
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


资讯
苹果发布A18与A18 Pro仿生芯片:AI性能成焦点
 https://mp.weixin.qq.com/s/4kVO390n-RCFogoP1cLLfg
https://mp.weixin.qq.com/s/4kVO390n-RCFogoP1cLLfgLlama 3蒸馏到Mamba模型,推理速度提升至1.6倍!
-
初始化:首先,作者发现Transformer的注意力机制与RNN的计算存在相似性,基于此将Transformer的注意力机制线性化,作为蒸馏的初步步骤。 -
三阶段蒸馏: -
伪标签蒸馏:使用预训练的Transformer生成伪标签,Mamba学生模型以这些标签进行训练,结合KL散度和交叉熵损失。 -
监督微调:在指令数据集上进行训练,如OpenHermes 2.5。 -
人类反馈优化:基于奖励模型,使用PPO算法优化模型性能。
-
性能表现:在单轮和多轮对话任务(如AlpacaEval、MT-Bench)上,混合模型与Llama-3相比表现出色,1:1混合模型效果最佳。 -
推理加速:Llama 3混合模型的推理速度提升了1.6倍,且在NLP任务上表现优异,在GSM8K和CRUX任务上甚至超过了Instruct模型。
 https://mp.weixin.qq.com/s/2oyeCdlqKaeQATje–U8qg
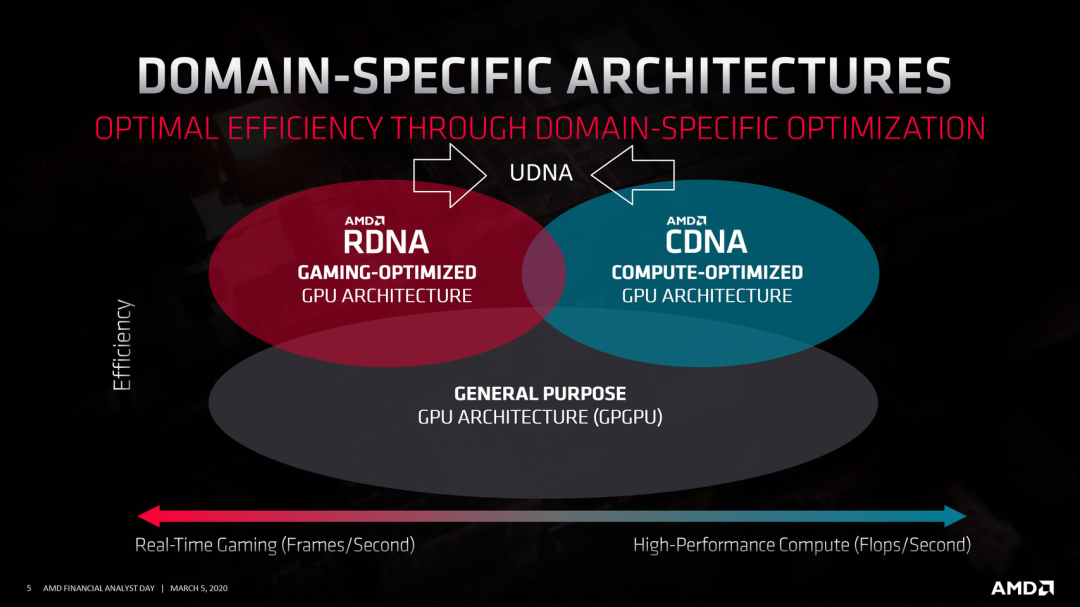
https://mp.weixin.qq.com/s/2oyeCdlqKaeQATje–U8qgAMD的颠覆性战略:放弃旗舰游戏显卡,专注AI和生态扩展
-
统一GPU架构:AMD将RDNA(面向消费市场)和CDNA(面向数据中心)统一为新的UDNA架构,目标是通过统一架构提升优化效率,吸引更多开发者。Jack Huynh承认,RDNA架构的内存层次结构设计存在问题,导致每次改动都需重新优化。UDNA架构的推出将解决这一问题,并提升未来三代产品的持续优化能力。 -
AI加速能力提升:现有RDNA架构中AI加速能力有限,尤其是在FP16格式计算优化方面依赖WMMA指令,未来UDNA架构预计将为桌面GPU引入完整的张量运算支持,使桌面和数据中心GPU架构一致。这不仅能提升AI任务处理效率,还能推动AMD云到客户端的全方位战略。 -
开源生态与CUDA对标:AMD希望通过ROCm软件堆栈与英伟达的CUDA抗衡,目标是在未来吸引400万开发者。这一策略依赖于开源社区的支持和AMD在软件优化方面的简化工作,加速整个生态的扩展。然而,为了推动这一生态发展,游戏和其他专业软件的优化被部分牺牲。 -
放弃旗舰显卡市场:AMD历史上多次未能成功进军高端显卡市场,现决定转向中低端市场,停止与英伟达旗舰显卡的直接竞争。市场预测,英伟达可能会借此自由定价其下一代旗舰产品,这对消费者而言并非利好消息。
 https://mp.weixin.qq.com/s/FNW5sS4qVDbyILW-JSNV_g
