
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


论文
KV缓存压缩,但我们必须做出什么让步?长上下文能力方法的全面基准测试
 http://arxiv.org/abs/2407.01527v1
http://arxiv.org/abs/2407.01527v1
RegMix: 数据混合作为语言模型预训练的回归
 http://arxiv.org/abs/2407.01492v1
http://arxiv.org/abs/2407.01492v1稀疏扩散策略:机器人学习的一种稀疏、可重复使用和灵活策略
 http://arxiv.org/abs/2407.01531v1
http://arxiv.org/abs/2407.01531v1无智能体:揭秘基于LLM的软件工程智能体
 http://arxiv.org/abs/2407.01489v1
http://arxiv.org/abs/2407.01489v1重要的智能体
 http://arxiv.org/abs/2407.01502v1
http://arxiv.org/abs/2407.01502v1通过权重排列训练的神经网络是通用逼近器
 http://arxiv.org/abs/2407.01033v1
http://arxiv.org/abs/2407.01033v1MimicMotion——让照片动起来
 https://tencent.github.io/MimicMotion/
https://tencent.github.io/MimicMotion/HouseCrafter
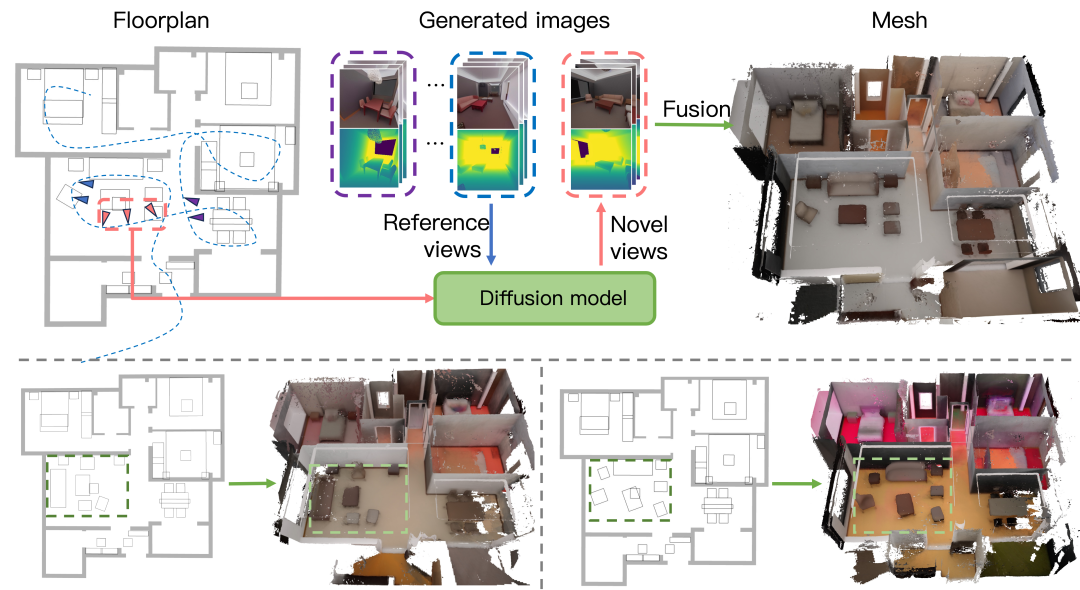 https://neu-vi.github.io/houseCrafter/
https://neu-vi.github.io/houseCrafter/Hunyuan-Captioner
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/07/14386.html