我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


论文
Discovering the Gems in Early Layers: Accelerating Long-Context LLMs with 1000x Input Token Reduction
大型语言模型 (LLM) 在处理长上下文输入方面表现出了卓越的能力,但这是以增加计算资源和延迟为代价的。我们的研究为解决长上下文瓶颈引入了一种新方法,以加速 LLM 推理并减少 GPU 内存消耗。我们的研究表明,LLM 可以在生成查询答案之前识别早期层中的相关标记。利用这一见解,我们提出了一种算法,该算法使用 LLM 的早期层作为过滤器来选择和压缩输入标记,从而显著减少后续处理的上下文长度。与标准注意和 SnapKV/H2O 等现有技术相比,我们的方法 GemFilter 在速度和内存效率方面都有了显著的提升。值得注意的是,它实现了 2.4×。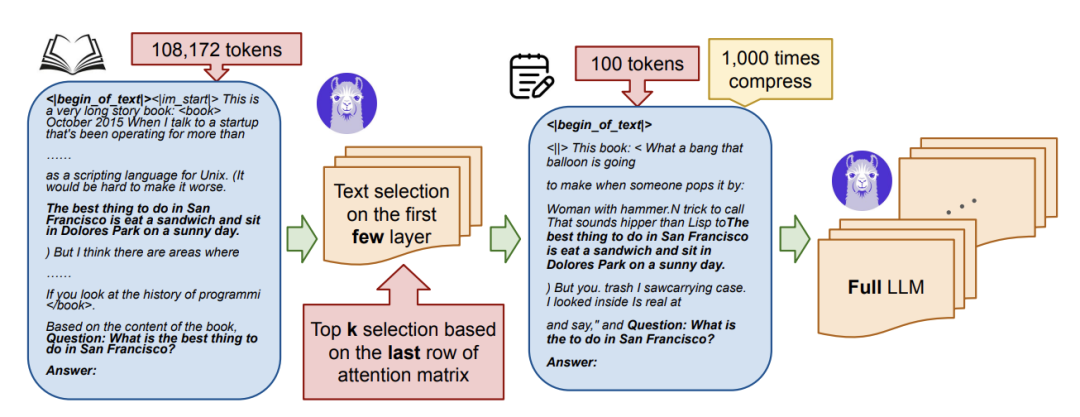 https://www.arxiv.org/abs/2409.17422
https://www.arxiv.org/abs/2409.17422
Eureka: Evaluating and Understanding Large Foundation Models
严格且可重复的评估对于评估最新技术水平和指导人工智能的科学进步至关重要。由于多种原因,评估在实践中具有挑战性,包括基准饱和、用于测量的方法缺乏透明度、提取生成任务的测量值方面的开发挑战,以及更普遍地说,对模型进行全面比较所需的大量功能。我们为缓解上述挑战做出了三项贡献。首先,提出了 Eureka,这是一个开源框架,用于标准化大型基础模型的评估,而不仅仅是单一分数报告和排名。其次,引入了 Eureka-Bench 作为基准测试功能的可扩展集合,这些功能 (i) 对于最先进的模型来说仍然具有挑战性,(ii) 代表了基本但被忽视的语言和多模式功能。非饱和基准测试中固有的改进空间使我们能够在能力层面发现模型之间的有意义差异。第三,使用 Eureka 对 12 个最先进的模型进行了分析,深入了解了故障理解和模型比较,可以利用这些见解来规划有针对性的改进。与报告和排行榜中显示绝对排名并声称某个模型是最好的趋势相反,分析表明,没有最好的模型。不同的模型有不同的优势,但有些模型比其他模型更经常出现在某些功能上表现最佳。尽管最近有所改进,但当前的模型仍然难以掌握几个基本功能,包括详细的图像理解、在可用时从多模式输入中受益而不是完全依赖语言、事实性和信息检索基础以及过度拒绝。
https://arxiv.org/abs/2409.10566
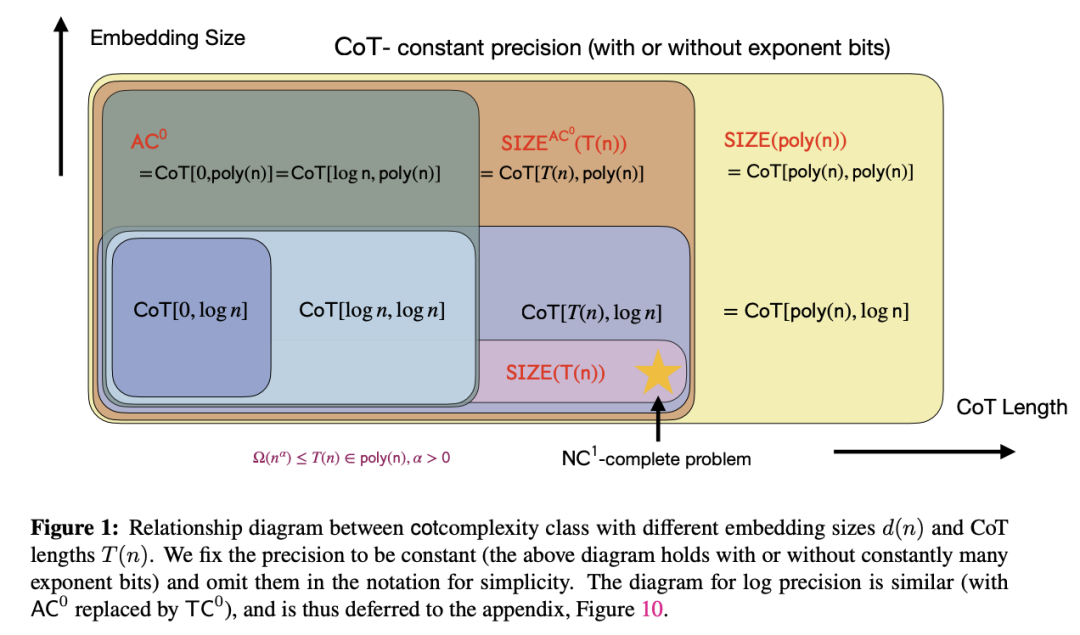
