3D 到 3D 生成。该方法旨在根据给定的几个示例合成具有一致主题和高度变化的自定义3D资产。通过设计一个两阶段框架,首先绘制概念图像,然后进行参考信息的3D建模阶段。作者提出了一种新的双分数蒸馏(DSD)损失,以联合利用输入示例和合成概念图像的先验知识。实验证实,ThemeStation在制作主题感知3D模型方面表现优异,质量令人印象深刻,并超越了之前的作品。此外,ThemeStation还支持可控的 3D 到 3D 生成等各种应用。 https://3dthemestation.github.io/ LLM-BioMed-NER-RE 这个存储库是对联邦学习在生物医学自然语言处理中的信息提取深度评价,包含 npj Digital Medicine 论文“An In-Depth Evaluation of Federated Learning on Biomedical Natural Language Processing for Information Extraction”的LLM评估代码。 https://github.com/GaoxiangLuo/LLM-BioMed-NER-RE 投融资 智元机器人最新融资 稚晖君的智元机器人公司,上海智元新创技术有限公司,近日完成了新一轮融资,引入红杉中国、M31资本、上汽投资为新股东,共同参与了此次融资。尽管具体融资金额未透露,但此前有消息称智元机器人的投前估值达到70亿人民币。自2023年2月成立以来,智元机器人已经连续完成了6轮融资,成为VC圈内极为受关注的项目之一。公司由90后的创始人、前华为“天才少年”和拥有250万B站粉丝的稚晖君彭志辉,以及上海交大教授闫维新共同创立,专注于人形机器人的研发与应用。 北京妥啦科技有限公司完成2000万人民币天使轮融资,估值达1.5亿 北京妥啦科技有限公司成功完成2000万人民币的天使轮融资,估值达到1.5亿人民币。这轮融资由北京船长品牌管理有限公司领投,将用于加强公司的技术研发、市场扩展以及多元化业务布局。妥啦科技成立于北京,业务范围广泛,包括技术服务、开发、咨询、交流、转让、推广,以及互联网销售、计算机系统服务、软件开发等。公司还涉足人工智能应用软件开发、专业设计服务、企业形象策划、广告设计与发布、宠物服务等业务,提供全方位服务与解决方案。此次融资将帮助妥啦科技加速技术研发和新产品推出的步伐,尤其是在人工智能和物联网应用服务领域,同时扩大市场营销力度,深化与行业合作伙伴的战略合作,全面提升品牌影响力和市场份额。 https://tech.china.com/article/20240326/032024_1497580.html AI-coustics 使用生成式 AI 对抗噪音干扰 | TechCrunch AI-coustics,一家德国初创公司,宣布以其独特的技术方法,通过生成式 AI 提升视频中声音的清晰度,成功从隐形状态走向公众并获得了190万欧元的资金。该公司的技术不仅仅是标准的噪声抑制,而是可以跨设备和扬声器工作。共同创始人兼CEO Fabian Seipel表示,AI-coustics 的使命是使每一次数字互动——无论是在会议通话、消费设备还是社交媒体视频中——都像来自专业工作室的广播一样清晰。这次融资由Connect Ventures、Inovia Capital、FOV Ventures和Ableton CFO Jan Bohl以股权和债务形式提供。 https://techcrunch.com/2024/03/25/can-you-hear-me-now-ai-coustics-to-fight-noisy-audio-with-generative-ai/ Foundational 获得800万美元投资,将AI代理引入数据工程 | Business Wire Foundational,一家通过高级分析识别和预防数据平台问题的解决方案,宣布其服务正式向公众开放,并已成功筹集800万美元种子轮资金。这一轮融资由Viola Ventures和Google的AI专注风险投资基金Gradient领投,Asymmetric Venture Partners和来自Datadog、Intuit、Meta、Wiz等公司的高管也参与了投资。Foundational利用专有的AI驱动代码分析引擎,通过git即刻部署,赋予数据和分析团队自信地进行连续的代码变更,防范频繁问题和影响关键数据的有害事件。此轮资金将帮助Foundational继续发展其技术,引入新的产品功能,支持数据开发人员在大规模建设中受益。 https://www.businesswire.com/news/home/20240325257775/en/Foundational-Secures-8M-to-Bring-AI-Agents-into-Data-Engineering Eliyan为加速AI芯片获得6000万美元资金 | VentureBeat Eliyan成功筹集到6000万美元资金,用于其芯片互联技术,旨在加速AI芯片的处理速度。这轮融资由Samsung Catalyst Fund和Tiger Global Management共同领投,目的是帮助团队解决生成式AI芯片开发的挑战。Eliyan的芯片互联技术可以将性能提升四倍,功耗减半。此外,该公司还专注于设计和制造使用多芯片架构的先进AI芯片,包括在先进封装或标准有机基板中使用,其技术允许芯片制造商实现新的性能和能效水平。 https://venturebeat.com/ai/eliyan-raises-60m-for-chiplet-interconnects-that-speed-up-ai-chips/ Buddywise 的工作场所安全 AI 募集到350万欧元种子基金 – Tech.eu 瑞典的 Buddywise 宣布成功募集到350万欧元的种子基金,旨在预防欧洲工业场所的工作事故。