我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢 迎 大 家 一 起 交 流 !
资讯 奥特曼:自认比o1聪明请举手🤚到o2还这么想么🤨? 在本次对话中,OpenAI首席产品官Kevin Weil和奥特曼(Sam Altman)就未来人工智能的发展趋势和技术创新进行了深入探讨。奥特曼预测,未来十年内将实现无限上下文长度,并认为智能体(Agents)技术将推动AI应用的广泛普及。人们会要求AI在极短时间内完成过去需要数月或数年的工作,最终每个人将拥有数十甚至数千个智能体。 此外,奥特曼特别强调了对科幻设想的关注,并指出这是AI发展过程中不可忽视的重要问题。
实时语音API:开放测试版,所有开发者都能在自己的APP中实现与ChatGPT高级语音模式类似的体验。语音输入每分钟收费0.06美元,语音输出每分钟收费0.24美元。语言学习应用Speak已率先采用此功能开发AI角色扮演练习模式。
视觉微调API:开发者可通过上传少量图像对GPT-4o进行微调,以提升其在特定视觉任务中的表现,如物体检测、医学图像分析等。只需使用100张图像即可显著提升模型性能,微调费用为每百万tokens 25美元。
自动提示词缓存功能:在多个API调用中自动缓存相同上下文,从而降低推理延迟与成本。该功能已适配GPT-4o和o1系列模型,并对已见过的tokens提供五折优惠。
模型蒸馏API:允许开发者用前沿模型(如GPT-4o)的输出对小型模型(如GPT-4o mini)进行微调,大幅简化了以往多步骤、易出错的蒸馏流程。该功能通过集成工作流程自动生成输入-输出对并完成微调。
在现场演示环节,GPT-4o驱动的实时语音API结合Twillio实现了电话订购草莓甜点的功能。此外,最新发布的o1模型在无人机编程操控方面也展现了强大的推理能力。 活动结束后,OpenAI离职高管的去向引发了广泛关注。前研究副总裁Barret Zoph计划成立新公司,前CTO Mira Murati也受到投资人的热捧。与此同时,前OpenAI联合创始人Durk Kingma宣布加入Anthropic团队。 今年的OpenAI开发者日与去年不同,没有全程直播,并在美国、英国和新加坡分地点举行。OpenAI在活动上强调了其在API生态上的多项技术进展,展示了模型推理和应用场景的最新成果。
OpenAI重磅发布Canvas:跟ChatGPT一起写作编程 OpenAI 最近发布了全新的创作和编程界面——Canvas,与ChatGPT合作的增强交互功能引发广泛关注。该功能由OpenAI的GPT-4o模型提供支持,用户需在模型选择栏中选择“GPT-4o with canvas”才能使用。 Canvas模式打破了传统对话框架,为用户提供了编辑、创作和编程的新方式。它允许用户对生成内容进行二次创作和编排,就像使用文案或代码编辑器一样。用户可以通过右下角的“编辑”按钮,使用五个主要功能进行操作:编辑建议、调整上下文长度、改变阅读水平、添加最终润色以及添加表情包。用户可选择要修改的内容片段,并进行细节上的重新生成和微调。这种模式不仅提高了创作效率,也让内容生成变得更具灵活性和可控性。 Canvas功能迅速引起了业界的高度评价。沃顿商学院教授Ethan Mollick认为,这种模式让ChatGPT更像是一个协作同事,而不是简单的聊天机器人。许多网友也认为这是今年ChatGPT最大的更新之一。 除了文本创作,Canvas在编程方面也提供了审查代码、添加日志、添加注释、修复bug和转换语言等功能。用户可以选择代码片段,让模型按照要求修改代码,甚至手动更改特定细节。转换编程语言的功能支持多种语言,包括JavaScript、Python、Java等。 Canvas的推出提升了用户与AI模型的交互体验。通过自动化内部评估和合成数据生成技术,OpenAI实现了更高效的模型调优。Canvas模式的生成质量比带有提示指令的GPT-4o高出30%的准确率,质量提升16%。 目前,Canvas面向ChatGPT Plus和Team用户开放,并将在下周扩展到Enterprise和Edu用户。虽然与Claude的Artifacts功能有些相似,但Canvas在写作和编程的细节处理上更进一步。总体来看,Canvas为AI创作与编程提供了更为全面的支持,成为OpenAI生态中的重要创新。
