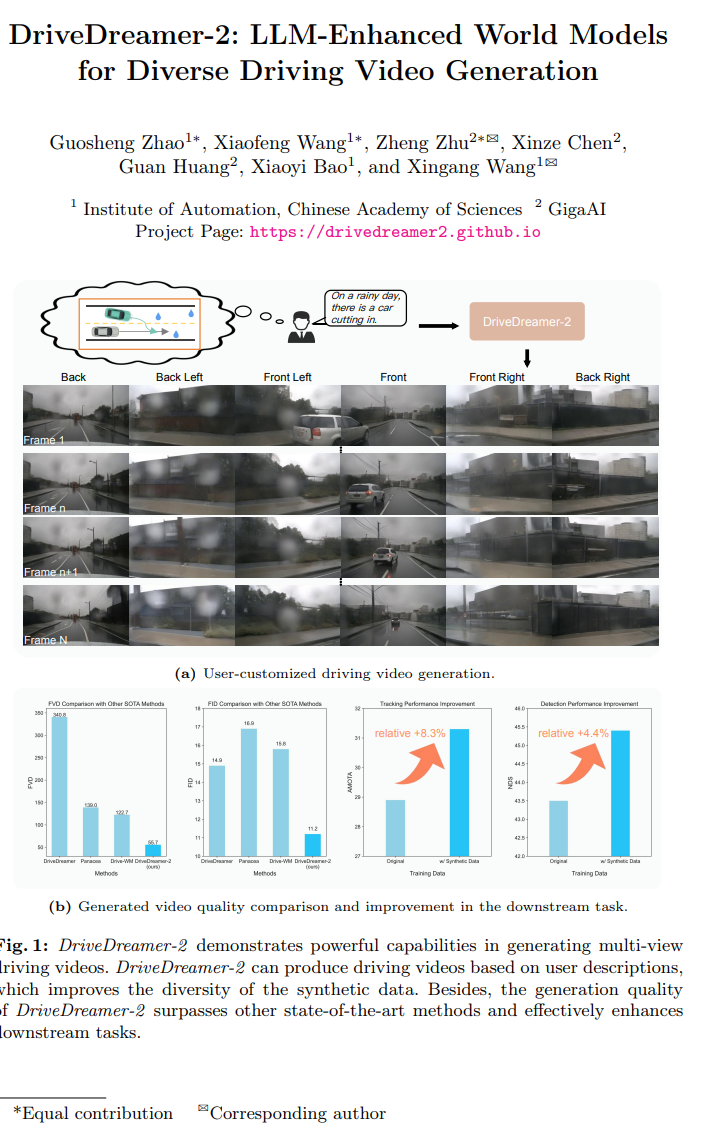
2024 开年,OpenAI 就在生成式 AI 领域扔下了重磅炸弹:Sora。这几年,视频生成领域的技术迭代持续加速,很多科技公司也公布了相关技术进展和落地成果。在此之前,Pika、Runway 都曾推出过类似产品,但 Sora 放出的 Demo,显然以一己之力抬高了视频生成领域的标准。在今后的这场竞争中,哪家公司将率先打造出超越 Sora 的产品,仍是未知数。这篇文章将介绍来自字节跳动智能创作团队的 9 项研究,涉及文生图、文生视频、图生视频、视频理解等多项最新成果。我们不妨从这些研究中,追踪探索视觉生成类模型的技术进展。https://mp.weixin.qq.com/s/dYfh57A-3b7f0M6yx-pfCQ02
兼具精度与效率
微软基于AI的新电子结构计算框架M-OFDFT登Nature子刊
近几十年来,理论与计算化学领域取得的一大成就是能够通过计算手段得到分子体系的物理化学性质。这为药物发现和材料设计等诸多工业界问题带来了全新的研究手段,有望缩短开发流程并降低开发成本。这些计算方法的基础步骤是使用电子结构方法求解给定分子体系的电子状态,进而得到该体系的各种性质。然而,各种电子结构方法的求解精度和计算效率往往无法兼得。当前,取得相对合理的「精度-效率」权衡而被广泛应用的方法是Kohn-Sham形式的密度泛函理论(Kohn-Sham density functional theory, KSDFT)。但KSDFT具有较高的计算复杂度,不能很好地满足日益增长的求解大规模分子体系的需求。为此,微软研究院科学智能中心的研究员们提出了一种基于深度学习和无轨道密度泛函理论(OFDFT)的电子结构计算框架M-OFDFT,其不仅显著超越了KSDFT的计算效率,还能保有其求解精度。这一成果展示了人工智能在提升电子结构计算中「精度-效率」权衡方面的卓越能力,并将助力加速相关业界问题的研究与开发。https://mp.weixin.qq.com/s/dMrQEIeimXcN-4yIDoDt0A03
Nature子刊综述
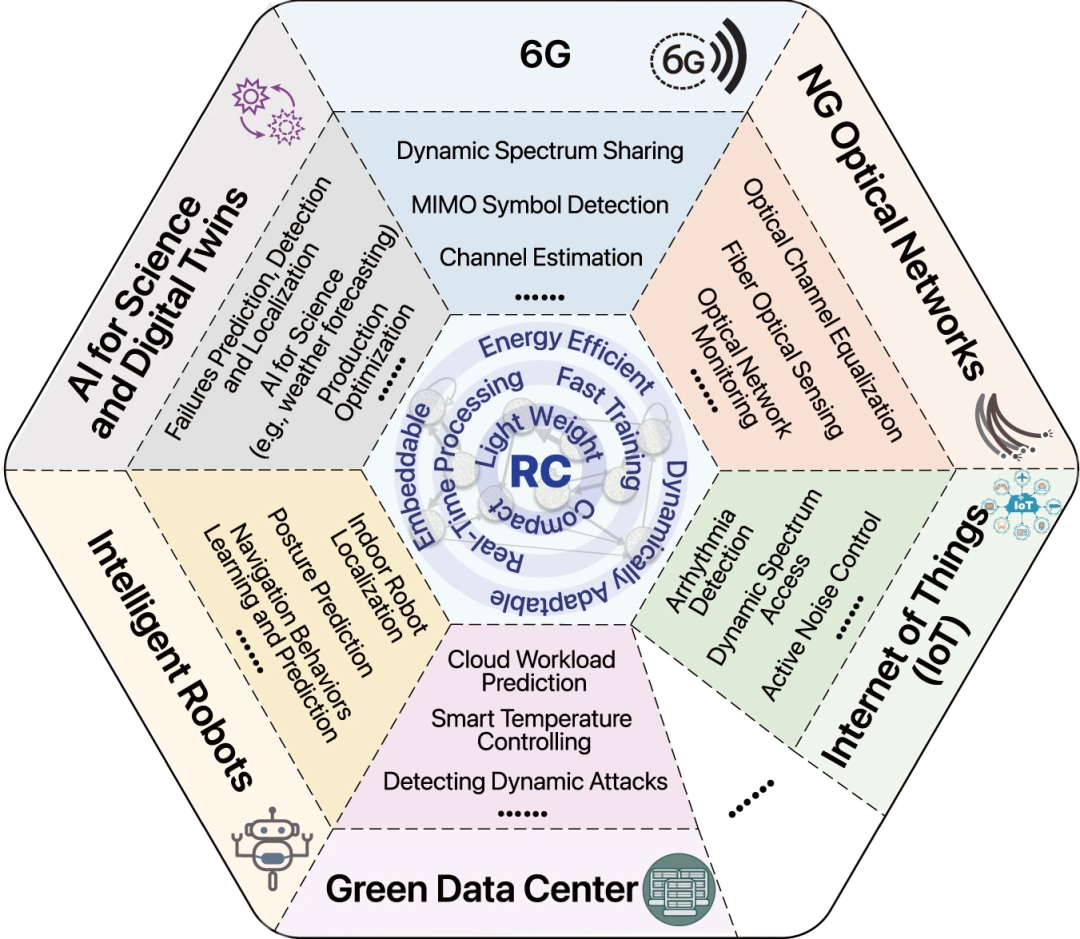
储层计算未来的新机遇和挑战,华为联合复旦等发布
