欢迎观看大模型日报 , 如 需 进 入 大 模 型 日 报 群 和 空 间 站 请 直 接 扫 码 。 社 群 内 除 日 报 外 还 会 第 一 时 间 分 享 大 模 型 活 动 。
推特 私密马赛妈妈酱,瓦塔西哇要去远航:OpenAI推出针对日语优化 GPT-4 定制模型 OpenAI 宣布在亚洲设立第一个办事处 – OpenAI 日本,同时推出一个专门针对日语进行优化的全新 GPT-4 定制模型。 https://openai.com/blog/introducing-openai-japan… https://x.com/OpenAI/status/1779754674242892014
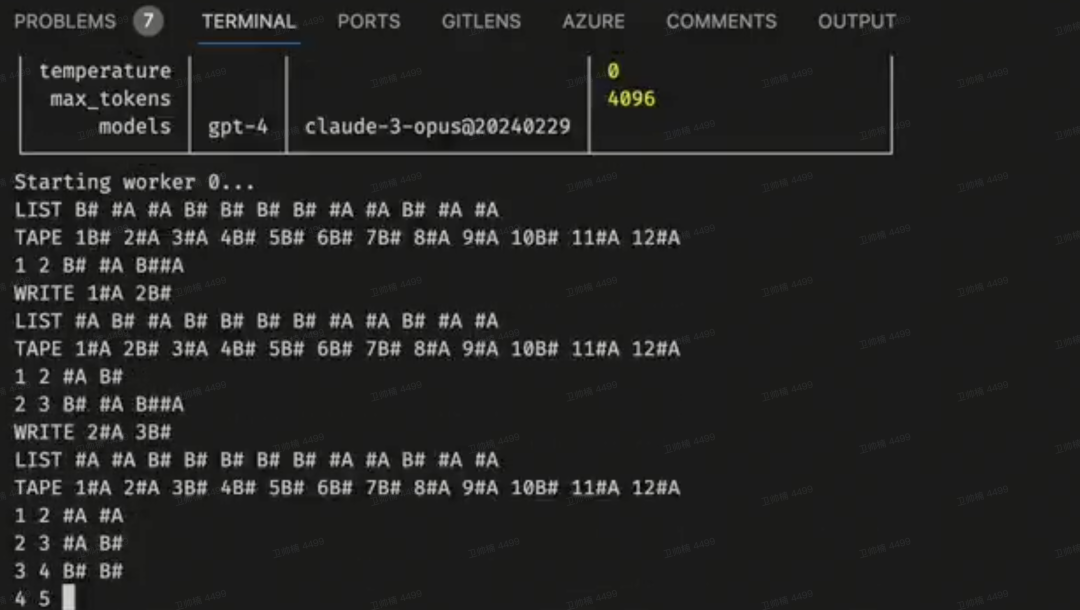
Opus模拟图灵机器,给定现有磁带,学习规则并计算出新序列
Opus 可以作为一台图灵机运行。
只需给定现有的磁带,它就能学习规则并正确计算出新的序列。
在 500 多个 24 步的解决方案中,准确率达到 100%(还有更多测试正在进行)。
要在 24 步内达到 100% 的准确率,输入磁带的权重为 30k tokens*。
GPT-4 无法做到这一点。
https://x.com/ctjlewis/status/1779740038852690393
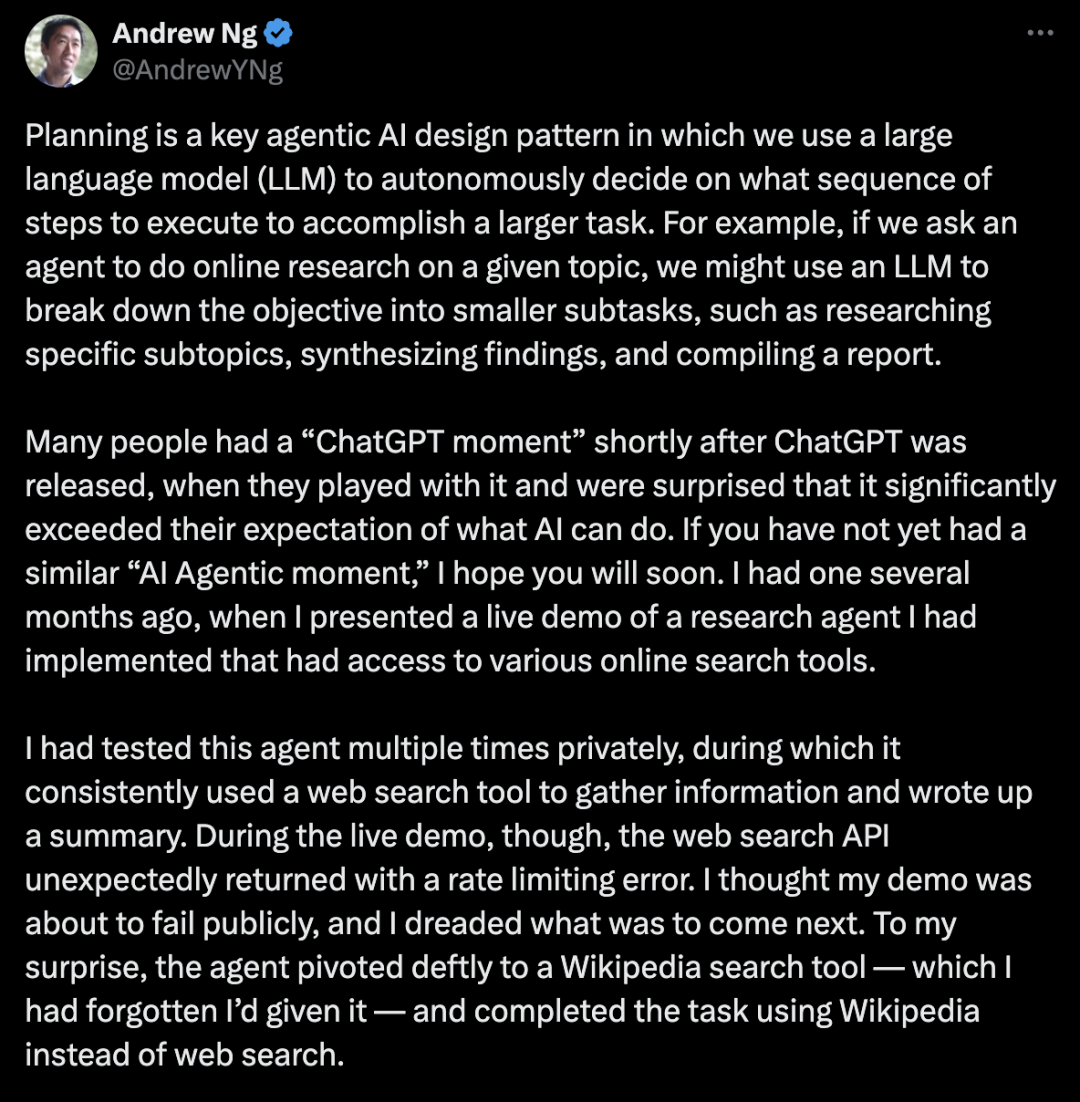
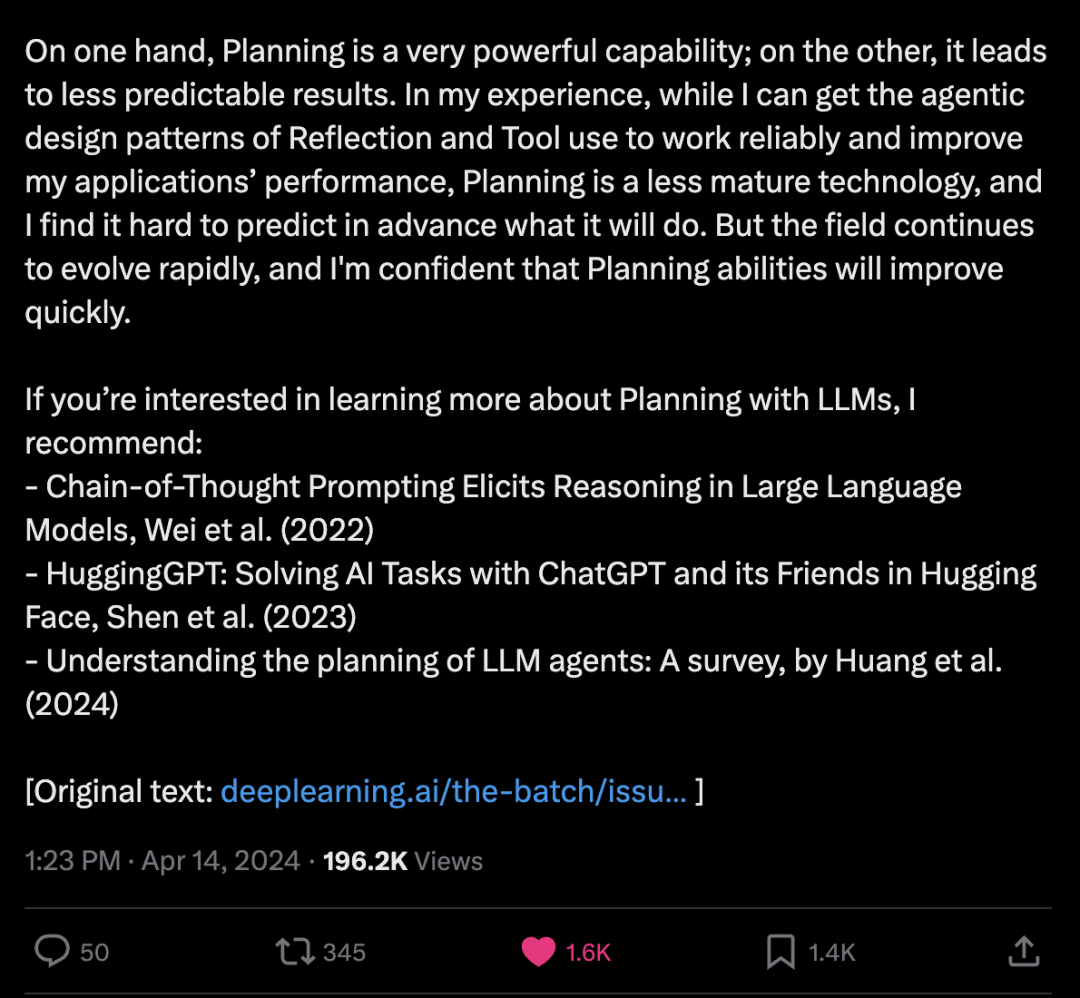
吴恩达谈规划:一个主动式AI设计模式;许多任务不能在单个步骤或单个工具调用中完成,但智能体可以决定采取什么步骤 规划是一个关键的主动式AI设计模式,其中我们使用大型语言模型(LLM)来自主决定执行什么样的步骤序列来完成一个更大的任务。例如,如果我们要求一个智能体对给定的主题进行在线研究,我们可以使用LLM将目标分解为更小的子任务,例如研究特定的子主题、综合调查结果以及编写报告。 在ChatGPT发布后不久,许多人都有一个”ChatGPT时刻”,当他们使用ChatGPT并惊讶地发现它大大超出了他们对AI能力的预期。如果你还没有类似的”AI主动式时刻”,我希望你很快就会有。几个月前,我有过一次这样的经历,当时我展示了一个我实现的研究智能体的现场演示,该智能体可以访问各种在线搜索工具。 