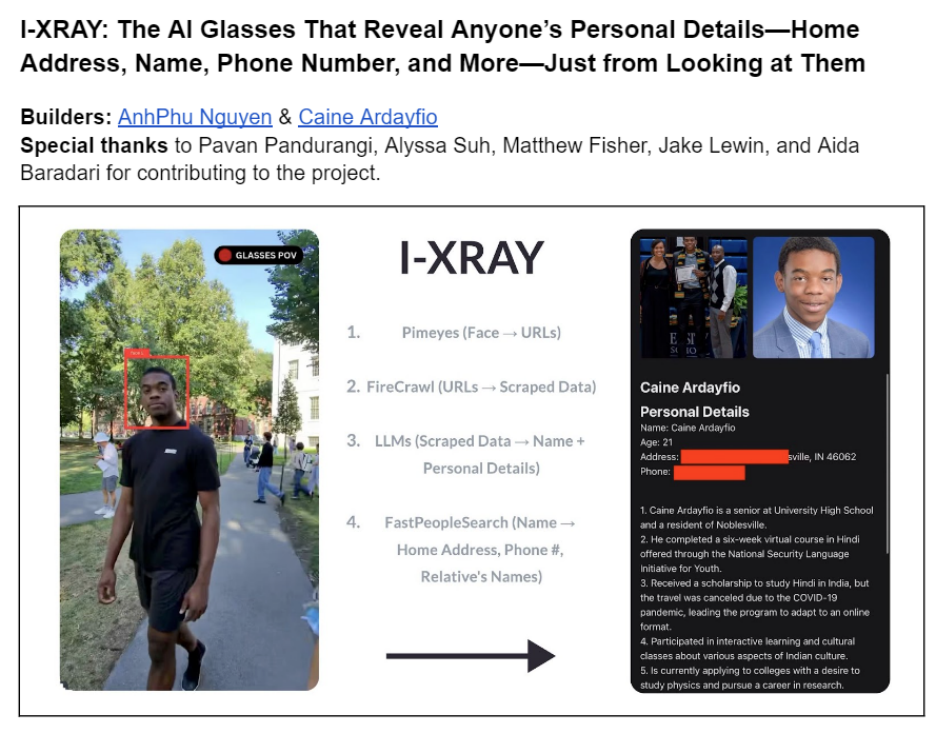
https://mp.weixin.qq.com/s/ZgAqgGfpHJkWf808MRb_Mw Meta将智能眼镜与人脸搜索结合引发隐私担忧 在AI技术的推动下,Meta的虚拟现实(VR)头显Quest 3S和增强现实(AR)眼镜Orion备受瞩目。此外,Meta还宣布升级其雷朋(Ray-Ban)智能眼镜,新增AI功能,预计今年出货量将突破200万台。尽管这款眼镜在消费市场上大获成功,但隐私问题一直备受关注,尤其是设备可能被滥用及数据使用透明度的质疑。 哈佛大学的两名学生安福·阮(AnhPhu Nguyen)和凯恩·阿达菲奥(Caine Ardayfio)通过实验展示了这种隐私风险。他们将Meta的雷朋智能眼镜与人脸搜索引擎PimEyes相结合,开发了一个名为I-XRAY的系统。该系统能够通过捕捉路人的人脸信息,在几秒钟内收集目标的个人隐私数据,包括姓名、地址和电话号码。在地铁站测试中,他们成功识别了数十位路人的身份,并利用这些信息假扮熟人进行互动。 这项实验引发了对隐私保护的广泛担忧。尽管两位学生没有公开系统代码,但他们希望借此研究提高公众对隐私泄露的警惕,并提供了从PimEyes等平台移除个人信息的指南。 Meta在使用AI训练数据的政策上也引发争议。其政策表明,所有经过AI分析的图像,包括通过智能眼镜采集的内容,都可能被用于模型训练。此外,Meta还推出了实时视频分析功能,能够在未明确告知用户的情况下持续将图像传输给AI模型进行处理。该公司此前因Facebook平台上的面部识别技术问题支付了14亿美元和解金,而其现行的隐私政策仍默认储存所有通过Ray-Ban设备记录的语音对话,用于训练未来的AI模型。 这一系列隐私事件凸显了智能设备、AI技术与个人隐私保护之间的复杂关系。在欧盟,《通用数据保护条例》(GDPR)对面部识别数据的收集进行了严格限制,但在美国,由于缺乏统一的隐私法律,此类技术更容易被滥用。
https://mp.weixin.qq.com/s/nybGteiVjlLCvqLO7UB1uw Reflection-70B模型发布后的技术反思
复现流程:使用相同的评估框架、提示词和输出提取方法来复现初始的基准测试分数,并修复系统提示的差异。
工具和资源:提供了模型权重、训练数据、训练脚本和评估代码(相关链接见文末),供社区成员验证模型性能。
HumanEval:89.02%(原报告:91%)
IFEVAL:87.63%(原报告:90.13%)
由于在初始代码中存在MATH和GSM8K评估中的漏洞,导致初始分数存在偏差(如MATH从79.7%降至70.8%)。
使用 llm-decontaminator 工具检测数据集是否与基准测试存在重合,未发现显著重合部分。
进一步测试模型是否能够生成与基准测试中相似的内容,发现约6%的MMLU测试集问题可以被模型生成。这表明可能存在间接的训练数据集污染。
模型开发:模型开发过程中,尝试了多个数据迭代并在较小的模型上进行了反复验证,但最终版本的70B模型未经过充分的测试。
模型发布问题:模型发布时未验证上传的权重是否正确、模型配置文件是否与实际模型一致,导致了配置文件错误(例如,config.json中写着Llama 3而非Llama 3.1),影响了模型性能。
API表现问题:在使用API时,模型生成了与Claude模型相同的随机数,出现了奇怪的响应行为(如生成”Anthropic”相关信息),这引发了关于API是否实际调用了Claude模型的质疑。
发布前未能验证模型的完整性和准确性,导致了大量不可控的问题。
对于社区反馈的处理过于仓促和被动,未能及时解决问题。
在未来的开发和发布中,应加强模型测试、分数验证和代码管理,并在公开发布前确保模型的一致性和准确性。
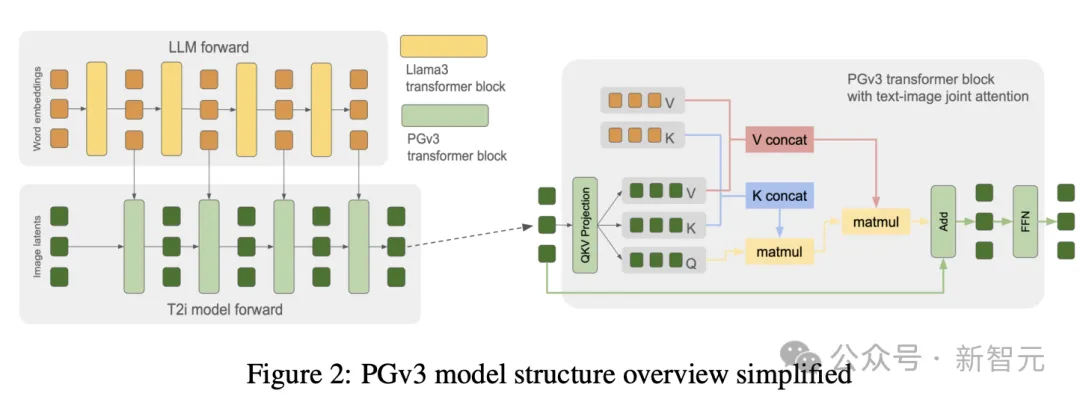
