


最近,国外的一份研究报告揭秘了 OpenAI、围绕和谷歌在 AI Infra 层的布局,我们将文章提炼出了核心观点,并进行精校翻译。
核心观点
1. AI模型越来越大,让基础设施需求激增,前沿AI模型训练集群已达万卡级,并且需求持续增长,同时大规模训练从单一数据中心逐渐转向多数据中心;
2. 高密度液冷 AI 芯片越发受到关注,Google 早年开始的持续布局已然于基础设施方面远超竞争对手;
3. 相比于模型架构等技术,各家厂商私有的容错训练技术成为更重要的更封闭的技术;
4. 大模型训练机制将逐渐由同步训练转向异步训练;
5. 格局方面,Google 在基础设施上有着巨大优势,但微软和OpenAI联合供应链合作商们,正多方面极速追赶;
6. 2025 年,电信行业将迎来显著增长,并且产生的实际影响或将震惊所有人。未来将有超过 100 亿美元的电信资本支出专门用于多数据中心训练,在新增量驱动因素将伴随着市场的周期性回升。
以下是文章精校翻译,预计阅读时长 30 分钟。
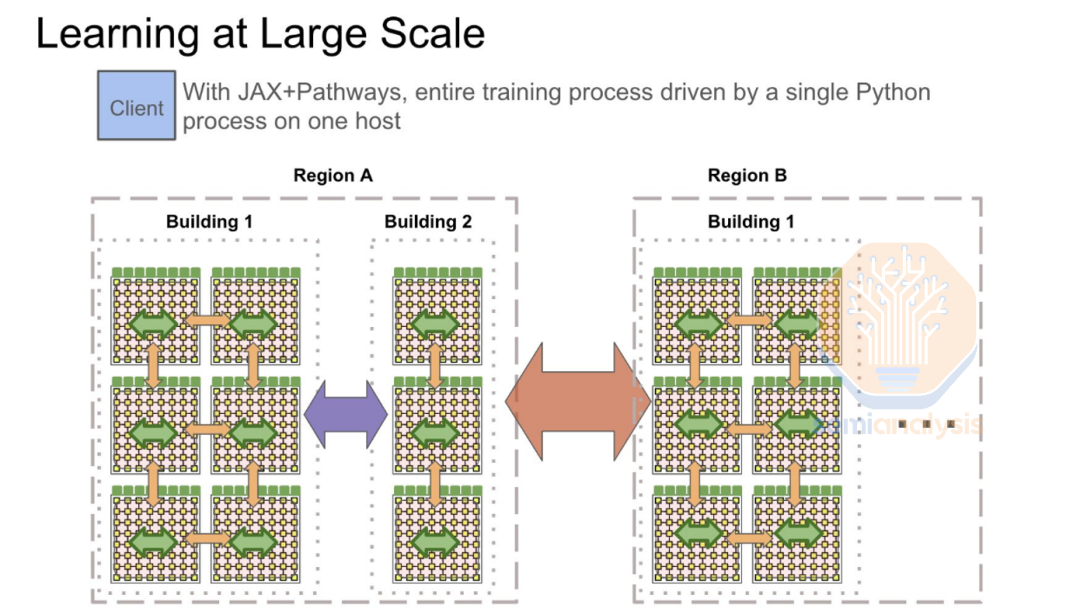
由于 Scaling Law 的持续推进,AI 基础设施建设的需求也不断增加。最领先的 AI 模型训练集群,今年已扩展到 10 万个 GPU ,并计划到 2025 年将超过 30 万个 GPU 集群。考虑到时间成本、政策法规和可用电力资源等物理限制,传统的同时训练单个数据中心站点的大模型方法,已达到临界点。
Google、OpenAI 和 Anthropic 已经在执行一个计划,即将其大模型训练从一个站点扩展到多个数据中心(Multi-Datacenter)。谷歌拥有当今世界上最先进的计算系统,并率先大规模使用了许多关键技术,这些技术直到现在才被其他公司采用,例如机架级液冷架构(rack-scale liquid cooled architectures)和多数据中心训练(multi-datacenter training)。
