
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


论文
Learning vs Retrieval:LLM在回归中的角色及上下文示例

 http://arxiv.org/abs/2409.04318v1
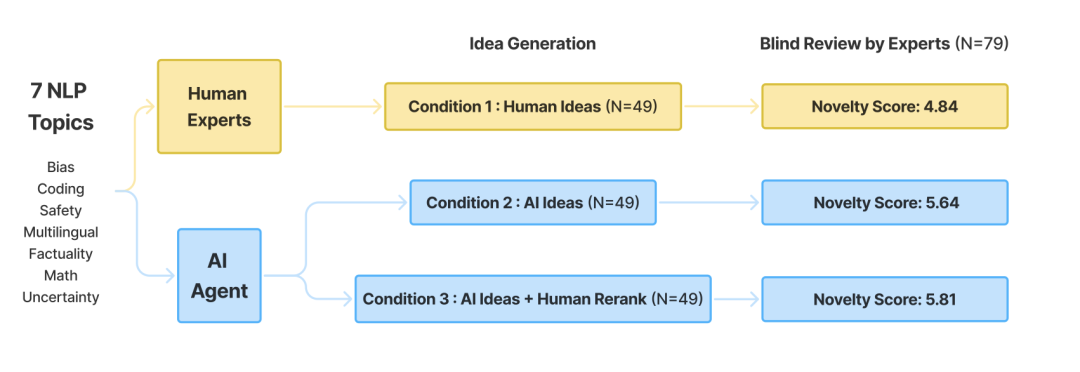
http://arxiv.org/abs/2409.04318v1LLM能否生成新颖的研究想法?与100多名NLP研究人员进行的大规模人类研究
 http://arxiv.org/abs/2409.04109v1
http://arxiv.org/abs/2409.04109v1你的代码LLMs表现如何?用高质量数据赋能代码指令微调

 http://arxiv.org/abs/2409.03810v1
http://arxiv.org/abs/2409.03810v1用多层SAEs进行残余流分析
稀疏自编码器(SAEs)是解释Transformer语言模型内部表示的一种有希望的方法。然而,标准SAEs在每个Transformer层上分别训练,使得难以使用它们来研究信息如何在层间流动。为了解决这个问题,我们引入了多层SAE(MLSAE):一个单一的SAE同时训练每个Transformer层的残差流激活向量。残差流通常被理解为在层间保留信息,因此我们期望,并且确实发现单独的SAE特征在多个层上都是活跃的。这些结果表明MLSAEs是研究Transformer中信息流动的一种有希望的方法。我们发布了用于训练和分析MLSAEs的代码。
 http://arxiv.org/abs/2409.04185v1
http://arxiv.org/abs/2409.04185v1利用大语言模型生成真实的多智能体知识工作数据集
 http://arxiv.org/abs/2409.04286v1
http://arxiv.org/abs/2409.04286v1Sigmoid 自注意力的理论、分析和最佳实践
 http://arxiv.org/abs/2409.04431v1
http://arxiv.org/abs/2409.04431v1Loopy
-
音频到视频生成:Loopy 可以根据音频输入生成生动的运动细节,包括非语言动作(如叹气、情感驱动的眉毛和眼睛运动,以及自然的头部运动),不需要手动指定的空间运动模板。 -
时间模块设计:模型设计了一个内外剪辑时间模块和一个音频到潜在空间模块,使其能够利用数据中的长期运动信息,从而学习自然的运动模式,提高音频与图像运动的关联性。 -
多样化运动生成:Loopy 可以针对同一参考图像,根据不同的音频输入生成适应性合成结果,适用于快速、舒缓或真实的歌唱表演。
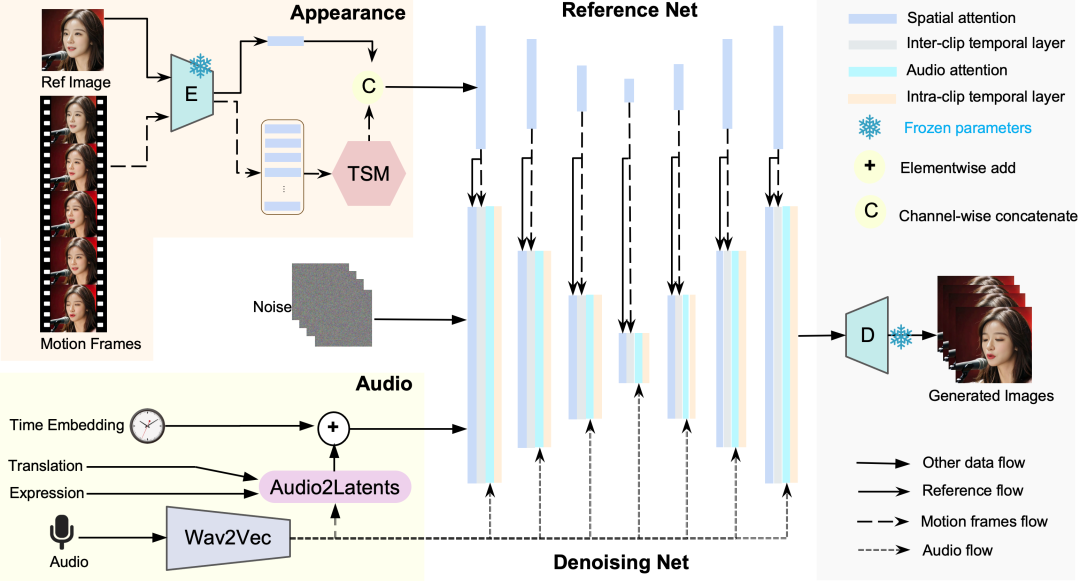 https://loopyavatar.github.io/
https://loopyavatar.github.io/Yi-Coder
 https://github.com/01-ai/Yi-Coder
https://github.com/01-ai/Yi-Coder原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/09/13051.html