https://glaive.ai/blog/post/reflection-postmortem Playground v3发布:深度融合LLM,图形设计能力超越人类 PGv3与传统模型不同之处在于其创新的深度融合(Deep-Fusion)架构,完全集成了大型语言模型(LLMs),使用解码器(decoder-only)模型进行文本到图像生成,而不是依赖预训练语言模型如T5或CLIP文本编码器。此外,PGv3引入了内部描述生成器(in-house captioner),生成不同详细程度的描述,并提出了新的图像描述基准CapsBench用于评估模型在复杂推理和文本渲染上的性能。 实验表明,PGv3在提示词遵循、复杂推理、RGB颜色控制和多语言理解方面具有显著优势。用户偏好研究显示,PGv3在表情包、海报和logo设计等常见应用中表现超越人类设计水平。 PGv3的架构设计采用了DiT风格的Transformer模型,与Llama3-8B的各个层次紧密集成,通过从LLM每层提取隐藏嵌入输出,充分利用LLM的「思考过程」,从而提升生成图像时的提示遵循和一致性。为了优化模型性能,PGv3采用了以下策略:
Transformer块之间引入U-Net跳跃连接。
中间层进行token下采样,使图像键和值序列长度缩短四倍。
使用2D版本的旋转位置嵌入(RoPE),解决图像分辨率变化带来的过拟合问题。
此外,PGv3升级了变分自编码器(VAE),将潜通道数从4增加至16,并扩展至512×512分辨率,提高了细节重建能力。实验显示,PGv3在生成复杂图像时展现出更好的细节保留和纹理还原能力。 新基准CapsBench评估了PGv3的描述能力,通过问答方式全面考察图像描述的精确性和详细程度,覆盖了17种图像类别和2471个问题。测试结果显示,PGv3在图像描述的语义理解和细节捕捉上优于其他模型。
全球首台Arm超算光荣退役!下一代已接任,配备384块英伟达Grace CPU
世界上首台基于Arm架构的超级计算机——Isambard 2,近日正式退役。该系统于2018年部署,搭载由Cavium开发的64位Armv8 ThunderX2处理器,配备部分Nvidia P100 GPU。项目由布里斯托尔大学的Simon McIntosh-Smith教授领导,并将于9月30日关闭数据访问权限。 Isambard 2的退役标志着其6年使命的完成,并将由新一代的Isambard 3超算接任。Isambard 3基于NVIDIA Grace CPU,拥有34,272个核,性能和能效预计为前代的6倍,成为欧洲最节能的系统之一,峰值性能可达2.7 petaflops(FP64),功耗不足270KW,在Green500排行榜上名列第二。 下一代Isambard 3将继续推动生命科学、医学和天体物理等领域的研究进展。它能够高效模拟风力发电场、聚变反应堆等复杂模型,支持研究人员开发清洁和绿色能源的新方法。同时,Isambard 3还将用于研究帕金森氏症、骨质疏松症和新冠肺炎的治疗方法。 Isambard 2的退役并非孤例,橡树岭国家实验室的Summit超算也将在今年11月退役。Summit同样于2018年投入使用,其功能将被新一代Frontier超算所取代。Frontier目前位列全球TOP500超算榜单榜首,是首个达到百亿亿次浮点运算性能的系统。Aurora位居第二,成为全球第二台突破百亿亿次计算级别的超算。 尽管Isambard 3目前尚未进入TOP500榜单,但其在未来更新时有望进入前十名,成为全球最强的超级计算机之一。项目由布里斯托尔大学牵头,巴斯大学、卡迪夫大学和埃克塞特大学参与,共同推动超级计算技术的发展。
