
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


论文
解缠逻辑:大语言模型推理能力中上下文的作用
 http://arxiv.org/abs/2406.02787v1
http://arxiv.org/abs/2406.02787v1智能体链:大语言模型在长上下文任务上的协作
你的数据如何激发喜悦?域上采样在训练末期带来的性能提升
 http://arxiv.org/abs/2406.03476v1
http://arxiv.org/abs/2406.03476v1预训练的大语言模型使用傅立叶特征计算加法
 http://arxiv.org/abs/2406.03445v1
http://arxiv.org/abs/2406.03445v1HelloFresh:LLM在X社区笔记和维基百科编辑流中的真实人类编辑行为上的评估
 http://arxiv.org/abs/2406.03428v1
http://arxiv.org/abs/2406.03428v1I4VGen
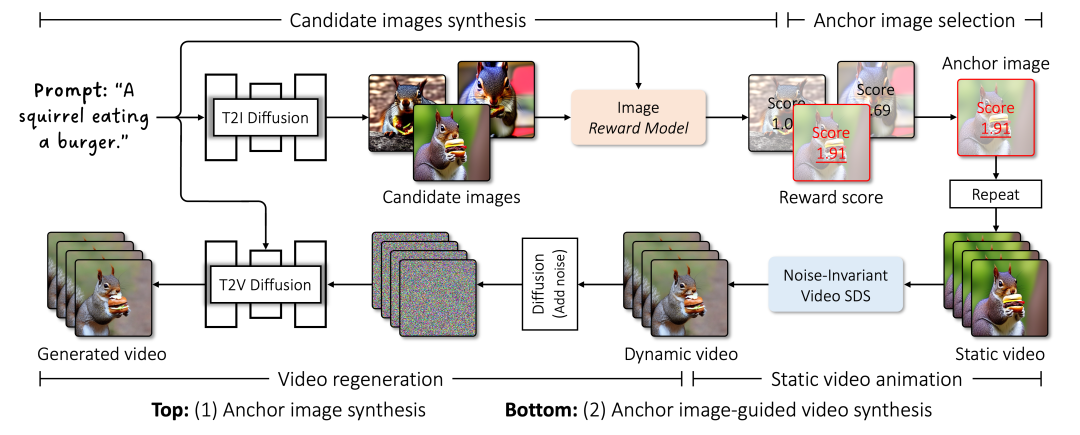
 https://xiefan-guo.github.io/i4vgen/
https://xiefan-guo.github.io/i4vgen/Litgpt
 https://github.com/Lightning-AI/litgpt
https://github.com/Lightning-AI/litgptQmedia
 https://github.com/QmiAI/Qmedia
https://github.com/QmiAI/Qmedia原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/06/14840.html