
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


学习
由矩阵乘法边界处理引起的CUDA wmma fragment与原始矩阵元素对应关系探究
frag_base。在具体操作中,load_matrix_sync和store_matrix_sync是 WMMA 中的核心访存函数,它们基于起始地址和 stride 来确定每个 thread 的访存位置。作者以 16x16x16 WMMA 为例,逐步解释了如何计算每个 thread 负责的 A、B、C 矩阵元素,并提供了具体的代码示例。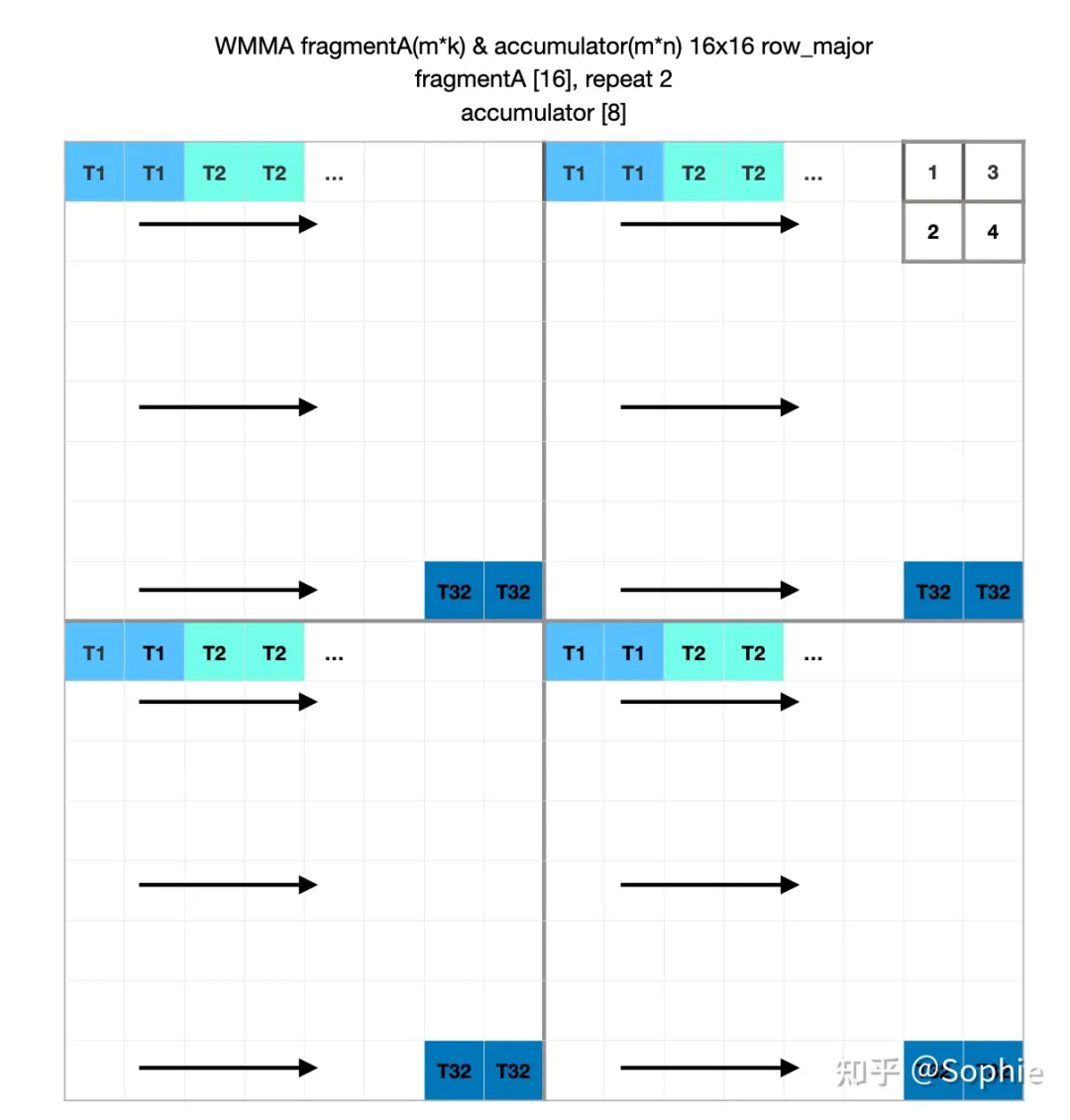 https://zhuanlan.zhihu.com/p/703476975
https://zhuanlan.zhihu.com/p/703476975到底是时代选择了Nvidia,还是Nvidia选择了时代?
