


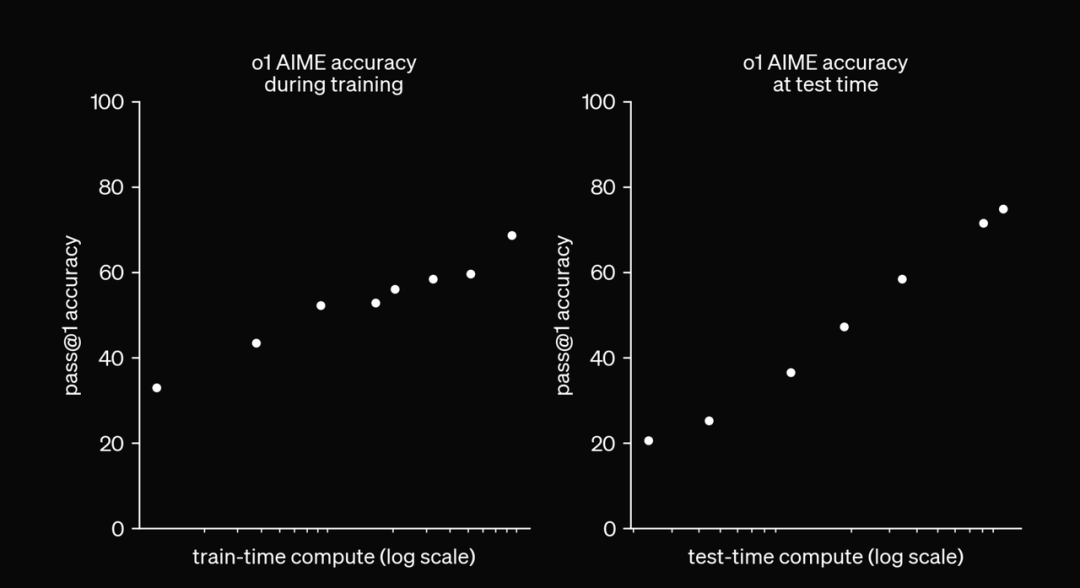
1.1 推理能力和计算时间的scaling

1.2 Benchmark表现以及细节