Gemini 1 Ultra 在多个数据中心上进行了训练。尽管他们拥有更多的 FLOPS(意指每秒浮点运算次数,理解为计算速度,是一个衡量硬件性能的指标),但他们现有的模型仍落后于 OpenAI 和 Anthropic,因为他们在合成数据、强化学习和模型架构方面仍在追赶,但即将发布的 Gemini 2 会改变这一现状。
此外,到 2025 年,谷歌将有能力在多个计算中心园区,进行千兆瓦级的训练。但令人惊讶的是,谷歌的长期计划并不像 OpenAI 和微软那么积极。
来源:Google
大多数公司才刚刚开始引入高密度液冷 AI 芯片,这些芯片采用 Nvidia 的 GB200 架构,预计明年将会达到数百万的出货量。而 Google 早已部署了数百万的液冷 TPU,液冷 AI 芯片的总容量超过 1 吉瓦(GW)。如此来看,基础设施方面,Google 与其竞争对手之间的差异性优势显而易见。

来源:https://www.semianalysis.com/p/datacenter-model
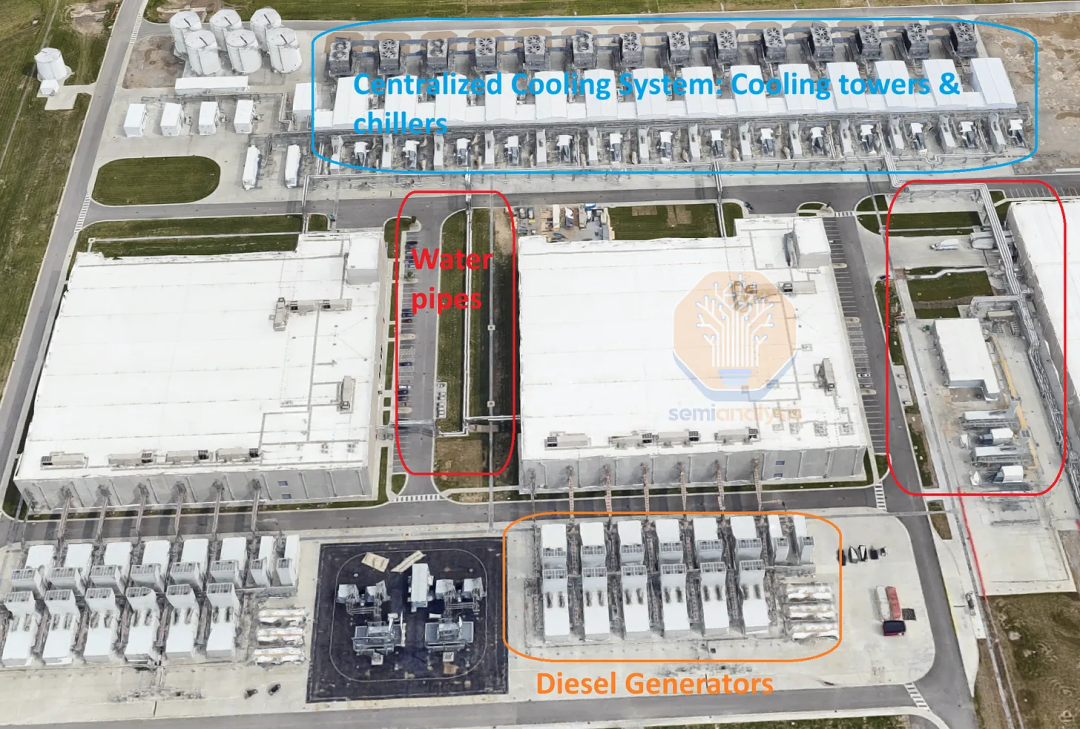
上图展示的 AI 训练园区,目前的电力容量接近 300 兆瓦(MW),预计明年将提升至 500 兆瓦。除了规模庞大,这些设施的还非常节能。我们在下图可以看到,由水管连接的巨大的冷却塔和中央供水系统,能够散发近 200 兆瓦的热量。
借助这一系统,Google 在大部分时间无需使用传统冷却器,根据最新的环境报告,该系统允许 Google 全年大部分时间无需使用冷却器即可运行,从而在 2023 年实现 1.1 PUE(能源使用效率,PUE 值越低,表明数据中心的能效越高)。
Source: Google
虽然上图只展示了设施的供水系统,但水也通过 Direct-to-Chip 系统输送到机架,液-液热交换器再将机架产生的热量传递到中央设施供水系统。这个极节能的系统与我们之前在 GB200 深度分析中提到的 Nvidia GB200 的 L2L 部署非常相似。
GB200 Hardware Architecture – Component Supply Chain & BOM:https://www.semianalysis.com/p/gb200-hardware-architecture-and-component