我曾经多次私下测试过这个智能体,在测试过程中,它始终使用网络搜索工具来收集信息并写出总结。但在现场演示中,Web搜索API意外地返回了一个速率限制错误。我以为我的演示即将公开失败,我害怕接下来会发生什么。令我惊讶的是,智能体灵活地转向了维基百科搜索工具——我已经忘记我给它提供了这个工具——并使用维基百科而不是网络搜索完成了任务。 这对我来说是一个令人惊讶的AI主动式时刻。我认为许多还没有经历过这样时刻的人将在未来几个月内经历它。当你看到一个智能体自主决定以你没有预料到的方式做事,并因此获得成功,这是一件很美好的事情! 许多任务不能在单个步骤或单个工具调用中完成,但智能体可以决定采取什么步骤。例如,为了简化HuggingGPT论文(如下所引)中的一个例子,如果你想让一个智能体考虑一张男孩的图片,并以相同的姿势画一张女孩的图片,任务可能被分解为两个不同的步骤:(i)检测男孩图片中的姿势,以及(ii)渲染一张在检测到的姿势下的女孩图片。LLM可能通过微调或提示(使用少样本提示)来指定一个计划,输出一个格式如”{tool: pose-detection, input: image.jpg, output: temp1 } {tool: pose-to-image, input: temp1, output: final.jpg}”的字符串。 这个结构化的输出指定了要采取的两个步骤,然后触发软件依次调用姿势检测工具和姿势到图像工具来完成任务。(这个例子仅用于说明目的;HuggingGPT使用不同的格式。) 诚然,许多主动式工作流不需要规划。例如,你可能让智能体对其输出进行固定次数的反思和改进。在这种情况下,智能体采取的步骤序列是固定的和确定的。但对于那些你无法事先将任务分解为一组步骤的复杂任务,规划允许智能体动态地决定要采取什么步骤。 一方面,规划是一个非常强大的能力;另一方面,它会导致不太可预测的结果。根据我的经验,虽然我可以让反思和工具使用这两个主动式设计模式可靠地工作并提高我的应用程序的性能,但规划是一项不太成熟的技术,我发现很难提前预测它会做什么。但该领域继续快速发展,我相信规划能力将迅速提高。 如果你有兴趣了解更多关于使用LLM进行规划的信息,我推荐:
连锁思维提示引发大型语言模型的推理,Wei等人(2022年)
HuggingGPT:使用ChatGPT及其在Hugging Face中的朋友解决AI任务,Shen等人(2023年)