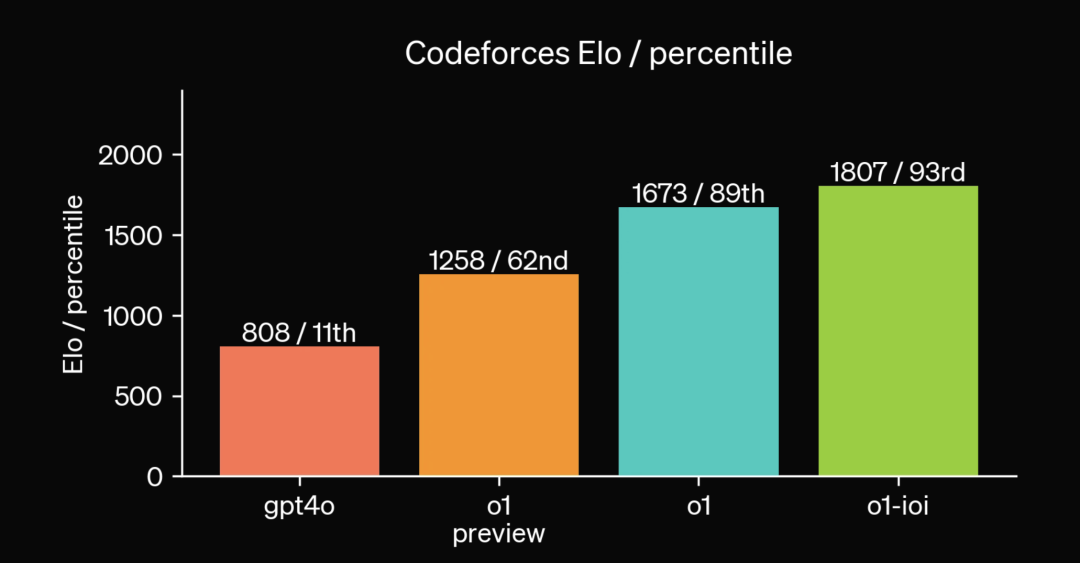
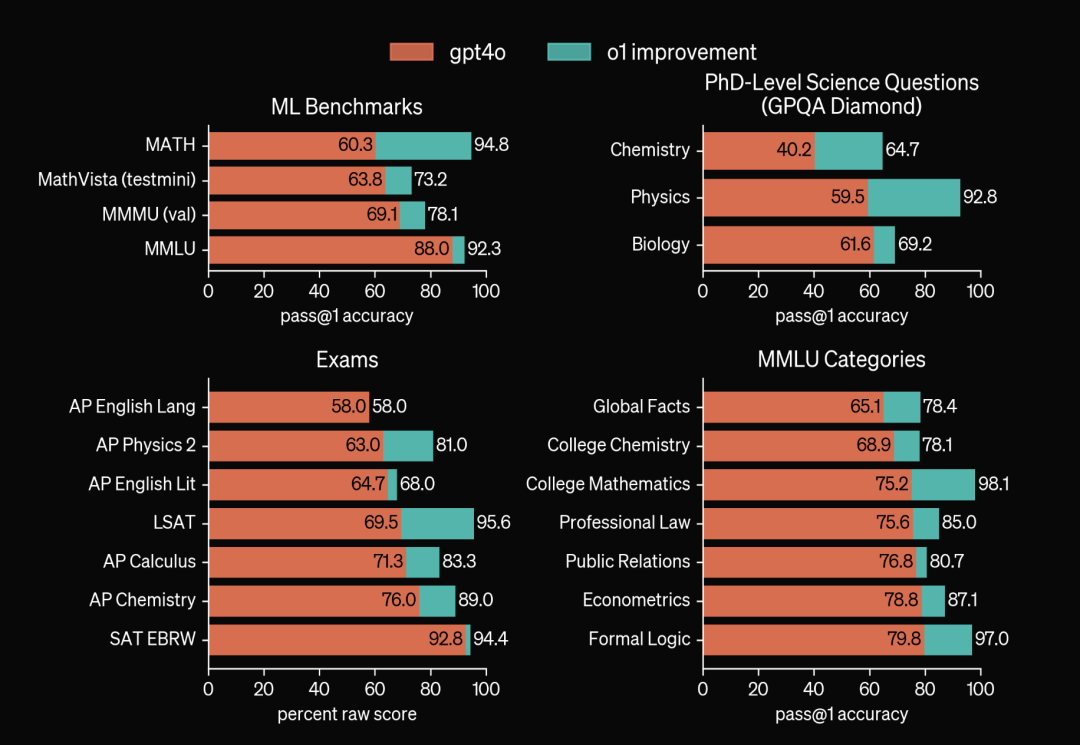