另一方面,Microsoft 目前最大的训练集群(如下图所示)并不支持液冷系统,尽管建筑的总建筑面积大致相同,但每栋建筑所能支持的计算资源却低了约 35%。公开数据显示其 PUE 为 1.223,但实际 PUE 计算因为不计入服务器内部风扇消耗,故对风冷系统更有利(以 H100 服务器为例,风冷系统中的风扇能耗占服务器总功率的 15% 以上,而液冷系统中仅占不到 5%)。
因此,对于提供到芯片的每瓦功率,Microsoft 需要额外增加大约 45% 的电力来供给服务器风扇、冷却设施以及其他非计算资源负载,而 Google 只需要额外增加约 15%,若是再加上 TPU 的更高效率,这两者对比的情况就会更加模糊复杂。

Source: SemiAnalysis Datacenter Model
此外,为了在沙漠地区(如亚利桑那州)实现合理的能源效率利用,Microsoft 需要大量用水,其水利用率(WUE,数值越小,代表数据中心利用水资源的效率越高)达到了 2.24 升/千瓦时,远高于行业平均的 0.49,Google 的平均值也仅略高于 1。
这种高水耗被许多媒体关注到,因此他们被要求在即将建设的数据中心中改用风冷式冷水机,这将减少每栋建筑的用水量,但会进一步增加 PUE,从而扩大与 Google 在能源效率上的差距。在后续的报告中,我们将更详细地探讨数据中心的运作方式以及典型的超大规模设计方案。
因此,基于现有的数据中心参考设计,Google 拥有更高效的基础设施,并且能够更快地建设兆瓦级数据中心,因为每栋建筑的容量超过 50%,且每单位 IT 负载所需的公共电力更少。
谷歌 AI 训练基础设施
Google 在建设基础设施方面一直有着独特的方式,虽然他们的单个数据中心设计已经领先于 Microsoft、Amazon 和 Meta,但这还不足以全面展现他们在基础设施方面的优势。