Mirage零门槛生成PyTorch算子 近日,来自卡内基梅隆大学(CMU)Catalyst Group 的团队发布了一款名为 Mirage 的 PyTorch 算子编译器。Mirage 能够自动生成高效的 GPU 内核,用户无需编写 CUDA 或 Triton 代码即可实现优化,显著提升了 PyTorch 程序的计算性能。 GPU 加速器的进步和大语言模型(LLM)等生成式 AI 应用的广泛使用,使得高效 GPU 内核开发变得至关重要。然而,编写高性能 GPU 内核通常需要深厚的 GPU 知识和工程经验。现有的机器学习编译器(如 TVM、Triton 和 Mojo)尽管简化了 GPU 编程,但依然依赖用户设计优化策略,如在 Triton 中实现 FlashAttention 需要约 700 行 Python 代码,而在 CUDA 中则需 7000 行 C++ 代码。相比之下,Mirage 通过 SuperOptimization 技术自动搜索潜在的 GPU 内核,并在某些场景下比现有手写内核提升性能 3.5 倍。 Mirage 的工作原理是利用形式化验证技术自动验证生成内核的正确性,并自动搜索与输入的 PyTorch 程序功能等价的优化内核。在多个 LLM 基准测试中,Mirage 生成的内核比专家手动编写或现有编译器生成的替代方案快 1.2 至 2.5 倍。Mirage 通过以下几点提升 GPU 内核开发效率:
更高的生产力:用户只需在 PyTorch 层面描述计算需求,Mirage 会自动生成适配于各种 GPU 架构的高效实现,无需手动编写低级 CUDA/Triton 代码。
更好的性能:Mirage 自动探索优化策略,能够找到比现有手写代码更优的实现,避免次优性能。
更强的正确性:Mirage 通过形式化验证减少了 GPU 内核中的错误风险。
在 Transformer 架构的多个用例中,Mirage 展现了出色的优化能力:
Normalization + Linear 融合:通过代数变换消除中间张量,性能提升 1.5 至 1.7 倍。
LoRA + Linear 融合:将多个矩阵乘法和加法融合为单个内核,提升 1.6 倍性能。
Gated MLP 优化:将矩阵乘法、激活和逐元素乘法融合,减少内核启动和内存访问开销。
QK-Norm Attention 变体优化:融合归一化与注意力计算,性能提升 1.7 至 2.5 倍。
未来,Mirage 的目标是让开发者能够轻松指定数学操作,自动生成高效的 GPU 实现,降低 GPU 编程门槛,同时提升计算效率。项目代码已开源,详情可访问 Mirage 项目地址 。
95后创业AI游戏陪玩,留存付费双高!已适配《黑神话》,团队全员二次元 桌崽AI是一款桌面陪伴宠物,定位于二次元和游戏玩家市场。内测一个月就获得了超过1万的注册用户,日活跃用户超过3000,付费率表现超出预期。次日留存率达到63%,30日留存率为22%,平均每日使用时长高达237分钟,相较于其他大模型Chatbot产品在30天后的用户流失情况,表现十分亮眼。 桌崽AI能够适配《黑神话·悟空》《原神》《绝区零》《鸣潮》等20多款游戏,并实现全程陪伴、实时互动及提供游戏攻略。用户在游戏过程中可以随时与桌崽互动,无需额外查找攻略,桌崽便能实时提供帮助和反馈,甚至还可以陪用户聊天、看动漫等。 桌崽AI的一大特色是用户可以随心所欲自定义桌崽的形象、声线和性格。用户只需上传一张图片和一段文字描述,就能生成3D动态的二次元形象。上线“捏人”功能后,用户留存率提升了1.5倍。 桌崽AI背后的技术支撑来自三款自研大模型:多模态游戏陪玩大模型、二次元视频生成大模型和语音声线定制大模型。多模态游戏陪玩大模型能够基于游戏画面和用户情绪反馈实时生成符合上下文的互动内容;二次元视频生成大模型则专门用于生成符合二次元风格的动态形象;语音声线定制大模型可根据用户提供的音色样本,实现特定角色和人物声音的克隆。 桌崽AI由AI创业公司脸谱心智开发,成立于2023年6月。创始人Adam本硕毕业于帝国理工学院,曾在亚马逊和微软任职,专注于聊天机器人领域的研究。联合创始人Victor则拥有剑桥大学博士学位,并在多模态领域深耕多年。团队整体对二次元文化有高度的认同感,这使得他们在理解用户需求和打磨产品时能更好地与玩家共情。 未来,桌崽AI计划推出移动端版本,并希望将产品扩展至更多形象和物体的桌宠化,比如已故的宠物或者直升机等,实现更广泛的AI桌面陪伴功能。团队希望借此产品让用户不再感到寂寞,并通过不断提升商业化和运营能力,将桌崽AI发展成更受欢迎的智能桌面伙伴。
黄仁勋谈AI与能源技术
