
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


论文
高效的大语言模型调度:通过学习排序实现
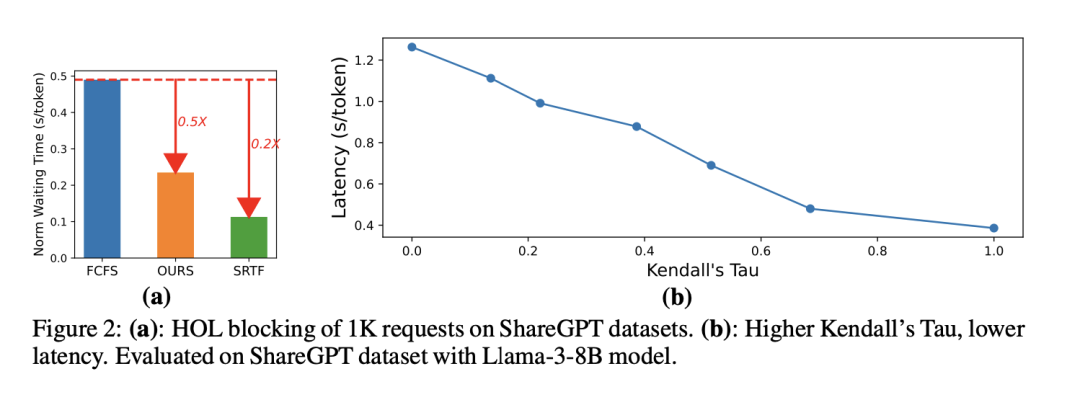
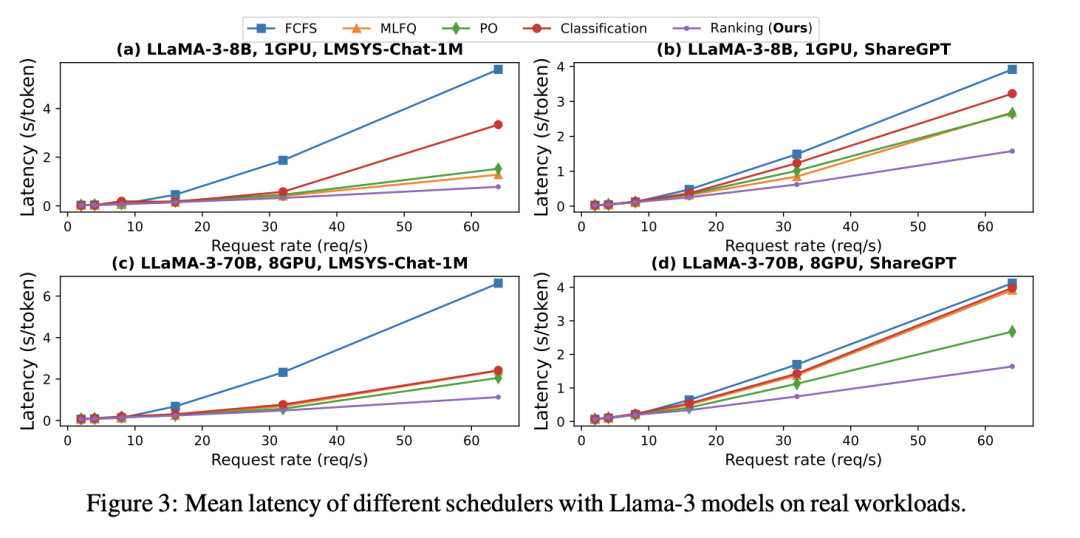 http://arxiv.org/abs/2408.15792v1
http://arxiv.org/abs/2408.15792v1自回归模型在Ising临界点附近的路径依赖