Google 在过去十多年中不断建设大规模的园区,一个很好的例子就是位于爱荷华州 Council Bluffs 的 Google 站点,尽管已经有多年历史,但其西部区域的 IT 容量仍接近 300 MW。
虽然其中相当一部分容量用于传统工作负载,但我们相信底部的建筑容纳了大量的 TPU。而东部的扩展区域采用了最新的数据中心设计,将进一步提升 AI 训练的能力。

Source: SemiAnalysis Datacenter Model
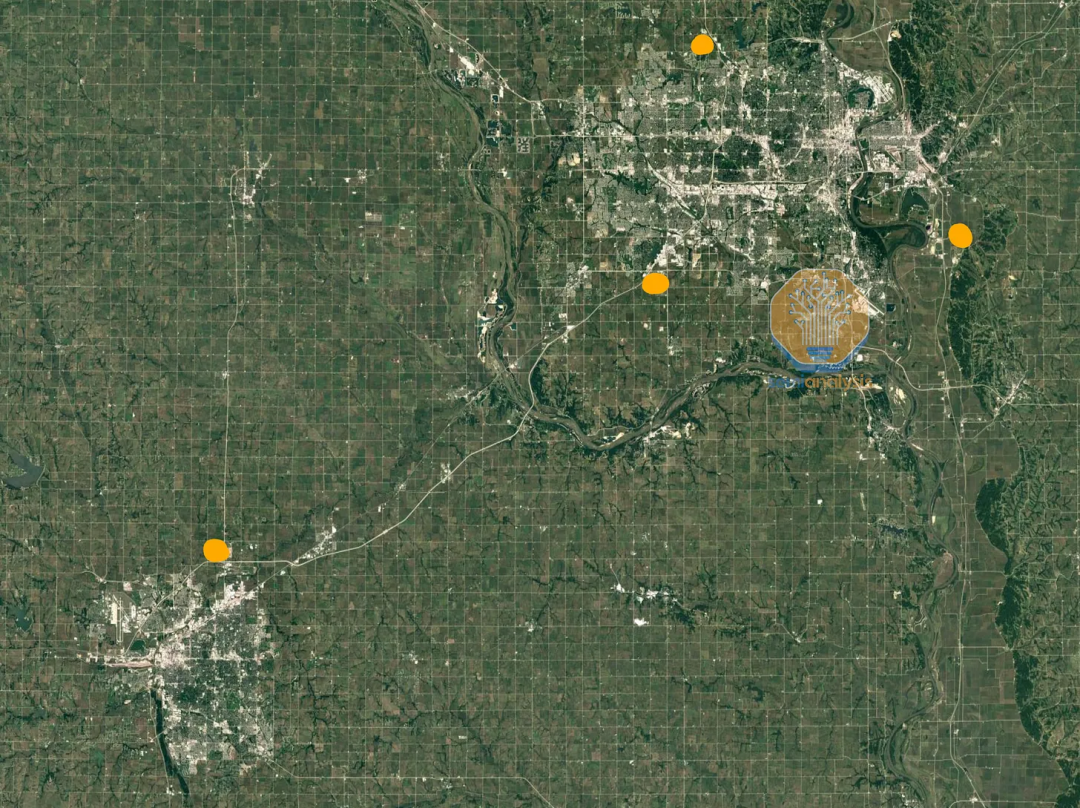
Google 最大的 AI 数据中心彼此之间也非常近。Google 有两个主要的多数据中心区域,分别位于俄亥俄州和爱荷华州/内布拉斯加州。如今,围绕 Council Bluffs 的区域正在积极扩建,容量将超过现有的两倍。
除了上面提到的园区外,Google 在该地区还拥有另外三个正在建设中的站点,并且这些站点都在升级高带宽光纤网络。
Source: SemiAnalysis Datacenter Model
在这片区域内,有三个站点相距约 15 英里,分别是 Council Bluffs、Omaha 和 Papillon Iowa,另一个站点位于 50 英里外的 Lincoln Nebraska。
下图展示的 Papillion 园区将为 Google 在 Omaha 和 Council Bluffs 周边的业务增加超过 250 兆瓦的容量,与前面的站点合计,在 2023 年总容量超过 500 兆瓦,其中大部分被分配给 TPU。

Source: SemiAnalysis Datacenter Model
另外两个站点虽然规模尚不如其他站点大,但正在快速扩建,四个园区合并后,预计到 2026 年将形成一个千兆瓦级的 AI 训练集群。距离约 50 英里的 Lincoln 数据中心将成为 Google 最大的单个站点。
而 Google 庞大的 TPU 部署还远不止于此,另一个即将建成的千兆瓦级集群位于俄亥俄州哥伦布附近,该地区采用类似的模式,三个园区正在开发中,预计到 2025 年底总容量将达到 1 吉瓦!