该访谈中,英伟达创始人黄仁勋(Jensen Huang)深入探讨了公司的发展历程及其对加速计算的愿景。他回顾了1993年创立英伟达的初衷,旨在解决通用计算机在处理特定问题(如物理仿真、数据处理和图形渲染)时效率低下的局限性。英伟达通过引入专用处理器的理念,实现了百倍的性能提升,同时大幅降低了能耗与成本。这种架构在人工智能和其他领域展现了巨大的扩展性,使其逐渐成为游戏、分子动力学、能源勘探等领域的关键技术。
黄仁勋进一步描述了加速计算在人工智能领域的应用,通过专用硬件设计和并行计算优势,英伟达的GPU能够同时执行数万个线程,极大提升了计算效率。他强调了使用人工智能模型进行天气预测的能效提高,达到传统计算方法的数千倍。英伟达采用“加速计算”策略,不仅降低了训练模型的能耗,同时为工业应用提供了更多的可能性,包括智能电网、碳捕获和新材料开发等领域。
他还提到,未来的人工智能学习将依赖“人工智能模型间的对话”来加速知识的获取,这意味着数据中心的设计可以更加灵活,能够在能源富余地区进行分布式部署。这种“人工智能工厂”的概念体现了新型工业模式,通过数据中心和模型训练的耦合,逐步实现全球能源配置的优化和效率提升。
在谈到英伟达与美国政府的合作时,他指出,主权人工智能(Sovereign AI)将成为国家发展的核心策略,各国必须掌握自己的人工智能基础设施,以确保经济与国家安全。他认为,美国政府应积极参与人工智能实践,并建立国家级的人工智能超级计算平台。
此外,黄仁勋也讨论了人工智能在法律和政策领域的应用前景。他认为,人工智能将渗透到每一个信息密集型行业,如法律文件的分析与合规监控。未来的政策制定和监管框架都将通过人工智能进行优化和提升,从而实现更高效的社会治理和更准确的政策实施。
芯明 周凡:芯明空间计算芯片解锁MR无限潜能 周凡分享了芯明在空间计算领域的技术成果及其应用场景,并深入讨论了MR(混合现实)和XR(扩展现实)行业的技术痛点及芯明的应对策略。他强调,随着芯片、AI和空间计算技术的发展,芯明专注于将底层技术集成到专用芯片中,以提升行业整体性能。 首先,他介绍了当前空间计算的主要技术挑战:多传感器数据处理和低延时的需求。现代MR设备如苹果的Vision Pro集成了多种传感器,包括摄像头、Lidar、磁力计和ToF传感器,这些传感器的数据量庞大且分辨率和刷新率要求极高。传统计算方式依赖主控芯片(如CPU/GPU)进行数据处理,导致高延时、高功耗问题。因此,芯明推出了专门针对MR应用的低时延空间计算芯片,能够实时处理多传感器数据,并融合多个传感器的信息。这款芯片集成了通用3D视觉AI处理引擎,可在端侧实现AI相关算法的本地运行,降低了数据传输延时并减少了系统功耗。 芯明的MR感知计算芯片采用模块化设计,一个单芯片可处理6路摄像头数据,并具备多芯片扩展架构,通过内部协议可以灵活扩展至12路或18路摄像头,满足复杂MR应用的需求。芯明的芯片架构能够以0.5~0.9W的功耗支持720P@120fps和FHD@60fps的3D感知,AI算力范围在3.5~40 TOPS之间,内置的多传感器融合引擎可裁剪和拼接多个摄像头的信息。 此外,周凡还提到了芯明的定制化解决方案,该方案适用于工业头显、机器人和无人机等不同应用场景。基于端到端的全栈设计理念,芯明不仅提供芯片级解决方案,还涵盖模组、驱动库、API接口及上层应用支持,能够灵活应对不同客户的需求。 在实际应用中,芯明的空间计算芯片已经被多家全球领先的MR厂商采用,如某工业头显客户在新一代产品中采用了两颗芯明芯片处理10路摄像头数据,显著降低了BOM成本并提升了整体性能。芯明目前与全球超过130家龙头企业展开合作,包括高端工业MR头显供应商、Top 3笔记本厂商和中国Top 3移动机器人公司等,为其量身定制空间计算解决方案,进一步巩固了其在全球3D感知和空间计算领域的技术领先地位。