 https://www.zhihu.com/question/657934455/answer/3524396101
https://www.zhihu.com/question/657934455/answer/3524396101基于大模型的多意图增强搜索
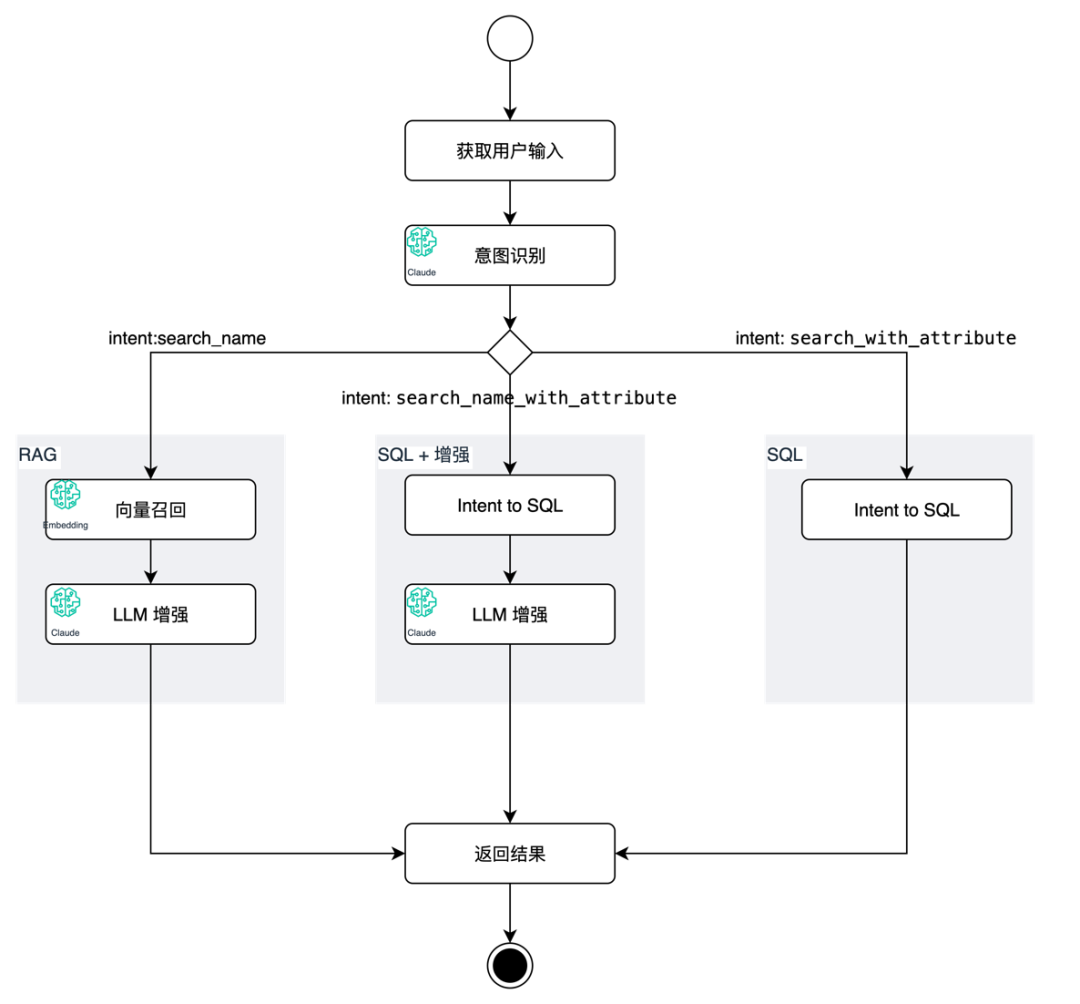 https://aws.amazon.com/cn/blogs/china/multi-intent-enhanced-search-based-on-llm/
https://aws.amazon.com/cn/blogs/china/multi-intent-enhanced-search-based-on-llm/多个后端的 Hugging Face Accelerate 故事:FSDP 和 DeepSpeed
fp32升精,而 FSDP 在默认情况下不执行此操作。为了消除这一差异,Accelerate 0.30.0 版本增加了 FSDP 的混合精度模式和低精度模式,使其能够根据用户需求选择是否进行升精。通过这些改进,FSDP 能够在内存受限的情况下运行,同时保持与 DeepSpeed 相似的训练效果。吞吐量测试表明,在使用 IBM Granite 7B 模型进行训练时,FSDP 和 DeepSpeed 的性能相当。此外,Accelerate 提供了灵活的配置方式,包括命令行和Plugin类,以及一个概念指南,帮助用户更好地理解和操作这两种后端。这些技术细节的优化和指导,极大地方便了用户在 DeepSpeed 和 FSDP 之间进行选择和迁移,提升了模型训练的效率和性能。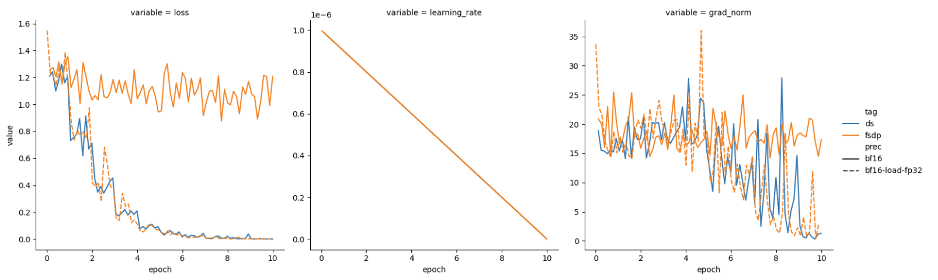 https://huggingface.co/blog/deepspeed-to-fsdp-and-back