理解LLM智能体的规划:一项调查,Huang等人(2024年)
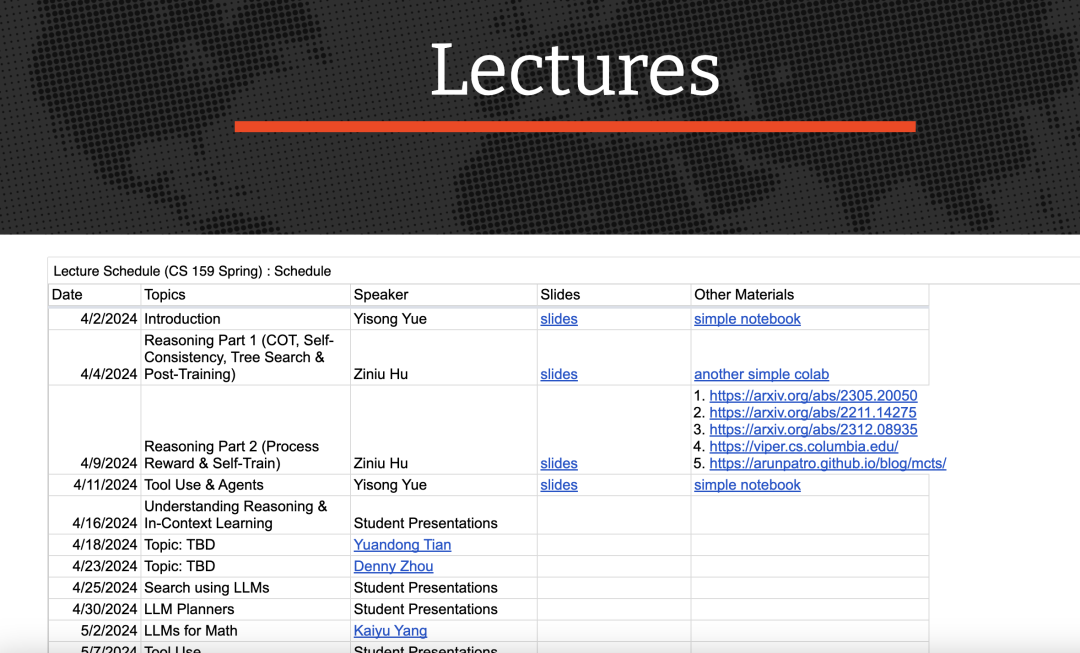
https://x.com/AndrewYNg/status/1779606380665803144 Jarovsky谈德国联邦信息安全办公室“生成式AI模型-工业和政府机构的机遇与风险”:应特别注意用户意识、测试、敏感数据 AI政策警示:德国联邦信息安全办公室发布了题为”生成式AI模型-工业和政府机构的机遇与风险”的报告。引言和评论:”LLM是基于海量文本语料库训练的。由于数据量巨大,这些文本的来源和质量通常没有得到全面验证。因此,训练集中可能包含个人或受版权保护的数据,以及内容可疑、虚假或具有歧视性的文本(例如虚假信息、宣传或仇恨言论)。在生成输出时,这些内容可能原封不动或略有改动地出现在输出中(Weidinger等人,2022年)。训练数据中的不平衡也可能导致模型产生偏差”(第9页)。 “如果个别数据点在训练数据中所占比例过高,就有可能导致模型无法充分学习所需的数据分布,并且根据程度不同,倾向于产生重复、片面或不连贯的输出(称为模型崩溃)。预计未来这一问题会越来越多地出现,因为LLM生成的数据在互联网上变得越来越容易获得,并被用于训练新的LLM(Shumailov等人,2023年)。这可能导致自我强化效应,在生成具有滥用潜力的文本或文本数据中的偏差根深蒂固的情况下尤其如此。例如,随着越来越多的相关文本被制作出来并再次用于训练新模型,而新模型又会生成大量文本(Bender等人,2021年)”(第10页)。 “模型输出的高语言质量,再加上通过API进行用户友好访问,以及当前流行的LLM的回应具有巨大的灵活性,这使得罪犯更容易滥用这些模型,有针对性地生成错误信息(De Angelis等人,2023年)、宣传文本、仇恨言论、产品评论或社交媒体帖子。” https://x.com/LuizaJarovsky/status/1779494839622459505 Yiyue Song教授公开Caltech LLM课程 CS159:Caltech的大语言模型(LLM)用于推理的课程讲义非常棒。链接: https://sites.google.com/view/cs-159-2024/lectures 感谢 @yisongyue 和 @acbuller 公开这些资料。 