Cursor创始团队最新访谈 近日,Lex Fridman 访谈了 Cursor 团队的四位创始成员——Michael Truell、Sualeh Asif、Arvid Lunnemark 和 Aman Sanger,探讨了 Cursor 的技术理念与未来方向。 Cursor 成立于 OpenAI 提出缩放损失(scaling loss)概念之后,团队注意到随着计算量和数据的增加,模型性能显著提升,认为无需博士学位即可在 AI 领域做出贡献。2022 年底,团队在获得 GPT-IV 使用权后,决定将理论研究成果转化为实际产品,专注于提高程序员工作效率。 Cursor 以智能编辑器为核心,提供自动代码补全、diff 接口、错误检测等功能。diff 功能可显示代码变更,并通过多种 diff 方案优化用户体验,使用户能更直观地查看和应用改动。这些功能通过对微调模型的多次训练迭代来提升表现,并且引入了“投机编辑”等机制来提高编辑速度和降低延迟。 Cursor 采用多个定制化模型协同工作。复杂代码的处理通常通过多个模型合作完成——首先粗略描述代码修改,然后由另一个模型具体实现。此方法可降低大型模型的推理成本和延迟。此外,团队讨论了 OpenAI o1 模型的潜力,并正在探索如何在 Cursor 中更好地集成该模型,以应对复杂编程任务和增强推理能力。 Cursor 团队认为,未来 AI 编程环境将进一步发展成为全新的编程范式。他们希望通过更多的模型创新与深度集成来提升代码处理能力,并计划在未来 3-4 年内将 Cursor 打造成最具影响力的编程工具之一。
AI博士如何做出有影响力的研究? 项目优先于论文:研究生阶段应该避免只注重论文数量。应将精力放在具有长期价值的项目上,围绕开源模型、系统或基准构建论文,使研究成果更具连贯性和长期影响力。 选择前沿、有潜力的问题:关注将在2-3年内变得热门但尚未主流的研究方向。要选择那些能够影响多个下游问题的问题,挖掘其潜力。并且,在解决方案上要有很大的提升空间,比如性能提升 20 倍甚至 100 倍,而不是仅限于小幅度改进。 提前思考两步并快速迭代:当发现新问题时,不要急于选择显而易见的路径,而是要预测未来主流方案可能遇到的局限性,并着手解决这些问题。快速迭代能够加快问题的验证和解决过程。 开放并推广自己的研究:发布论文仅仅是个开始。通过开源工具、框架和基准测试让更多人了解自己的工作,建立研究的影响力,并在不同环境中多次传达核心思想,吸引社区关注和参与。 发布开源研究的技巧:好的开源研究需要满足“有用”和“通俗易懂”的标准。要让研究易于他人理解和使用,降低用户上手难度,并逐步形成活跃的社区,使项目可持续发展。 将项目投入新研究中:开源项目和论文研究可以相辅相成,开源项目能够帮助发现新问题,吸引优秀合作者,并成为进一步学术研究的基础。通过与社区互动和反馈,新研究可以快速获得关注。
Y Combinator 支持的 PearAI 被指抄袭,遭受社区广泛批评 近日,由 Y Combinator 支持的 AI 初创公司 PearAI 因涉嫌抄袭开源项目而引发广泛争议。PearAI 的创始人 Duke Pan 在社交媒体上公开表示,该公司推出的 AI 代码编辑器是基于开源项目 VSCode 和 AI 编辑器 Continue 的克隆版本。PearAI 最初试图为该项目添加一个名为“Pear 企业许可证”的自定义闭源许可,然而,这一举动违反了开源社区的规范,引发了严重的负面反馈。
在强烈批评声中,PearAI 迅速撤销了闭源许可,将项目改为原始的 Apache 开源许可证,并在社交平台发布了公开道歉声明。Pan 表示,PearAI 的错误在于未能明确告知用户其项目源自其他开源工作,并且没有在项目中做出足够的创新,从而引起了误解。
此次事件在社交媒体上引发了大量讨论,甚至在 Twitter 上出现了社区备注,提醒用户 PearAI 是“直接复制了 Continue.dev 项目”。尽管 PearAI 在其声明中补充了项目与 Continue.dev 的区别,但大多数评论者仍对其行为表示不满,认为 PearAI 只是简单替换了项目名称而非进行真正的创新。
Y Combinator 的 CEO Garry Tan 也卷入了这场风波。他在推文中为 PearAI 辩护,认为项目遵循开源许可的原则,因此不应受到如此严厉的批评。然而,许多人指出,PearAI 是在争议后才更改许可证的,这种行为让其难以获得外界信任。此外,有人质疑 Y Combinator 的审核机制为何会接受这样一个没有技术创新的项目,认为这表明 YC 对于孵化项目的遴选标准过于宽松,甚至可能导致其品牌价值的下滑。
