
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


学习
如何复现 SGLang v0.3.0 和 vLLM v0.6.0 的性能测试
-
GPU Utilization 不公平对比:在 vLLM 的复现中,GPU utilization 被单独调整为 0.95,而其他框架如 SGLang、LMDeploy、TensorRT LLM 则使用了默认值,导致性能对比时不公平。SGLang 指出这种调整会影响极限吞吐量。 -
Multi Step 设置影响:vLLM v0.6.0 引入了 multi step 设置,默认值为 10,这减少了 CPU overhead,提升了吞吐量(TPOT),但增加了 TTFT 和 ITL。用户感知的主要指标是 ITL,而 vLLM 在其博客中展示的却是 TPOT,且 TTFT 图表的 y 轴被放大,误导了读者对不同框架延迟的理解。 -
复现测试结果:SGLang 通过测试 Llama 3.1 8B 和 Llama 3.1 70B Instruct,结果显示: -
Online Benchmark:在 1xA100 和 4xH100 环境下,vLLM 的 Median TTFT 和 Median ITL 都显著高于 SGLang。vLLM 的 Median TTFT 接近 SGLang 的 3 倍,而 ITL 则接近 10 倍,这对在线应用场景影响较大。 -
Offline Benchmark:在极限吞吐场景中,SGLang 在各个测试场景的 Output Token Throughput 上都优于 vLLM。 -
复现方法:SGLang 提供了复现细节,通过 RunPod 云平台,使用公开的脚本和配置可以重现这些结果,详细信息可在 SGLang 的 GitHub 项目中找到。
 https://zhuanlan.zhihu.com/p/718504437?utm_psn=1815372290709409792
https://zhuanlan.zhihu.com/p/718504437?utm_psn=1815372290709409792PEARL: 并行投机解码,推理加速最新SOTA(blog/paper/code均开源)
 https://zhuanlan.zhihu.com/p/716769091?utm_psn=1815410605504462848
https://zhuanlan.zhihu.com/p/716769091?utm_psn=1815410605504462848大模型混合并行DP/TP/PP,如何划分机器?
-
数据并行(DP):每个设备上有一个完整模型副本,各设备独立处理部分数据,之后通过AllReduce操作汇总梯度信息。通信量主要发生在每个epoch结束时,需要同步所有模型参数,因此通信量较大,尤其在大型模型中。 -
张量并行(TP):模型的权重矩阵分割到不同设备上计算,通信主要在前向和后向传播过程中发生,每次迭代需要频繁交换张量分块的中间结果。这导致TP的通信量较大,尤其在复杂模型中,需要频繁执行concat操作。 -
流水线并行(PP):模型的不同层分配到不同设备,设备间顺序传递激活和梯度。通信仅在相邻设备间进行,通信量较小,但需要解决同步问题以保证正确的计算顺序。
-
模型并行(MP):模型分布在多个GPU上。 -
张量并行(TP):每个模型层的参数纵向切割分配给多个GPU。 -
流水线并行(PP):每个模型层被分配到不同GPU,按顺序传递数据。
 https://zhuanlan.zhihu.com/p/718370713?utm_psn=1815292995408359424
https://zhuanlan.zhihu.com/p/718370713?utm_psn=1815292995408359424投机推理番外四:batch 与 IO
-
MagicDec 提出了结合推测长度、接受率和 batch size 的理论加速比模型,利用 SD 提高吞吐量和降低延迟,尤其在中等到长序列情况下,通过稀疏 KVCache 的草稿模型优化解码阶段。