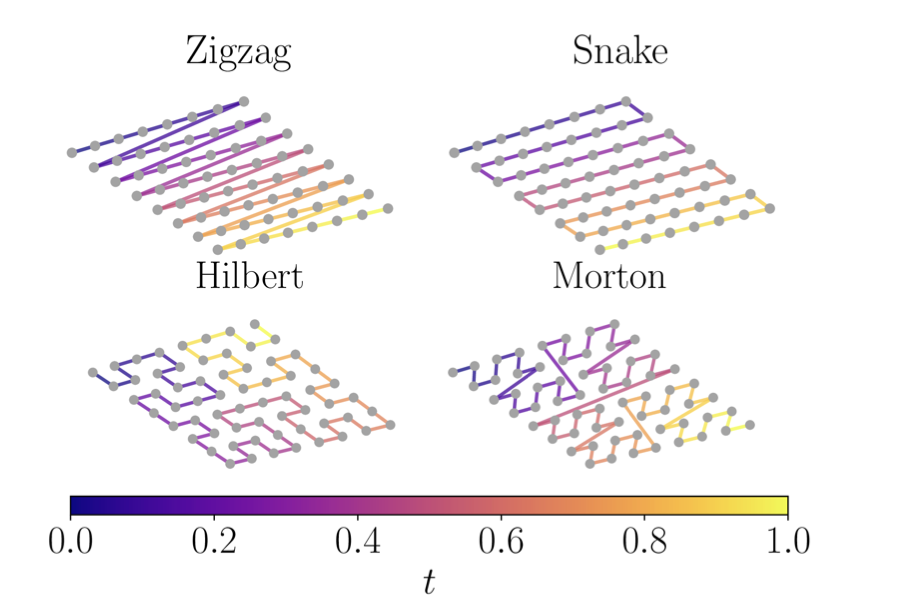
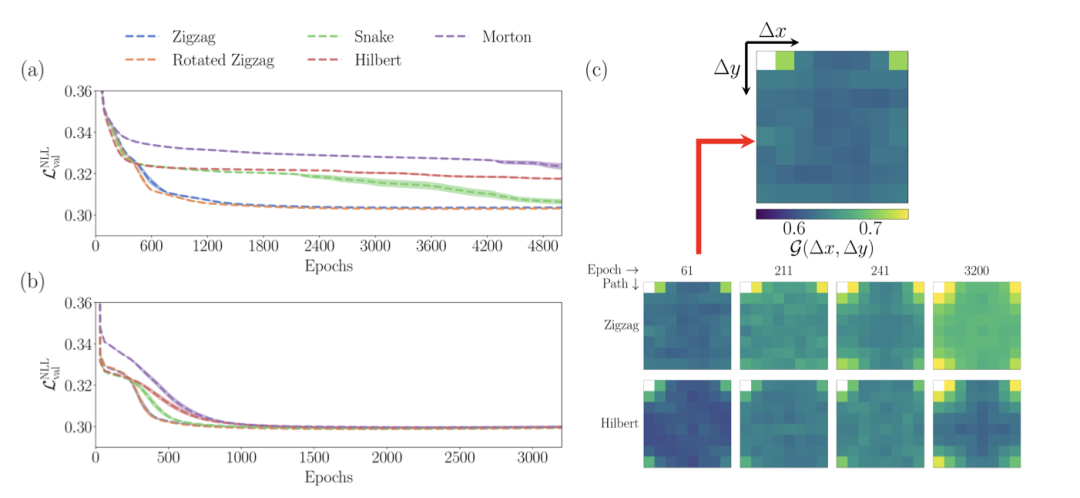 http://arxiv.org/abs/2408.15715v1
http://arxiv.org/abs/2408.15715v1避免生成模型作家停滞问题的方法:通过嵌入微调进行涌现
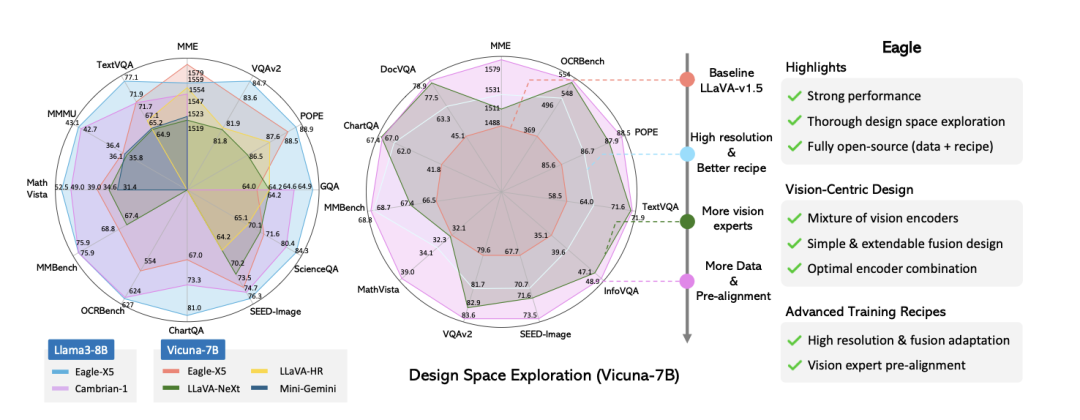
 http://arxiv.org/abs/2408.15079v1