这起事件揭示了开源社区与商业化初创公司之间的矛盾,同时也引发了对 Y Combinator 在孵化项目时是否应更严格遵循开源和知识产权规范的广泛讨论。此次事件不仅影响了 PearAI 的声誉,也让 YC 面临外界对其项目孵化模式的质疑
https://techcrunch.com/2024/09/30/y-combinator-is-being-criticized-after-it-backed-an-ai-startup-that-admits-it-basically-cloned-another-ai-startup/
OpenAI视频生成器Sora项目联合负责人Tim Brooks离职加入谷歌 OpenAI视频生成器Sora的联合负责人之一Tim Brooks宣布离职,将加入谷歌旗下的DeepMind,并继续在视频生成技术和“世界模拟器”领域工作。Brooks表示,他在OpenAI的两年工作经历非常出色,但他对加入DeepMind团队并推动“世界模拟器”愿景的实现感到兴奋。 据悉,Brooks是Sora项目的首批研究人员之一,自2023年1月起便开始推动该项目的研究方向和大型模型训练。然而,Sora项目目前进展并不顺利,其技术开发遭遇了挑战。据《The Information》报道,Sora项目初期系统在生成1分钟视频时需要超过10分钟的处理时间。OpenAI正在开发改进版的Sora,目标是缩短生成时间并提升整体性能。 Brooks的离职发生在OpenAI内部频繁人事变动之际。9月底,OpenAI首席技术官Mira Murati、首席研究官Bob McGrew和研究副总裁Barret Zoph相继宣布离职。此前,知名研究科学家Andrej Karpathy、联合创始人兼前首席科学家Ilya Sutskever以及前安全负责人Jan Leike均已离开OpenAI。今年8月,另一位联合创始人John Schulman也表示将离职,而公司总裁Greg Brockman则目前处于休假状态。 与此同时,谷歌在视频生成领域的竞争力不断提升。今年春季,谷歌推出了视频生成模型Veo,并计划将其集成到YouTube Shorts中,供创作者生成背景和6秒短片。相比之下,OpenAI在与电影制作公司及好莱坞工作室建立长期合作方面尚未取得重大进展,而竞争对手如Runway和Stability则已分别与狮门影业和知名导演詹姆斯·卡梅隆达成了合作。 Brooks的加入将进一步增强DeepMind在视频生成技术领域的研发实力,同时也表明了OpenAI在该领域面临的激烈竞争和内部动荡。 https://techcrunch.com/2024/10/03/a-co-lead-on-sora-openais-video-generator-has-left-for-google/ Anthropic聘请OpenAI联合创始人Durk Kingma,进一步强化人才布局 Anthropic宣布聘请OpenAI联合创始人Durk Kingma加入公司团队。Kingma在X平台(前Twitter)上表示,他将主要以远程工作形式从荷兰办公,但尚未透露其将加入或领导Anthropic的具体团队。他提到:“Anthropic在AI开发上的理念与我的个人信念高度契合,我期待能够为Anthropic在负责任地开发强大AI系统的使命做出贡献。” Kingma拥有阿姆斯特丹大学的机器学习博士学位,此前曾是谷歌的博士研究员。作为OpenAI的创始团队成员之一,Kingma在OpenAI担任研究科学家,领导算法团队,专注于生成式AI模型的开发(例如图像生成器DALL-E 3和大语言模型ChatGPT)。2018年,他离开OpenAI成为AI初创公司的天使投资人和顾问,随后重新加入谷歌并进入Google Brain,该实验室后来与DeepMind合并,成为谷歌的顶级AI研发部门之一。 此次聘请Kingma是Anthropic在人才布局上的又一大手笔。