尽管深度学习在处理信息方面取得了巨大成功,但其依赖于训练大型神经网络模型,限制了其在常见应用中的部署。因此,人们对开发能快速推理和快速适应的小型轻量级模型的需求日益增长。作为当前深度学习范式的替代方向,神经形态计算研究引起了人们的极大兴趣,其主要关注开发新型计算系统,这些系统的能耗只有当前基于晶体管的计算机的一小部分。在神经形态计算中,一个重要的模型家族是储层计算(RC),储层计算起源于 21 世纪初,它在过去的二十年中取得了重大进展。为了释放储层计算的全部功能,为时态动力系统提供快速、轻量级且可解释性更高的学习框架,需要进行更多的研究。近日,华为联合复旦大学、伯明翰大学和根特大学(Ghent University)在《Nature Communications发表题为《Emerging opportunities and challenges for the future of reservoir computing的 Perspective 文章。https://mp.weixin.qq.com/s/weSQN7uYQ7LKfFWd2e1BTA 04
微软宣布将于 3 月 21 日举办一场活动,重点展示其即将推出的生成式 AI 设备和功能。题为“Advancing the new era of work with Copilot”的活动将于美东时间中午 12 点开始。Surface Pro 10 和 Surface Laptop 6 预计将成为首批支持 Windows 11 中即将推出的 AI 功能的机器之一,这些功能包括设备上的 Copilot 功能、新的实时实时字幕和翻译功能、视频游戏升级和帧速率平滑、增强的Windows Studio 效果以及内部称为“AI Explorer”的新功能。https://mp.weixin.qq.com/s/2aKd1q0hUT24bRMiYiINPw 06
OpenAI开源了:Transformer自动debug工具上线GitHub
今天一早,OpenAI 机器学习研究员 Jan Leike宣布,OpenAI 开放了自己内部一直用于分析 Transformer 内部结构的工具。该项目开放才几个小时,虽然没有经过太多宣传,star 数量上涨得也挺快。Transformer Debugger (TDB) 是 OpenAI 对齐团队(Superalignment)开发的一种工具,旨在支持对小体量语言模型的特定行为进行检查。据介绍,该工具把自动可解释性技术与稀疏自动编码器进行了结合。具体来说,TDB 能够在需要编写代码之前进行快速探索,并能够干预前向传递,帮助人们查看它是如何影响模型特定行为的。TDB 可用于回答诸如「为什么模型在此提示(prompt)中输出 token A 而不是 token B?」之类的问题或「为什么注意力头 H 会在这个提示下关注 token T?」https://mp.weixin.qq.com/s/HklR73Bxkcmzm48KaxyG2Q