https://huggingface.co/blog/deepspeed-to-fsdp-and-backCUDA GEMM优化
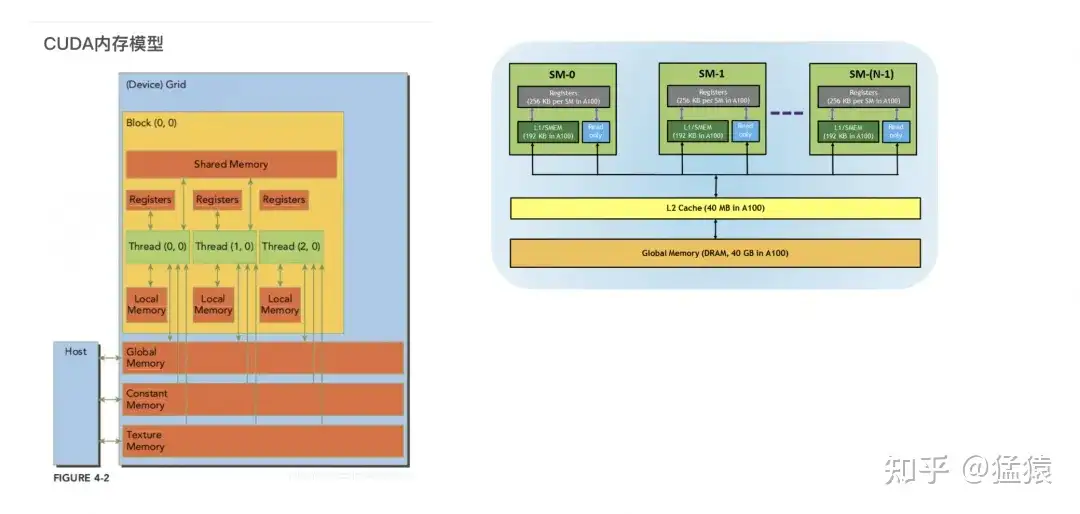 https://zhuanlan.zhihu.com/p/703256080?utm_psn=1784691296243331072
https://zhuanlan.zhihu.com/p/703256080?utm_psn=1784691296243331072在Mistral服务器上使用Mistral进行精细调优的魔法
 https://medium.com/ai-artistry/craft-your-ai-vision-fine-tuning-magic-with-mistral-on-mistral-server-6c9335232159
https://medium.com/ai-artistry/craft-your-ai-vision-fine-tuning-magic-with-mistral-on-mistral-server-6c9335232159LongRoPE
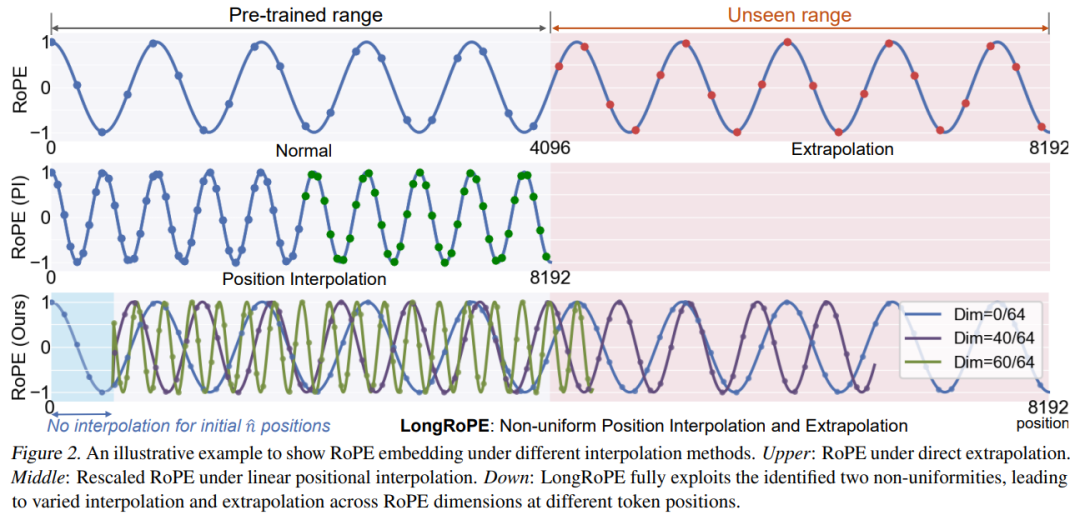 https://github.com/jshuadvd/LongRoPE
https://github.com/jshuadvd/LongRoPEClipboardConqueror
 https://github.com/aseichter2007/ClipboardConqueror
https://github.com/aseichter2007/ClipboardConqueror原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/06/14716.html