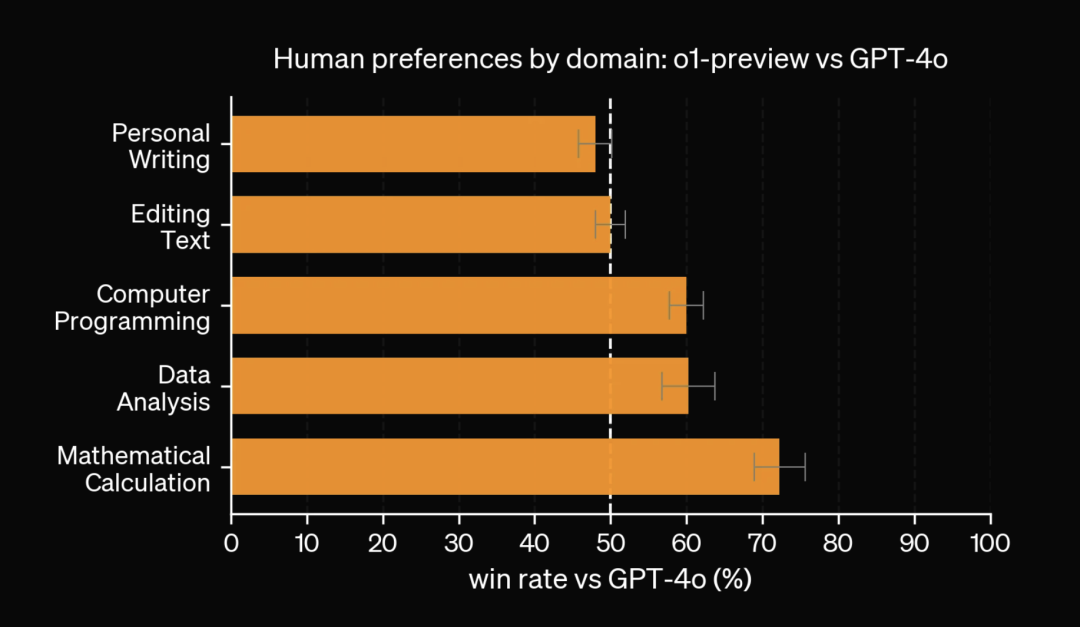
1.3 推理、安全和可解释性的大幅提升
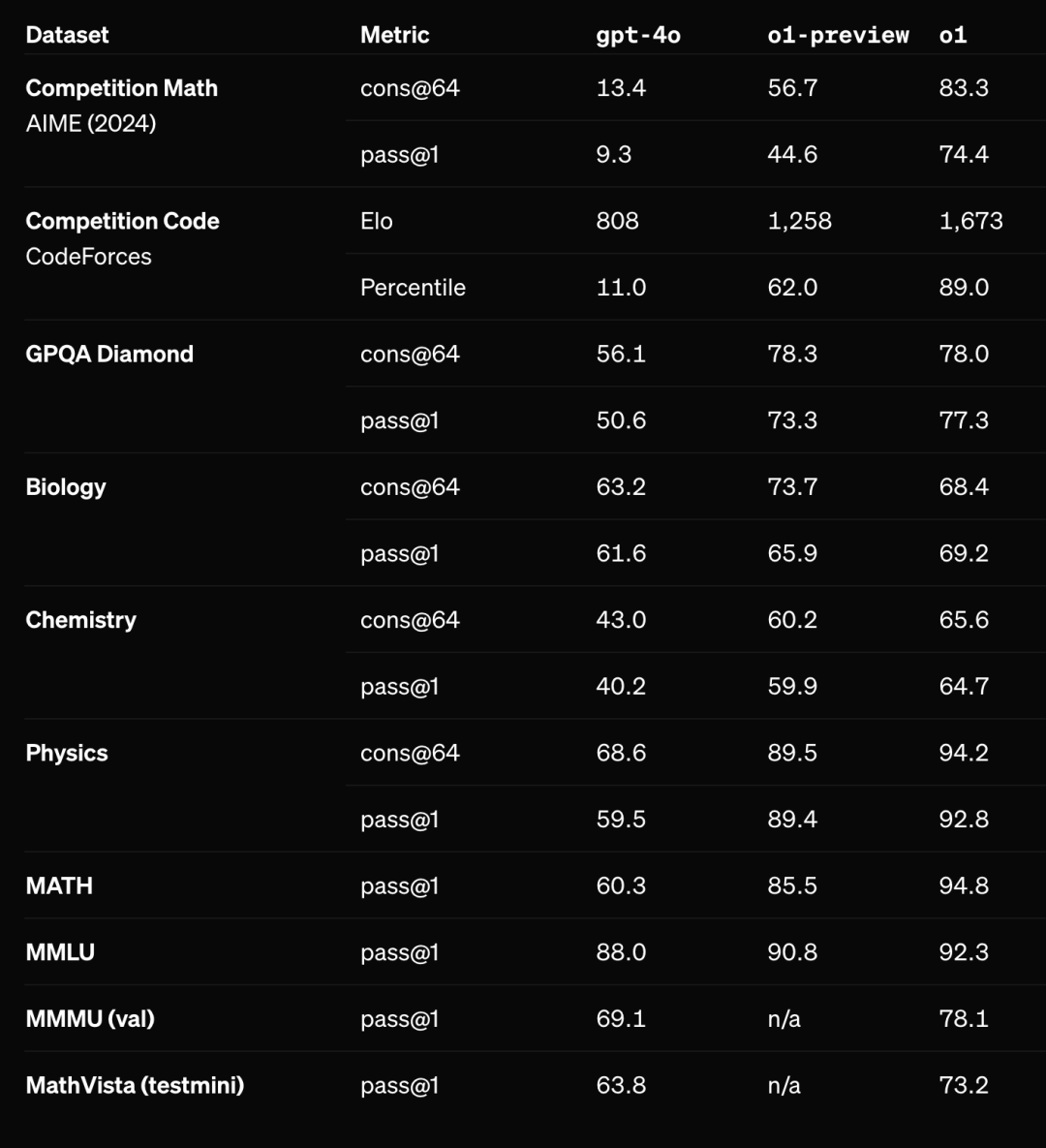
2.1 COT推理路径