https://mp.weixin.qq.com/s/FNW5sS4qVDbyILW-JSNV_g自博弈方法在强化学习中的应用综述
-
传统自博弈算法:如Vanilla self-play和Fictitious self-play,通过逐步扩展策略池进行策略训练。 -
PSRO 系列算法:例如α-PSRO,通过更加复杂的元策略求解器(MSS)扩展策略池,适应更复杂的多智能体任务。 -
基于持续训练的算法:解决PSRO系列的训练成本和效率问题,强调在多个训练周期内反复训练策略池。 -
后悔最小化算法:侧重于长期累积收益,避免智能体被对手长期利用,适用于重复博弈场景。
-
棋类游戏:AlphaGo等自博弈算法在围棋等完全信息博弈中取得了突破性进展。 -
牌类游戏:包括德州扑克、斗地主和麻将,应用后悔最小化算法和自博弈增强智能体表现。 -
电子游戏:在《星际争霸》《Dota 2》等实时战略游戏中,自博弈算法同样展现了强大的适应性和战略规划能力。
 https://mp.weixin.qq.com/s/oMY0O0OIVYJc04zkoMzgcQ
https://mp.weixin.qq.com/s/oMY0O0OIVYJc04zkoMzgcQ自动提示词工程:LLM 性能优化的关键技术
近日,谷歌研究者 Heiko Hotz 发表了一篇长文,详细介绍了自动提示词工程(APE)的原理与实现方法。APE 的核心在于通过自动生成与优化提示词,提高大型语言模型(LLM)在特定任务上的性能。与传统的人工提示词工程类似,APE 旨在系统化地测试和优化提示词,从而提升 LLM 的表现。该技术的工作原理类似于传统监督式机器学习中的超参数优化(HPO),但其难点在于提示词是文本,而非数值。
-
输入初始提示词、标注数据集和评估指标。 -
目标 LLM 根据提示词生成任务响应。 -
使用评估 LLM 评估响应性能。 -
优化器 LLM 生成新的提示词,并迭代该过程。 -
最终选择性能最佳的提示词。
-
随机提示词优化:通过随机生成提示词来探索不同的可能性,类似于随机搜索的 HPO 方法。 -
OPRO(通过提示操作进行优化):这一策略通过记录和分析提示词的历史表现,有意识地引导 LLM 提升性能。
 https://mp.weixin.qq.com/s/TxzkRUPhsiqtLhCyrIsQrQ
https://mp.weixin.qq.com/s/TxzkRUPhsiqtLhCyrIsQrQ推特
iPhone 16的Apple Intelligence功能
 https://x.com/dr_cintas/status/1833205331092246844
https://x.com/dr_cintas/status/1833205331092246844
Jim Fan:操控LLM基准测试极其简单,只相信在LMSys Chatbot Arena上的ELO分数和可信的第三方
-
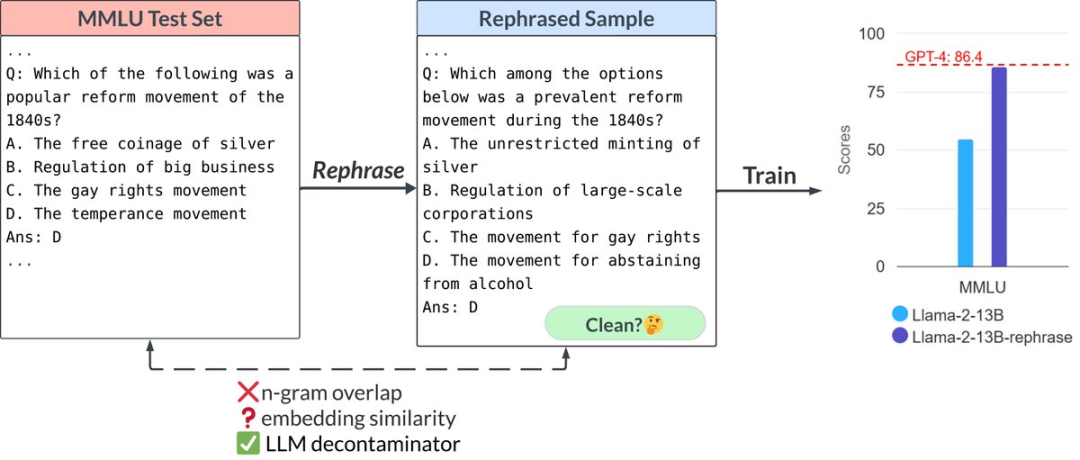