http://arxiv.org/abs/2408.15079v1Eagle:探索带有多种编码器的多模态大语言模型设计空间
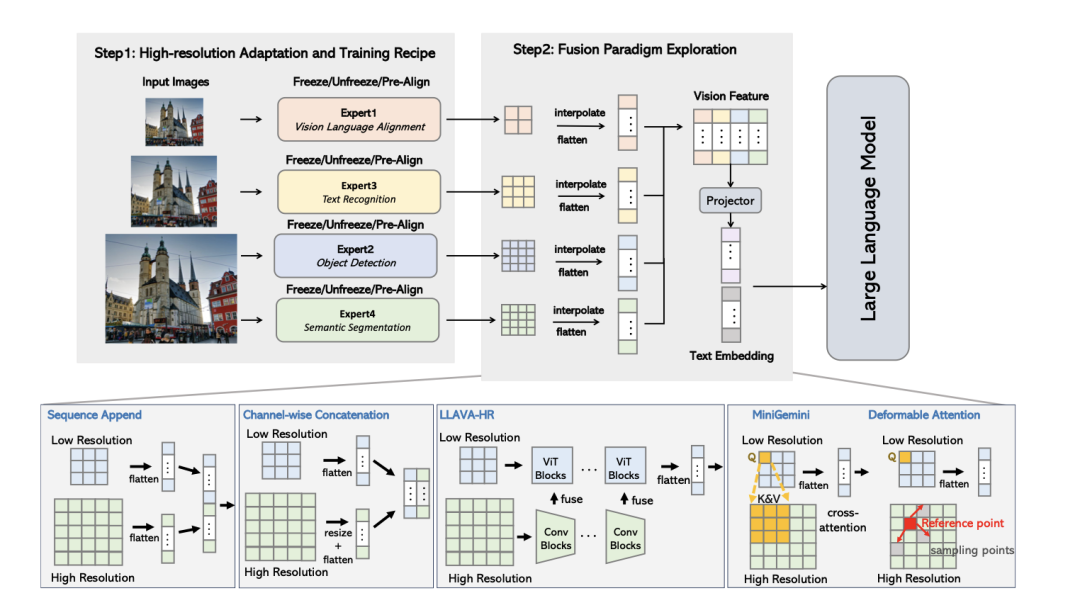 http://arxiv.org/abs/2408.15998v1
http://arxiv.org/abs/2408.15998v1CoGen: 结合理解和生成学习反馈
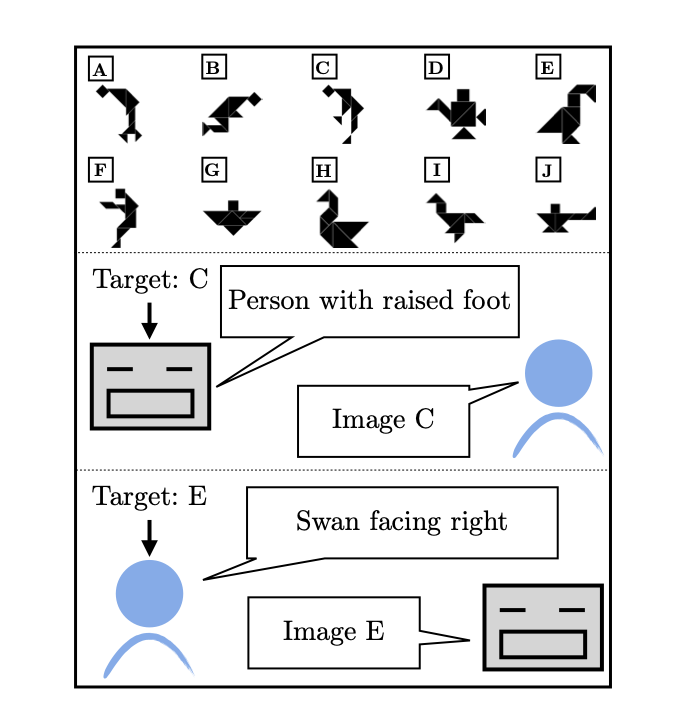 http://arxiv.org/abs/2408.15992v1
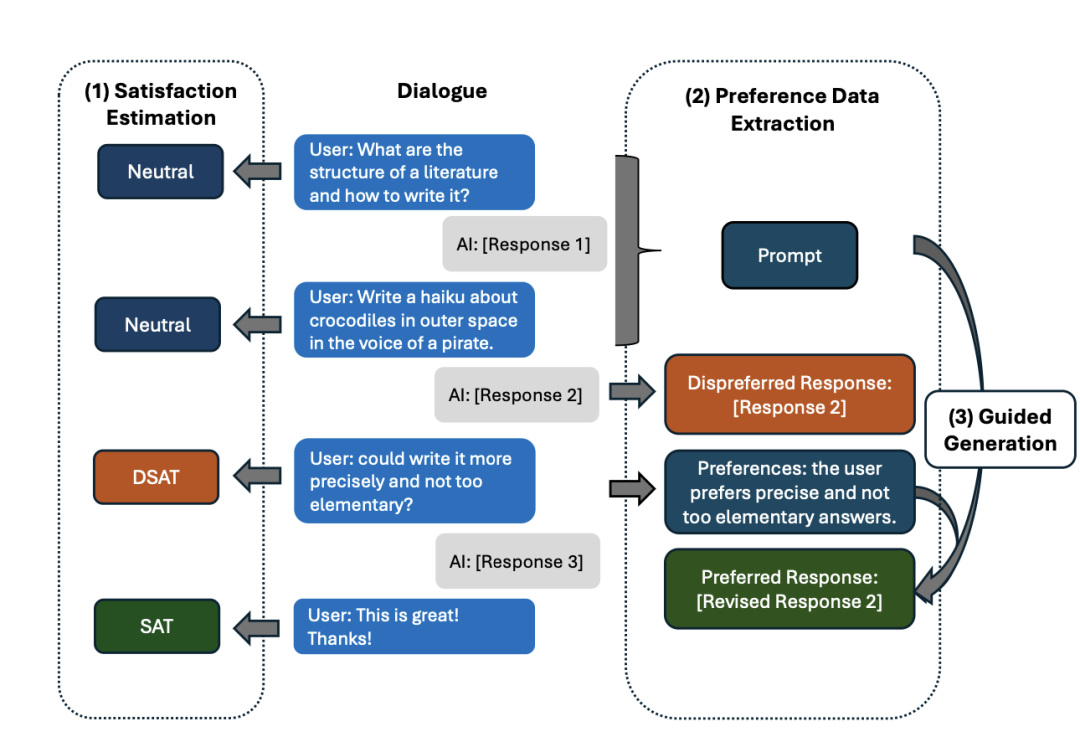