-
其一为持续做预训练的scaling; -
其二为在后训练部分进行更加复杂的处理(可以理解为预训练是小孩子长大,后训练是对小孩子的教育)。
2.2 价格与token

2.3 模型大小推测
2.4 技术路径猜测(参考Paper)
-
OAI的技术路径没有披露,我们猜测在思路上借鉴/采用,或者与以下几种技术路径相似:
2.4.1 o1重要的五件事
|
|
Post-training 策略创新:Agent FT

Self play 或 RL 办法与合成数据
Reward Model的泛化性和连续性
Lean 是一种编程语言,通过计算机验证数据定理,广泛用在 AI 形式化数学证明中帮助 AI 理解数学题
1. Fine-tune Gemini 用于对数学问题形式化,生成了约100M 用于训练的数据。这个数据量远比人类解数学题需要的量大。
2. 用 AlphaProof 和 Lean Compiler 作为外部监督信号告诉 solver network 其答案是否正确(今年 IMO 的题目是可以验证答案是否错误的),再利用 MCTS 搜索更好的答案并训练。
3. 由于问题很难,Alphaproof 在推理过程中也会训练网络(这可能是为什么他耗时那么久的原因),即针对特定问题 MCTS 采样后,会把采样中较好的 reasoning path 再投入训练,这种做法相当于对特定任务 finetune。
4. AlphaProof & Alphageometry 2 拆成了两个策略网络来达到最好的效果。因为不同特定任务可能需要分别设置 prior,比如 AlphaGeometry 需要增加辅助线。
-
这一发现带来的思考是,主观任务也需要接近真实的reward,但比较难实现。物理、医药有明确的标准答案,但需要很长的实验验证周期,法律、金融的问题往往没有通用解法,很难用通用的 reward model 实现,文字创意领域的 reward 很多时候不符合马尔可夫模型,也就是其 reward 常常会有跳变。
使用 LLM 作为 PRM(process reward model)+ curriculum learning
|
|
Agent 设计或许all in FIREACT?
|
|