https://x.com/DevanVarun/status/1779544654771572839 作家Daniel Jeffries分享使用AI编程引千人围观:很有意思,但不能代替程序员 Daniel Jeffries分享了使用AI进行编程的亲身经历和感悟。他尝试用AI编写了一个复杂的应用程序,期间经历了情绪的起伏,既有惊喜也有沮丧。他发现AI生成的代码虽然能从无到有,但仍存在许多问题,如不安全、不可维护、无法扩展等,需要人工修复。 作者将AI编程的发展比作网站开发技术的演进。每一次技术进步都让更多人能够创建出优质的网站,但并没有淘汰专业团队,反而让网站变得更加复杂和强大。同样,AI会让更多人能够编程,降低入门门槛,但熟练的程序员仍然具有优势,因为他们更清楚如何利用AI工具,以及如何判断代码质量。 作者还分享了使用Playwright和Beautiful Soup等工具包的经验,尽管他并不熟悉这些工具的使用方法,但在AI的帮助下,他很快就获得了能够正常工作的代码。这让他感到惊喜和振奋。 最后,作者鼓励人们继续学习计算机科学、IT和系统工程等相关知识,因为掌握良好的架构、可扩展性和安全性知识,将有助于更好地使用AI工具。他认为AI只是另一个工具,并不会取代人类程序员,反而会让优秀的程序员更加抢手。展望未来,想象力和创造力将成为关键。 总的来说,这篇文章表达了作者对AI在编程领域应用的乐观态度,分享了他的真实体验和感悟,给出了对程序员未来发展的建议,同时也强调了人工智能只是一种工具,不能完全替代人类程序员,优秀的程序员在AI时代仍大有可为。 https://x.com/Dan_Jeffries1/status/1779472810412286335 Shah分享开源SuperMemory:构建你自己的第二大脑,书签的ChatGPT 使用SuperMemory构建你自己的第二大脑。它就像是你书签的ChatGPT。使用Chrome扩展程序导入推文或保存网站和内容(网上应用商店中的扩展程序未更新,请使用仓库中的扩展程序)。 实际上,我和@yxshv在互联网上保存了大量的内容。 但我们从不回顾这些内容——对我们来说,这就像是把信息扔进虚空。 