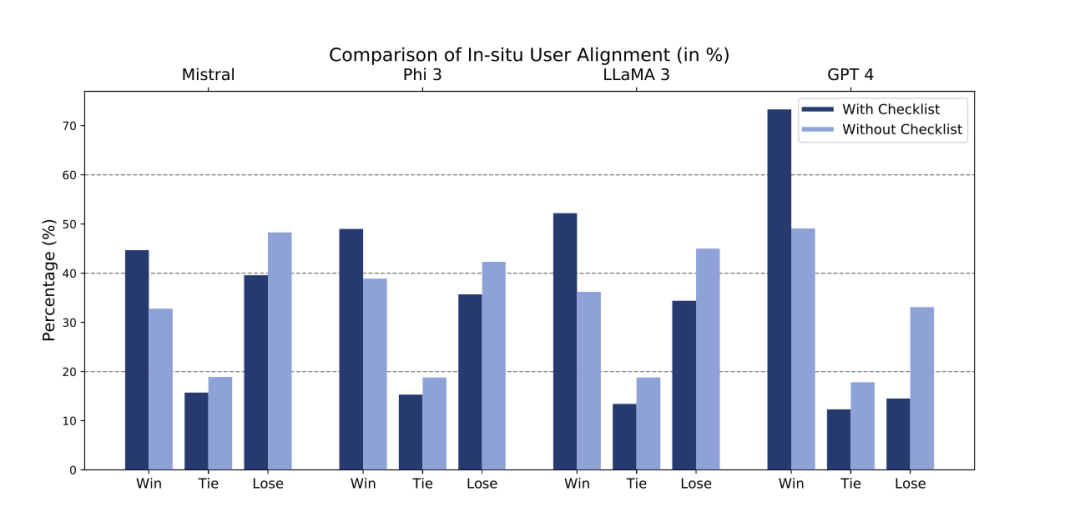
http://arxiv.org/abs/2408.15992v1WILDFEEDBACK:将LLMs与现场用户互动和反馈对齐
 http://arxiv.org/abs/2408.15549v1
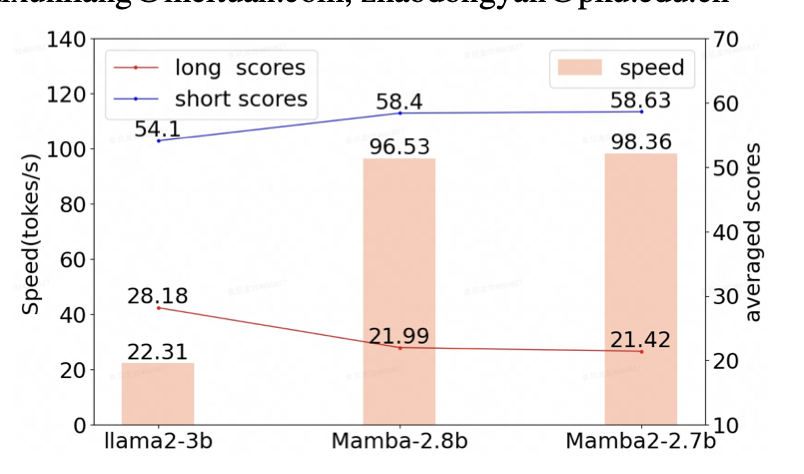
http://arxiv.org/abs/2408.15549v1ReMamba:为Mamba装备有效的长序列建模