-
混合生成轨迹:利用强大的语言模型生成多种任务解决轨迹,结合了不同的提示方法(如ReAct、Chain of Thought (CoT) 和 Reflexion)。 -
统一格式与数据混合:生成的轨迹被统一转换为ReAct格式,这样可以在微调过程中使用相同的输入输出结构,便于模型理解和学习。在微调过程中,FireAct将来自不同提示方法的轨迹混合使用,这样可以增加训练数据的多样性,提升模型的泛化能力和鲁棒性。
-
自适应:在推理阶段,FireAct能够根据任务的复杂性自动选择最适合的提示方法,这种灵活性使得模型在不同情境下表现更佳。
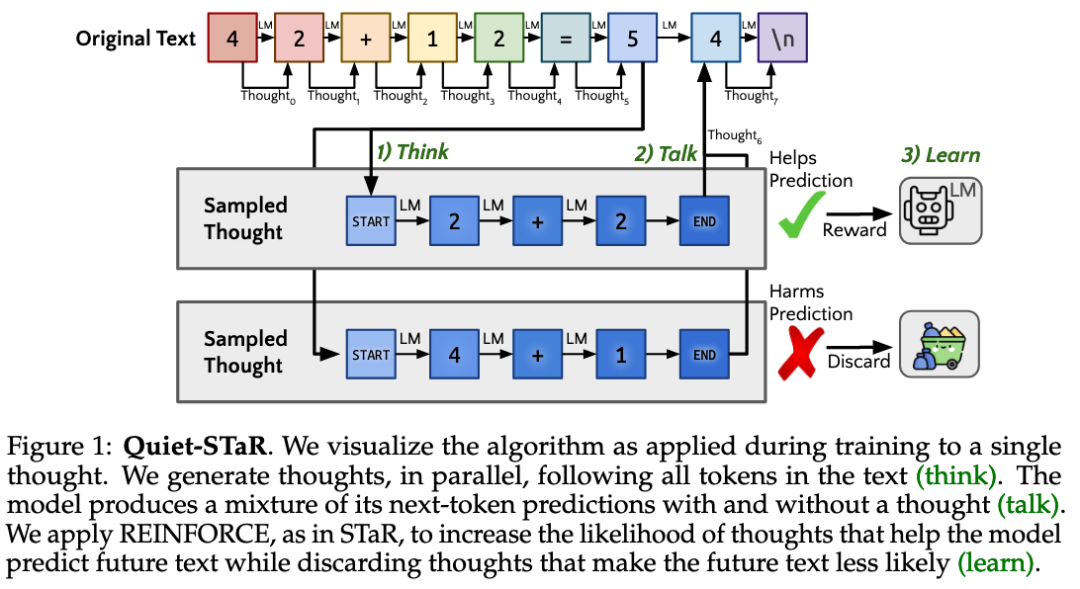
2.4.2 COT推理路径:STaR、Q-STaR、Quiet-STaR
STaR
|
|
Q-star
|
-
A*搜索算法是计算机科学中用于搜索两点之间最有效路径的算法。A*的原理是探索各种可能路径,根据距离、障碍物等因素计算每条路径的成本,然后使用这些信息来预测到达目标的最有效路线。 -
Q-learning是机器学习(强化学习)中的一种方法,其中,Agent学习做出可以获得最大reward的action。 -
“Q”=Quality”,指在特定状态下采取某种action获得的value/benefit。Agent会因为好的行为而受到奖励,因不好行为而受到惩罚。通过反复试验并从这些奖励和惩罚中学习,Agent逐渐了解实现其目标的最佳一系列action。
|
|
2.5 应用思考:Vertical reward model 会成为应用层的新主题
2.5.1 AI for developers——Cursor MPR | Cursor& Wordware
https://miracleplus.feishu.cn/docx/YYPhdNA4Tob32MxKP63ceXGsn3b?from=from_copylink
2.5.2 Two kinds of Vertical reward models
-
垂直行业 reward model,比如金融/法律,以 Harvey 为代表。
-
Agent 使用场景 reward model,比如操作浏览器,以 Induced AI 为代表。
Induced 是一个 AI-native 的浏览器自动化 RPA 平台。其收集用户使用数据的过程可以认为是在做 browser 领域的 reward model。 使企业能够用简单的自然语言输入 workflow,或给 AI 观看操作录屏视频,就能将指令实时转换为伪代码,模拟人类的网络浏览行为,自动浏览网页,收集并有效地处理和分析关键信息,来处理通常由后台管理的许多重复性任务,如销售、合规、内部运营等方面。 它应用了一种双向交互系统,允许人类根据需要在某些步骤中进行干预,而其余步骤则由 AI 自主管理。
2.6 问题测试效果

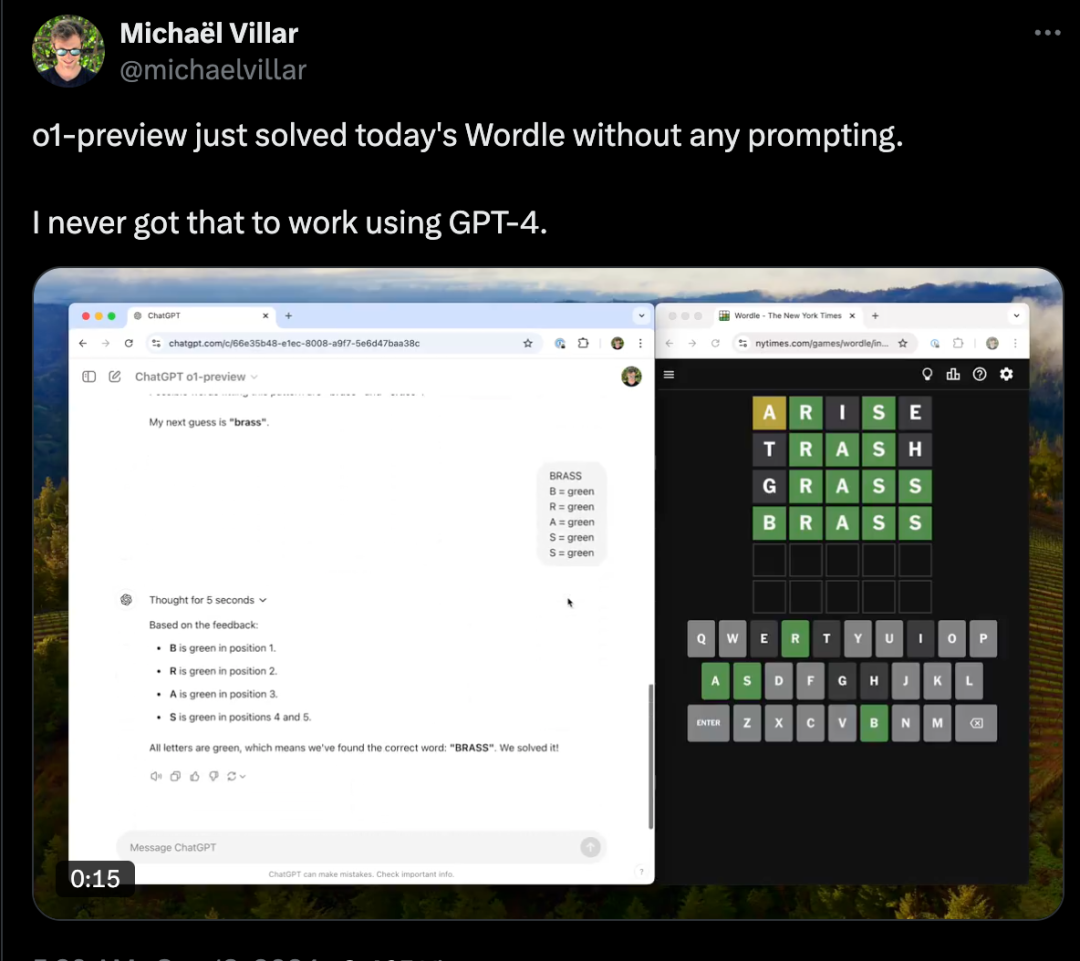
Michaël Villar:“顺利解答今天发布的猜词游戏,使用GPT-4从未成功做到这一点。”