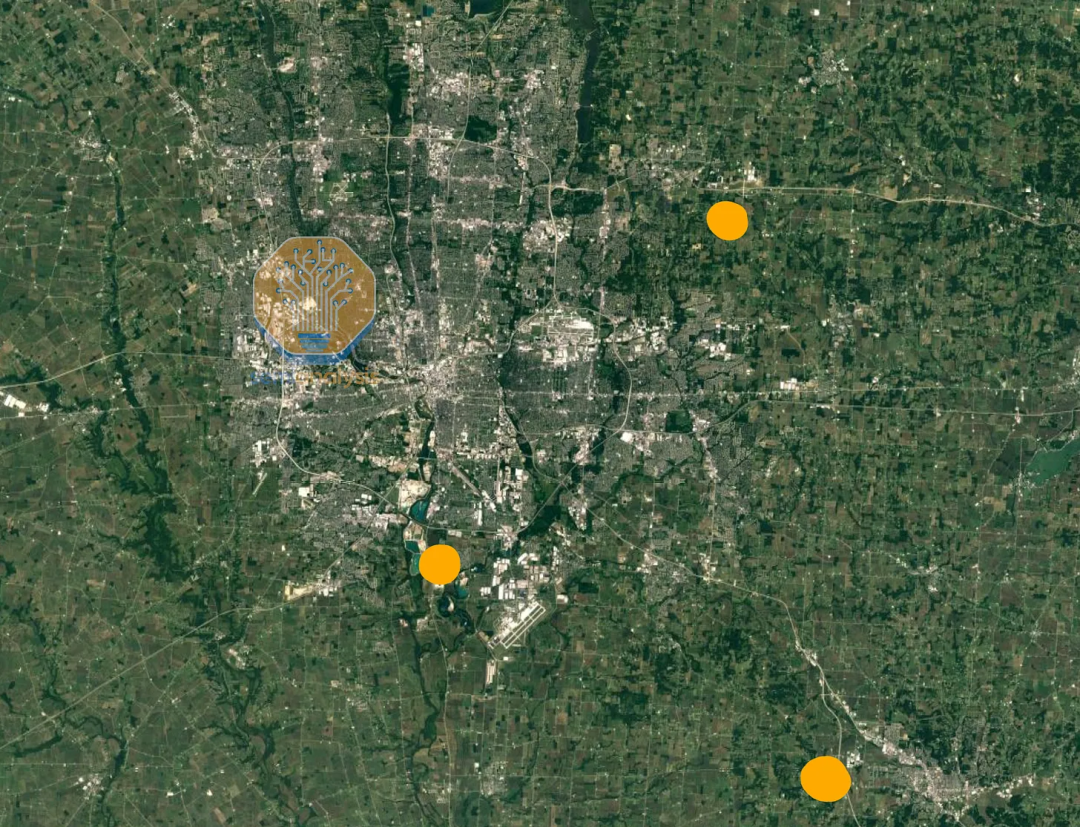
Source: SemiAnalysis Datacenter Model
下图展示的 New Albany 集群将成为 Google 最大的集群之一,目前已经部署了 TPU v4、v5 和 v6。

Source: SemiAnalysis Datacenter Model
Google 在俄亥俄州和爱荷华州/内布拉斯加州的集中数据中心区域还可以进一步互联,为单个模型训练提供多吉瓦的算力支持。
我们在数据中心模型中详细记录了超过 5,000 个数据中心的季度历史和预测电力数据,涵盖了 AI 实验室、超大规模计算(hyperscalers)、新型云服务(neoclouds)以及企业的集群建设情况。关于多数据中心训练的软件栈和方法将在本文后续部分进行详细讨论。
Microsoft 和 OpenAI 的反击?