 http://arxiv.org/abs/2408.15496v1
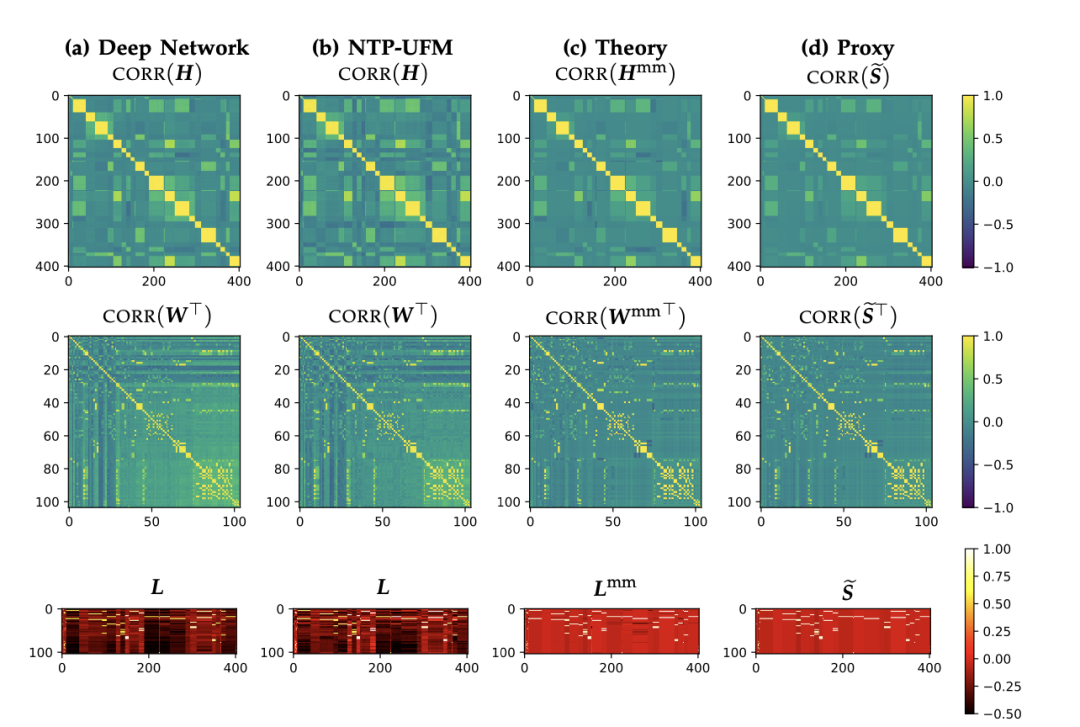
http://arxiv.org/abs/2408.15496v1下一个token预测的隐式几何:从语言稀疏模式到模型表示
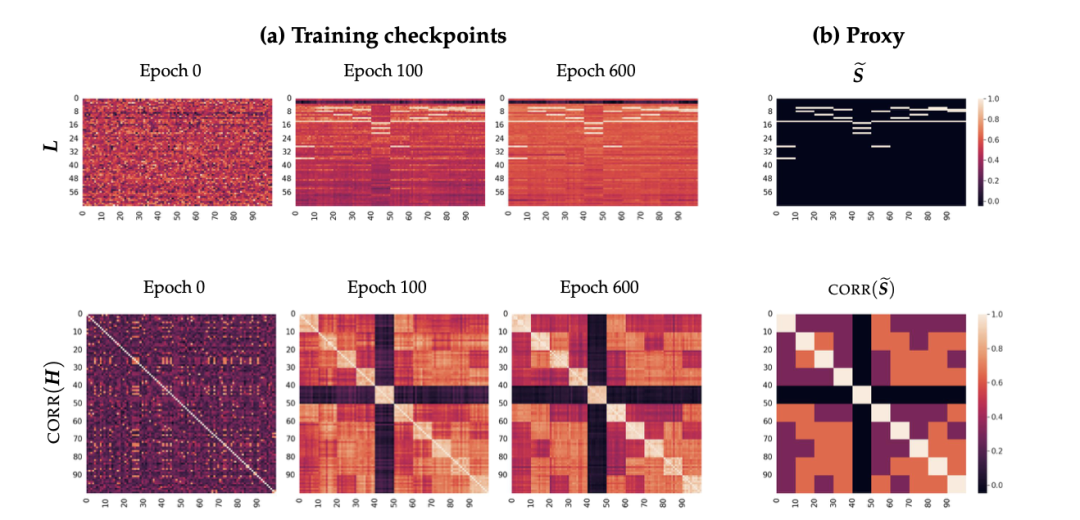 http://arxiv.org/abs/2408.15417v1
http://arxiv.org/abs/2408.15417v1当代LLM研究中的奇迹、规律和缺陷