|
3.1 推理能力和计算资源

-
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling. 在 SWE-Bench 上,DeepSeek-Coder 从一个样本的 15.9% 增加到 250 个样本的 56%,击败了 Sonnet-3.5。
-
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters. PaLM 2-S 在 MATH 上击败了一个体积大 14 倍的模型。
3.2 计算效率、对齐与开源

3.3 CoT观察

3.4 Github Copilot 结合 o1 的潜力
-
优化复杂的算法与先进的推理:Copilot 团队真实的问题。 -
优化应用程序代码以修复性能错误: 真是问题,o1 花费 minutes,engineer 花费 hours。

3.5 多工具整合&文档规划与输出生成的潜力
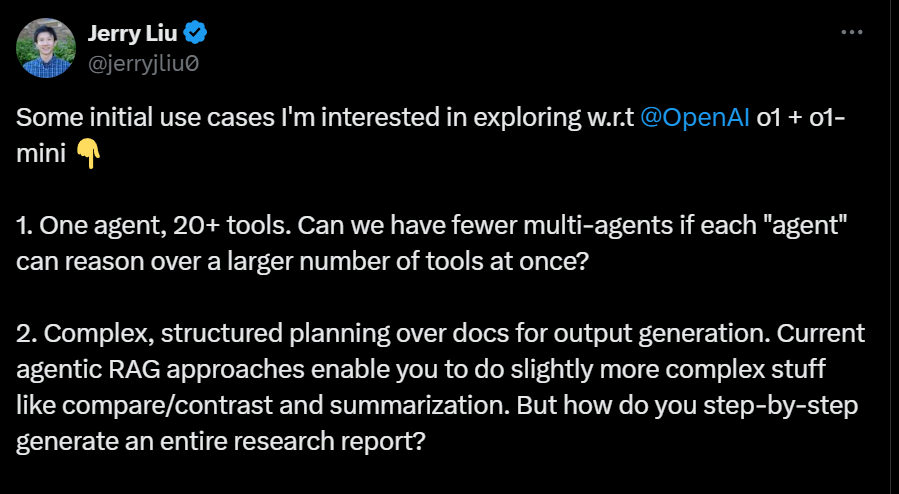
-
多工具整合:对一个agent能够同时处理20多个工具。如果每个agent可以一次性使用更多的工具,是否可以减少对multi-agents的需求?
-
复杂、结构化的文档规划与输出生成:目前的代理型 RAG 能够执行稍微复杂的任务,如比较、对比和摘要。但如何一步一步地生成一整份研究报告,即在文档生成中进行复杂的、结构化的规划?
https://openai.com/openai-o1-contributions/
-
Hongyu Ren 
-
Shengjia Zhao
-
Kevin Lu
-
Wenda Zhou
-
Jiahui Yu
小编寄语
— END —
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/09/21073.html