Eric Hartford:我写了一个小脚本,可以帮你将GitHub仓库的内容导出到一个文件中,这样你就可以把它粘贴到Claude或Gemini-1.5中,让它帮你修复所有的bug,或者将其移植到Rust或COBOL,或其他任何语言。https://x.com/erhartford/status/1767284737788514724?s=20
02
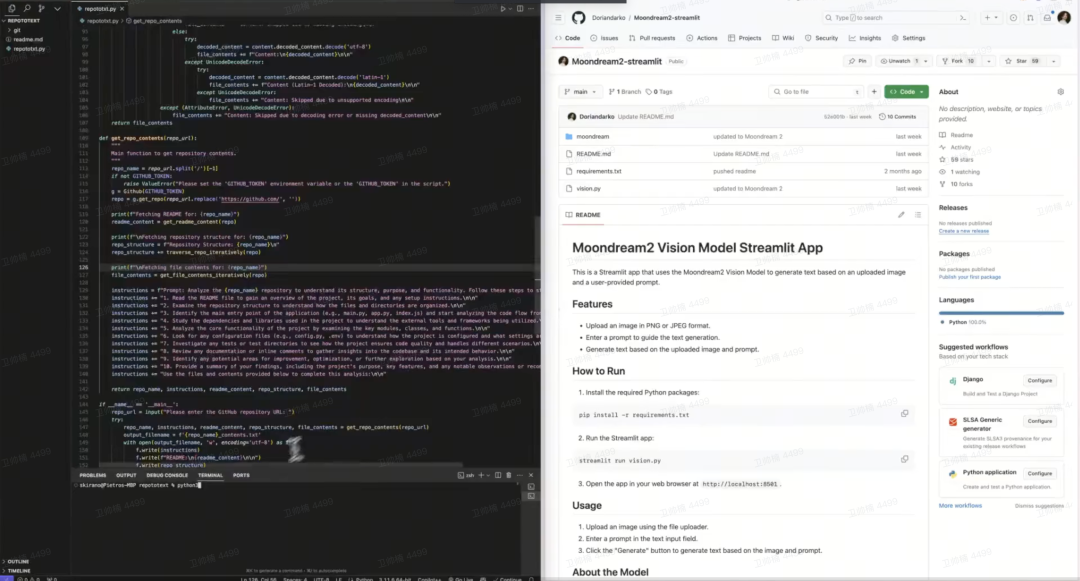
Schirano分享RepoToTextForLLM
快速将GitHub仓库转换为文本文件
Pietro Schirano:在长上下文大语言模型(LLM)时代,我需要一种方法能够快速地将GitHub仓库转换为文本文件,以便作为提示输入。现在介绍一下RepoToTextForLLMs,它不仅能将整个仓库内容合并为一个文件,还能在文件末尾附加一个超级提示,以便进行分析和理解。Schirano评论和楼上撞车的工具:
哈哈,典型啊!我刚看了他的仓库,似乎是一种完全不同的方法。很高兴我们能在同一个问题上有这种多样性的思路。
移动设备和社交媒体的大量普及彻底改变了内容传播,短视频越来越普遍。这种转变带来了视频重构的挑战,使其适应不同的屏幕长宽比,突出视频中最引人注目的部分。传统上,视频重构是一个需要专业知识且耗时的手动任务,导致高昂的生产成本。一种潜在的解决方案是采用一些机器学习模型,如视频显著对象检测,来自动化这一过程。然而,由于这些方法依赖于特定的训练数据,它们通常缺乏泛化能力。功能强大的大型语言模型(LLMs)的出现为人工智能能力开辟了新的途径。在此基础上,我们介绍了基于LLM的Reframe Any Video Agent (RAVA),它利用视觉基础模型和人类指令来重新构建视频内容进行视频重构。RAVA分为三个阶段运作:感知阶段,解释用户指令和视频内容;规划阶段,确定长宽比和重构策略;执行阶段,调用编辑工具生成最终视频。我们的实验验证了RAVA在视频显著对象检测和真实世界重构任务中的有效性,展示了它作为AI视频编辑工具的潜力。http://arxiv.org/abs/2403.06070v105



 https://mp.weixin.qq.com/s/dYfh57A-3b7f0M6yx-pfCQ
https://mp.weixin.qq.com/s/dYfh57A-3b7f0M6yx-pfCQ