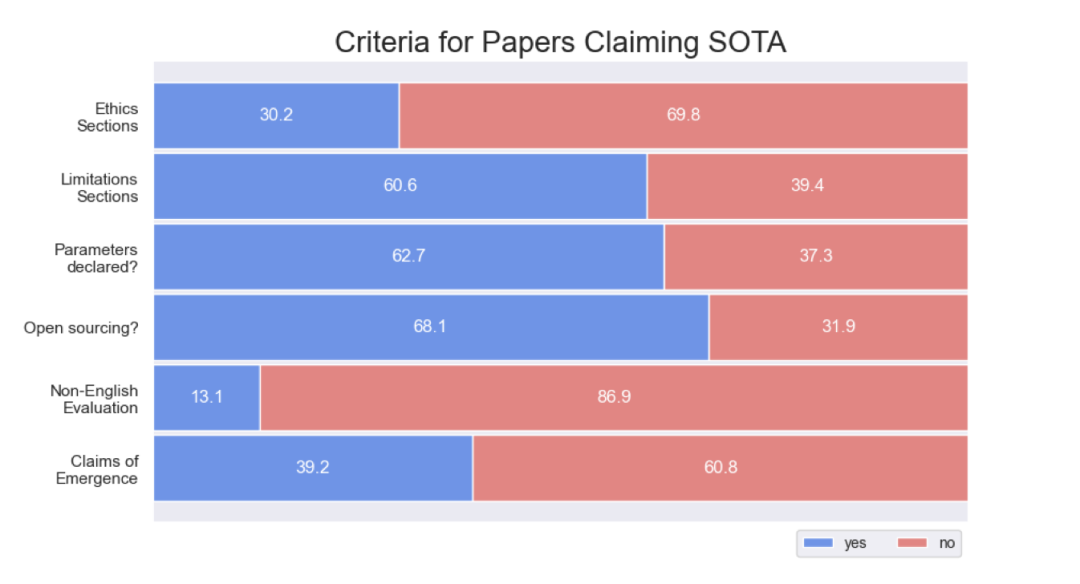 http://arxiv.org/abs/2408.15409v1
http://arxiv.org/abs/2408.15409v1LOGICGAME:大语言模型基于规则推理能力的基准测试
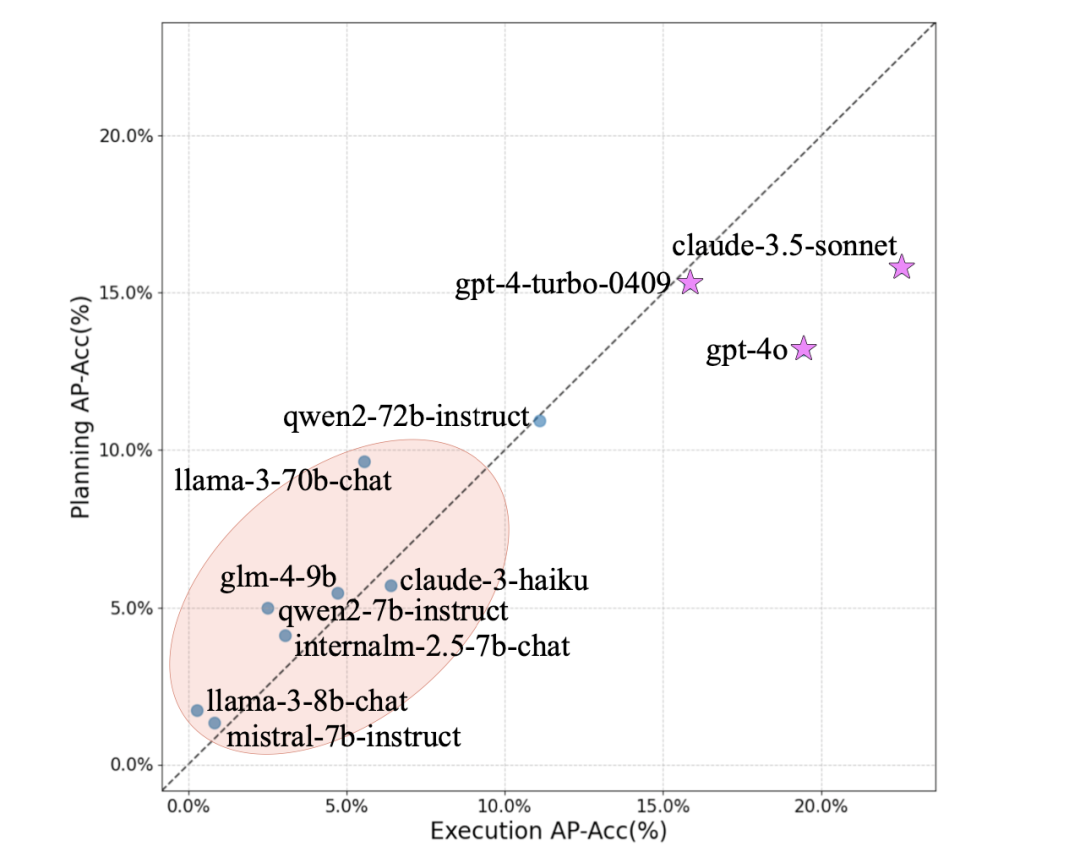
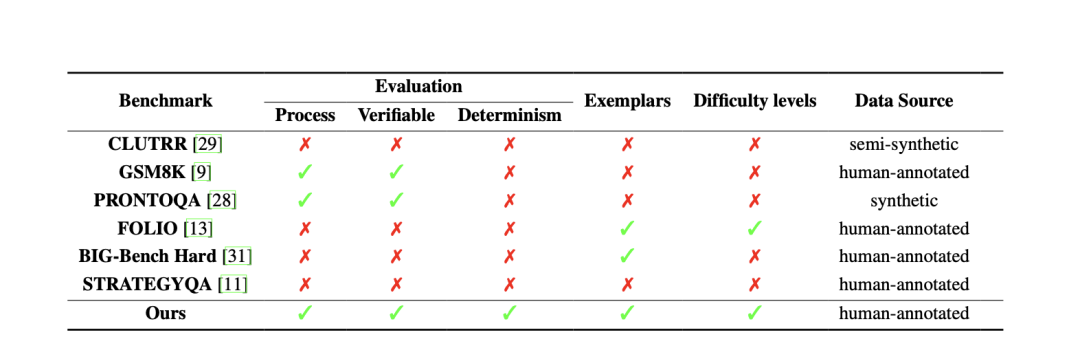 http://arxiv.org/abs/2408.15778v1
http://arxiv.org/abs/2408.15778v1Hyper-SD
 https://huggingface.co/ByteDance/Hyper-SD
https://huggingface.co/ByteDance/Hyper-SDGameNGen
 https://github.com/showlab/show-o
https://github.com/showlab/show-oK-Sort-Arena
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/08/13259.html