在测试集的改写示例上训练。LMSys 的 “LLM-decontaminator” 论文发现,通过仅仅将测试题目改写成不同的格式、措辞,甚至是外语,你可以用一个13B的模型(!!)在 MMLU、GSK-8K 和 HumanEval(编码)上打败 GPT-4。轻松提高10分。 -
甚至可以轻松操控LLM-decontaminator。它只检测改写,但你可以使用任何前沿模型生成*新的问题*,这些问题表面上不同,但解决模板/逻辑非常相似。换句话说,你试图针对测试集的相似分布进行过拟合,而不是对具体样本过拟合。比如 HumanEval 就是一堆简单的Python问题(即一个特定的、狭窄的分布),完全不反映真实世界的编码复杂性。 -
你还可以通过提示工程来对生成器进行极致优化,以骗过LLM-decontaminator或其他检测器。检测器是公开的,但你的数据生成是私有的,充分利用这一点。 -
增加推理时间的计算预算几乎总是有效的。自我反思技术已被长期使用(参见Reflexion,Shinn等,2023年)。也可以尝试简单的多数投票或Tree of Thought。这些思路路径本质上是测试时的集成方法,越多越好。显然,N个事物的集成>1个事物,如果你不控制推理时的tokens。
-
在LMSys Chatbot Arena上的ELO分数。在真实环境中操控民主是很难的。 -
由可信的第三方(如 Scale AI 的基准测试)进行的私有LLM评估。测试集必须经过精心策划并严格保密,否则很快就会失去效力。
 https://x.com/DrJimFan/status/1833160432833716715
https://x.com/DrJimFan/status/1833160432833716715ChaiDiscovery 发布 Chai-1:一种用于分子结构预测的基础模型
 https://x.com/joshim5/status/1833183091776721106
https://x.com/joshim5/status/1833183091776721106Tyler 分享“新的 10倍工程师”:15分钟内从灵感到代码
 https://x.com/tjcages/status/1833218417639186936
https://x.com/tjcages/status/1833218417639186936
01Light停止销售,退款并推出免费应用程序
 https://x.com/hellokillian/status/1833215071880941972
https://x.com/hellokillian/status/1833215071880941972
产品
Syncly(YC W23)
 https://syncly.app/
https://syncly.app/Meshy
 https://www.meshy.ai/
https://www.meshy.ai/原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/09/13022.html