Chain of Thought Empowers Transformers to Solve Inherently Serial Problems
指示模型生成一系列中间步骤,即思路链 (CoT),是一种非常有效的方法,可以提高大型语言模型 (LLM) 在算术和符号推理任务上的准确性。然而,CoT 背后的机制仍不清楚。这项工作从表达能力的角度,为仅解码器的 Transformer 提供了 CoT 的强大功能的理论理解。从概念上讲,CoT 赋予模型执行固有串行计算的能力,而 Transformer 则缺乏这种能力,尤其是在深度较低的情况下。
https://arxiv.org/abs/2402.12875
Human-like Affective Cognition in Foundation Models
理解情绪是人类互动和体验的基础。人类很容易从情境或面部表情推断情绪,从情绪推断情境,并进行各种其他情感认知。现代人工智能在这些推理方面有多熟练?我们引入了一个评估框架来测试基础模型中的情感认知。从心理学理论出发,我们生成了1,280个不同的场景,探索评估、情绪、表情和结果之间的关系。我们在精心选择的条件下评估基础模型(GPT-4、Claude-3、Gemini-1.5-Pro)和人类(N =567)的能力。我们的结果表明,基础模型倾向于与人类直觉一致,达到或超过参与者之间的一致性。在某些情况下,模型是“超人”—一它们比普通人更能预测模态人类判断。所有模型都受益于思路链推理。这表明基础模型已经获得了类似人类对情绪及其对信仰和行为影响的理解。

https://arxiv.org/abs/2409.11733
Retrieval-based-Voice-Conversion-WebUI
这个项目是一个基于 VITS 的简单易用的变声框架,本仓库具备高效训练、音色控制和易用性等特点,支持在低配置显卡上快速训练,使用少量数据仍能取得良好效果,提供网页界面和 UVR5 模型进行人声与伴奏分离,采用先进的音高提取算法以解决哑音问题。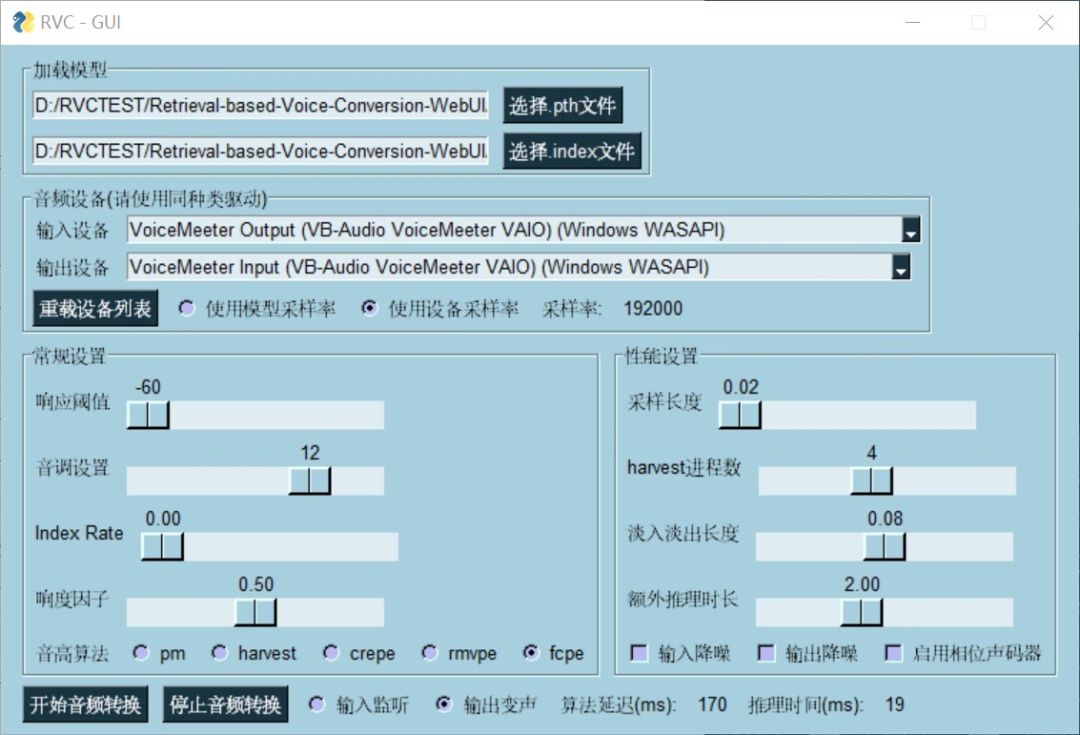
https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI
Disco4D
Disco4D 是一种新颖的高斯框架,能够从单张图像生成和动画化 4D 人体。它通过将服装与人体解耦,采用高效的高斯拟合和扩散模型,显著提高了生成细节和灵活性,同时支持生动的 4D 动态动画。
https://disco-4d.github.io/
— END —
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/10/21449.html