https://x.com/DhravyaShah/status/1779678999314149755 Paliwal分享Insight:AI可穿戴设备,使用Genimi1.5Pro,黑客松中完成 Advait Paliwal:在本周末的 @GoogleX @mhacks 黑客马拉松上,我用身边闲置的树莓派制作了一个名为 Insight 的 AI 可穿戴设备。 Insight 使用 Gemini 1.5 Pro 根据你所看到和听到的内容来回答问题,并且它会为你记住这些记忆。 https://x.com/advaitpaliwal/status/1779697730526310521 Rahul为Devin辩护:这里的大部分批评都是你从一个高级工程师那里听到的,他在你身后监视着你,不断地否定你 我要在这里为Devin和他的团队辩护。这里的大部分批评都是你从一个高级工程师(恐龙)那里听到的,他在你身后监视着你,不断地否定你。他的大部分论点完全被认为是稻草人论证:
Devin使用了错误版本的PyTorch(知识截止问题,这很明显)
“完成这项任务用了36分钟,但Devin却花了6个小时”(我认为公平的比较应该是一个普通的Upwork任务人员需要多长时间来完成这项任务)
Devin本可以阅读README(说明手册)并通过一个命令节省安装时间。(老实说,谁会这样做呢?任何优秀的工程师都会直接开始使用这个东西并找出漏洞,而不是一字不差地遵循说明手册)
https://x.com/0interestrates/status/1779268441226256500 资讯 刷爆多模态任务榜单!贾佳亚团队Mini-Gemini登热榜,代码、模型、数据全部开源 更高清图像的精确理解、更高质量的训练数据、更强的图像解析推理能力,还能结合图像推理和生成,香港中文大学终身教授贾佳亚团队提出的这款多模态模型 Mini-Gemini 堪称绝绝子,相当于开源社区的 GPT4+DALLE3 的王炸组合! 多篇顶会一作却申博失败?斯坦福博士生亲述:AI领域太卷 「尽管我在顶级 ML 会议上发表了多篇一作论文,为开源项目做出了贡献,也在业界产生了影响,但我仍在为进入博士课程而苦苦挣扎。我被顶尖大学拒之门外,感到迷茫和疲惫。」「我开始怀疑自己,怀疑如果没有合适的人脉或家庭背景,光有强大的研究背景是否还不够。我正在考虑放弃攻读博士学位以及从事有价值研究的梦想。」在刚刚过去的周末,关于「AI 博士申请条件卷上天」的帖子成为了 Reddit 社区讨论的焦点。