-
BASS 针对批处理提出了优化不规则张量(ragged tensor)的方法,通过定制的 CUDA 内核处理批量维度上的不规则性,使用 BASS-PAD 和 BASS-SPLIT 调度方法,解决了序列长度和拒绝点不同导致的张量形状不一致的问题。
-
Clover/Clover-2 通过回归连接和知识蒸馏提高并行解码的准确性和效率,使用增强块来优化隐藏状态。Clover-2 引入了更复杂的增强块和独立注意力解码器,提升了模型性能,且知识蒸馏策略有效解决了过拟合问题。
-
FSPAD 引入特征采样和部分对齐蒸馏,通过在特征和 logits 之间建立联系来提高草稿模型的性能,减少训练过程中的不确定性。
-
KOALA 采用对抗学习方法训练草稿头,捕捉更复杂的 token 生成细节,以提高推测解码的准确性,展示了蒸馏的潜在优势。
-
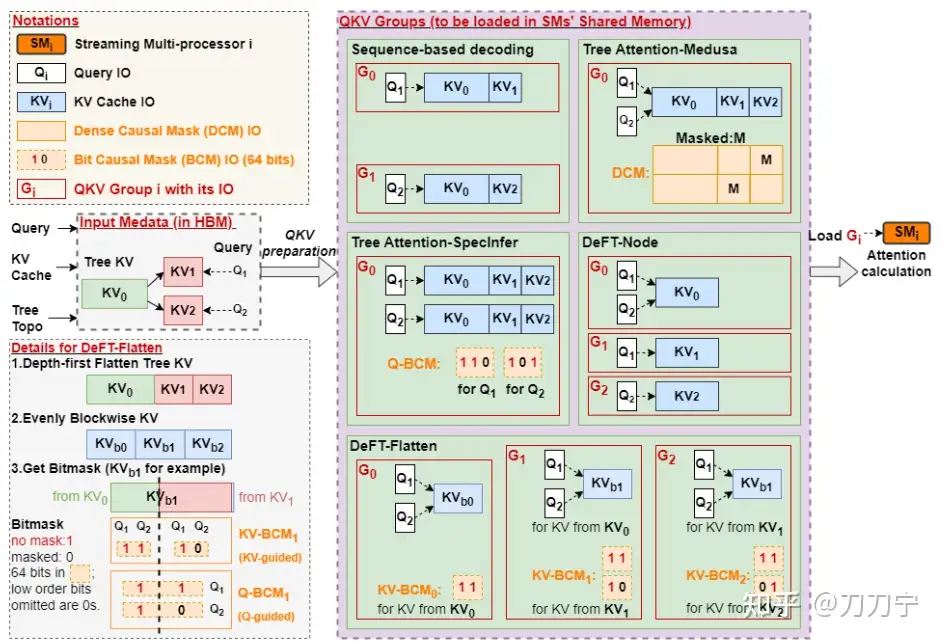
DeFT 针对树形注意力(tree-attention)提出了优化策略,减少内存访问和缓存存储开销,通过树结构的 KVCache 共享提高计算效率,减少无效的计算资源占用。
总结:所有论文均探讨如何在推测解码中优化 IO 访问密度,涉及 memory bound 和 compute bound 问题。这些优化方法虽不够创新,但在当前架构下有实际效果。
 https://zhuanlan.zhihu.com/p/716488006?utm_psn=1815071198356312064
https://zhuanlan.zhihu.com/p/716488006?utm_psn=1815071198356312064
最前沿——基础模型和多模态交互(2):音频生成模型的技术概要
 https://zhuanlan.zhihu.com/p/718173141?utm_psn=1815091363282305028
https://zhuanlan.zhihu.com/p/718173141?utm_psn=1815091363282305028智能眼镜有望成为端侧AI落地最佳场景之一|东吴电子
 https://mp.weixin.qq.com/s/lehImY7q7f8Of3KsqrstbQ
https://mp.weixin.qq.com/s/lehImY7q7f8Of3KsqrstbQGPT5训练失败的思考
-
大模型发展放缓:AI依然是硅谷的焦点话题,但热度有所下降。原因是大模型的扩展速度减缓,尤其是在训练资源的需求上。谷歌内部在3-4周前训练Gemini下一代模型(预计比前代大10倍,类似于GPT-5)时,两次都失败,导致GPT-5的发布延期。主要挑战包括: -
MOE(Mixture of Experts)效果不佳:后训练阶段模型未能很好地收敛。 -
数据瓶颈:合成数据质量远不及现有的网络数据。 -
GPT-5可能继续延期:由于上述技术困难,GPT-5发布时间或将继续延迟。
-
现有模型的输出能力:GPT-4在有限信息输入下的表现已接近完美,许多未能满意回答的原因更多源于输入信息不足,而非模型能力不足。 -
推理能力局限:现有模型虽然在长上下文处理上表现优秀,但在复杂推理任务中仍有局限。尤其是多阶推理、路径探索和经验积累,这些应依赖更复杂的Agent架构来实现。 -
模型计算能力:大模型不应被期望进行精确的数学计算,因为这些涉及逻辑推理和记忆。将复杂计算任务交给专用工具处理是合理的。 -
“压缩即智能”的局限性:虽然压缩体现了智能的一部分,但真正的智能推导,如物理理论,更多依赖推理、假设和实验,而非简单归纳。
LLM101n
 https://github.com/karpathy/LLM101n
https://github.com/karpathy/LLM101nhelicone
 https://github.com/Helicone/helicone
https://github.com/Helicone/helicone原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/09/13101.html