该公司利用机器学习和计算机视觉技术检测工作场所的安全风险,并通过收集这些风险数据来预防进一步的事故。工业客户可以将现有的摄像头基础设施连接到 Buddywise 平台,该平台通过算法分析视频内容来标记潜在风险。目前,这套 AI 视觉软件已在瑞典、芬兰、拉脱维亚和波兰的基础设施和制造场所中使用,新的资金将主要用于扩大在欧洲的业务范围和招聘。 https://tech.eu/2024/03/25/buddywise-s-ai-for-workplace-safety-raises-3-5m-seed/ Y Combinator 计划筹集20亿美元创业基金 在CEO Garry Tan的指导下,Y Combinator(YC)正计划进行其首次重大募资活动,目标是筹集至少20亿美元,用于未来对有前景的初创企业进行投资。这表明YC对各个行业,尤其是以技术为中心的公司的长期合作投资兴趣,同时Tan也表示愿意考虑非传统科技领域的企业。通过建立三个新基金,YC的初步目标是通过吸引潜在投资者来筹集20亿美元,但进行中的谈判表明最终金额可能超过这一目标。此举展示了Tan对促进创新和培育有前景初创企业的承诺,进一步巩固了YC作为领先孵化器的地位。 https://www.devx.com/news/y-combinator-aims-for-2-billion-startup-fund/ 学习 【LLM-数学】MathGenie:利用问题反向翻译生成合成数据来增强LLM的数学推理能力 文章介绍了一个创新的流程,该流程通过迭代解决方案增广、问题反向翻译和基于验证的解决方案过滤三个步骤,生成大规模合成数学问题来提升语言模型的数学推理能力。这个流程有效地结合了种子数据和候选解决方案生成模型,利用了Llama-2 70B模型和Dcode技术,通过微调和验证策略,生成了170K个问题及其解决方案。实验结果显示,MathGenieLM在数学问题解决基准上表现卓越,但需要大量GPU资源,并且不能处理图像输入问题。 h ttps://zhuanlan.zhihu.com/p/688779138 再谈float32数据格式的精度问题 文章深入探讨了float32数据类型的精度特性,特别是如何根据数值的大小和表示方式影响其精度。文章通过IEEE 754标准解释了float32的构成,包括1位符号位、8位指数位和23位尾数位,并通过例子展示了如何将浮点数转换为IEEE 754标准的二进制表示。重点讨论了浮点数精度在不同情况下的变化:当数值较大时,精度可能降低到小于6位小数;而在表示非常小的数或非规范化数时,精度可高达数十位。文章还探讨了非规范化数的表示和处理,强调了float32数据类型在实际应用中精度的动态范围,以及如何通过具体的编码实践来验证这些精度特性。 https://zhuanlan.zhihu.com/p/689045851 利用LLM合成数据训练模型有哪些坑? 文章探讨了使用大型语言模型(LLMs)生成合成数据来训练文本分类模型的潜力与局限。通过分析10个文本分类任务数据集及采用BERT和RoBERTa作为基座模型的实验,发现合成数据在支持模型训练方面的有效性与任务的主观性(标注一致性)紧密相关。具体而言,任务主观性越高,利用LLMs生成的合成数据训练模型的效果越差。此外,研究指出合成数据的有效性关键取决于生成数据的多样性,而few-shot生成方式相比zero-shot可以提高样本的多样性,从而在某种程度上增强模型训练的有效性。这项工作强调了在利用LLMs生成合成数据支持模型训练时,需要考虑任务主观性和数据多样性的影响。 未来通用机器人操作技术路线 文章探讨了通用机器人操作技术的未来发展路线,特别强调了如何桥接像素级信息(Pixels)与机器人操作(Manipulation)的重要性。介绍了利用Affordance Map将像素级地面信息和操作行为连接起来的方法,通过展示“Robo Affordances”和“ManipVQA”两篇论文,说明了如何实现物体的识别、抓取以及执行后续操作。关键技术包括通过视觉语言模型(VLM)根据文本提示关注不同功能属性,例如抓取刀柄(Hold)或关注刀身(Cut)。此外,提到了Affordance Map在获取Ground Truth时面临的挑战,如人工标注的工作量大、通过DexCap等遥操作设备采集的数据难以自动化提取关键信息。最后,提及了通过人物对象交互检测从视频中学习作为一种可行方法,尽管这种方法难以获取更精细的操作所需的Affordance Map。 项目地址:https://github.com/yunlongdong/Awesome-Embodied-AI AI服务器专家交流纪要 文章讨论了国内对英伟达推理卡(如A30、A40、L40)的需求情况,指出需求量巨大且预计会进一步增长。当前,H20和L20是国内可获取的主要产品,其中H20基于hopper架构,具有优异的性能,主要用于推理任务。2024年市场预测认为,如果技术和政策环境稳定,H20、L20等卡片能够满足市场需求。然而,国内产品与英伟达最新产品的性能差距预计将增大。此外,英伟达显卡的国内价格高昂,如H100P3E卡约245,000元,RTX 4090卡价格上涨至20,000元。对于AI服务器市场,国内主要竞争者包括浪潮、新华三等,浪潮在GPU算力服务器领域的占有率显著,但受技术限制和交付问题影响。最后,文中还提及了国内服务器企业的竞争格局,指出浪潮等公司在AI服务器领域的毛利率相对较高。
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/03/16662.html