这个帖子的作者在 EMNLP、NeurIPS、ACM、ACL 等顶级会议和研讨会上以第一作者发表了多篇研究论文,也被公司评为过最佳 NLP 研究员。 陶哲轩力荐、亲自把关:AI for Math照这个清单学就对了 刚刚,著名数学家陶哲轩的个人博客又更新了,这次他们整理了一份有用的资源列表,该资源专注于 AI for Math,专为那些希望进入数学 AI 领域的人提供帮助。这份清单发起时间最早可追溯到去年,发起机构由美国国家科学院、工程院和医学院组织的研讨会「人工智能辅助数学推理」提出,陶哲轩担任研讨会主持人。 前谷歌大佬、Transformer之父打造“企业大脑”,英伟达、AMD和谷歌等科技巨头投资近亿美金 Transformer作为一种新的神经网络架构,由Google的研究人员Vaswani等人在2017年提出。它主要依靠自注意力机制来处理序列数据,显著提升了处理速度和效率,尤其在自然语言处理任务中展现出卓越性能。随着BERT和GPT系列模型的开发,在企业服务市场也得到文本翻译、内容推荐、情感分析等方面的广泛应用,助力企业提高自动化程度、优化用户体验和决策效率。Ashish Vaswani和Niki Parmar作为《Attention is All You Need》的共同第一作者,有着“Transformer之父”的称号。二人在离开谷歌后联手创建Essential AI,旨在深化人类与计算机间的合作,通过“企业大脑”的概念颠覆现有企业发展模式,让AI展示出超越现今的协作能力。 一阶优化算法启发,北大林宙辰团队提出具有万有逼近性质的神经网络架构的设计方法 北京大学林宙辰教授团队提出了一种易于操作的基于优化算法设计具有万有逼近性质保障的神经网络架构的方法,其通过将基于梯度的一阶优化算法的梯度项映射为具有一定性质的神经网络模块,再根据实际应用问题对模块结构进行调整,就可以系统性地设计具有万有逼近性质的神经网络架构,并且可以与现有大多数基于模块的网络设计的方法无缝结合。论文还通过分析神经网络微分方程(NODE)的逼近性质首次证明了具有一般跨层连接的神经网络的万有逼近性质,并利用提出的框架设计了 ConvNext、ViT 的变种网络,取得了超越 baseline 的结果。论文被人工智能顶刊 TPAMI 接收。 AI+音频社交|Airchat,硅谷i人的微信,还是下一个Clubhouse? Airchat是由 Tinder 前首席产品官 Brian Norgard 和硅谷知名投资人 Naval Ravikant 共同开发的新型对话网络应用,旨在通过一种独特的连接方式改变社交媒体世界里。根据其官方 X 账号的信息,iOS 版本的测试已经结束,安卓版本的测试即将开始。与其他社交媒体应用一样,Airchat 是免费使用的。目前 Airchat 仅限受邀者参与,其在 Apple App Store 社交应用中排名第 27 位。 人在B站,要被AI公司们挤爆了 现在,AI大模型公司们有了新的必争高地——把流量打出去,普通用户抢过来。例如现在逛个B站,画风简直就是“五步一AI,十步一AIGC”。2024年开年,AI公司投放的整体费用有明显增长,也有公司为此扩充了市场营销团队。以AI潜在用户群体最为集中的B站为例,头部AI厂商及市面常见AI产品几乎已经全部入局,旺盛的需求导致内容“供不应求”,不少科技UP主档期被约满,多次出现品牌抢单的情况。业内人士保守估计,仅仅在B站,品牌方今年的广告投入就是去年的3 到 4 倍。甚至有AI厂商特意从拼多多挖人负责B站的投放。嗯,不得不说,AI大模型公司们已经在开展激烈的营销商战了,年轻用户恰是他们的主要目标。作为年轻人密度最高的B站,必然是这场“战役”的桥头堡,当然,还有更多社交媒体平台,也都在印证着这点。 北大字节开辟图像生成新范式!超越Sora核心组件DiT,不再预测下一个token 北大和字节联手搞了个大的:提出图像生成新范式,从预测下一个token变成预测下一级分辨率,效果超越Sora核心组件Diffusion Transformer(DiT)。并且代码开源,短短几天已经揽下1.3k标星,登上GitHub趋势榜。实验数据上,这个名为VAR(Visual Autoregressive Modeling)的新方法不仅图像生成质量超过DiT等传统SOTA,推理速度也提高了20+倍。 https://mp.weixin.qq.com/s/LKDU629r4qn0925P46lEgA
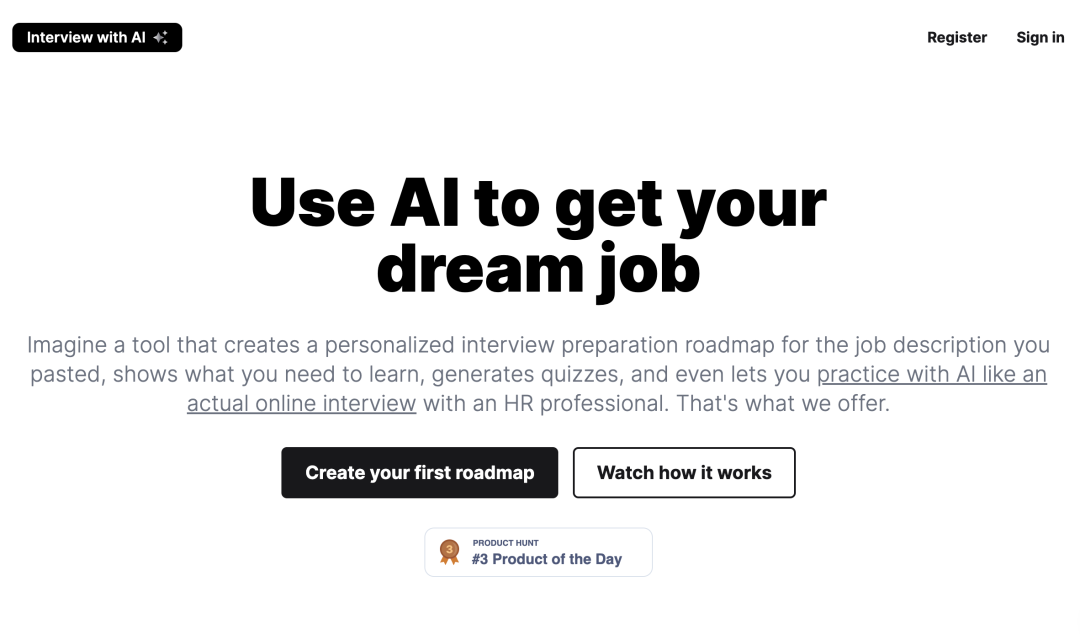
产品 Interview with AI 该工具可以为用户描述的职位创建个性化的面试准备路线图,并使用人工智能进行面试练习,用户可以针对包括面试的形式、个性化程度以及自动化程度进行调整。 https://interviewwith.ai/ Deblank Colors Deblank Colors 是一个创意助手,它可以帮助用户生成配色方案,并根据用户的指示进行编辑和调整。该助手旨在帮助设计师们在项目的灵感阶段加快速度,提供配色方案、建议和快速可视化。 https://deblank.com/colors 此芯科技完成数亿元A+轮融资,加速AI PC芯片创新 此芯科技宣布完成数亿元人民币A+轮融资,由国调基金领投,昆山国投、吉六零资本、新尚资本等跟投。资金将用于AI PC领域的创新技术研发及业务落地。此次融资是对此芯科技在通用智能计算领域技术实力和创新力的认可,也展示了公司在AI时代的核心竞争力和未来发展潜力。此芯科技致力于推动AI PC的智能化和高效化,积极与生态伙伴合作,共同打造下一代高端智能芯片。 公司官网:https://www.cixtech.com/news/ https://mp.weixin.qq.com/s/RrMHeZjw43mO1fgIfE33JQ
Inference Labs完成230万美元种子轮融资推动AI创新 Inference Labs,一个Web3 AI项目,已成功获得230万美元的种子轮融资。本轮融资由Delphi Ventures、Digital Asset Capital Management和Mechanism Capital领投,其他参投方包括Big Brain Holdings、BitScale Capital等。这笔资金将用于优化Inference Labs在人工智能领域的创新方法,加速产品开发,并促进整个生态系统的成长。公司致力于将人工智能与Web3技术结合,推动人工智能的安全、易用性,并关注去中心化及隐私保护的未来。 公司官网:https://inferencelabs.com/ https://www.binance.com/en-IN/square/post/2024-04-15-inference-labs-secures-2-3-million-seed-funding-to-boost-ai-innovations-6797248965017?ref=527648310
大模型日报 16
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/04/16055.html