今年5月,Anthropic已招募了OpenAI前安全负责人Jan Leike,8月又引入了另一位OpenAI联合创始人John Schulman。此外,Instagram和Artifact的联合创始人Mike Krieger也在5月被任命为Anthropic的首席产品负责人。 Anthropic的CEO Dario Amodei曾是OpenAI的研究副总裁,但因对OpenAI日益商业化发展路线的分歧而离开,并带领一批前OpenAI员工创立了Anthropic,包括前OpenAI政策负责人Jack Clark。Anthropic一直试图将自己定位为比OpenAI更注重安全的AI开发公司,此次招聘Kingma进一步强化了其在技术和人才储备上的竞争力。 https://techcrunch.com/2024/10/01/anthropic-hires-openai-co-founder-durk-kingma/ 推特 OpenAI筹集66亿美元新融资,估值达到1570亿美元:旨在加速推动我们使命的实现 我们正在为确保通用人工智能造福全人类的使命取得进展。每周,全球有超过2.5亿人使用ChatGPT来提升他们的工作、创意和学习。在各个行业,企业正在提高生产力和运营效率,开发者们也利用我们的平台开发新一代应用程序。而这仅仅是个开始。 我们已筹集到66亿美元的新融资,估值达到1570亿美元,旨在加速推动我们使命的实现。这笔新资金将使我们加倍致力于前沿人工智能研究的领导地位,增加计算能力,并继续构建帮助人们解决难题的工具。 我们的目标是让先进的智能技术成为人人可及的资源。我们感谢投资者对我们的信任,并期待与合作伙伴、开发者以及更广泛的社区携手,打造一个以人工智能为驱动力的生态系统和未来,造福所有人。通过与包括美国及其盟友政府在内的重要伙伴合作,我们可以释放这项技术的全部潜力。
https://openai.com/index/scale-the-benefits-of-ai/ Liquid AI推出液态基础模型:基于动力系统理论、信号处理和数值线性代数构建的神经网络 今天,我们向世界推出液态基础模型(Liquid Foundation Models,LFMs),并发布了第一系列语言LFM模型:1B、3B和40B模型。 LFM-1B在1B参数级别的公共基准测试中表现出色,成为该规模内的最新最先进模型。这是非GPT架构首次显著超越基于Transformer的模型。 LFM-3B在其规模上展现了惊人的性能。它不仅在3B参数的Transformer、混合模型和RNN模型中位列第一,还超越了上一代的7B和13B模型。在多个基准测试中,它的表现与Phi-3.5-mini相当,但模型大小减少了18.4%。LFM-3B是移动端和其他边缘设备上的文本应用的理想选择。 LFM-40B在模型大小和输出质量之间提供了新的平衡。它在使用时激活12B参数,性能堪比更大规模的模型,同时其专家混合(MoE)架构使其具备更高的吞吐量,并可部署在更具性价比的硬件上。 LFMs是基于动力系统理论、信号处理和数值线性代数构建的神经网络。 了解更多我们的研究内容:http://liquid.ai/blog/liquid-neural-networks-research
https://x.com/LiquidAI_/status/1840768716784697688 ⌘ + ⇧ + P :Perplexity AI预告Perplexity for mac
https://x.com/perplexity_ai/status/1840890047689867449
PIKA1.5上线:更逼真的动作、更大的屏幕截图,以及打破物理法则的惊人“Pika效果” PIKA1.5上线:更逼真的动作、更大的屏幕截图,以及打破物理法则的惊人“Pika效果” https://x.com/a
https://x.com/pika_labs/status/1841143349576941863 Karpathy分享:使用AI两个小时策划10集新播客《谜团历史》,探索探索生成式AI解锁的可能性空间和杠杆效应 在过去的大约两个小时里,我策划了一个包含10集的新播客,名为《谜团历史》。你可以在Spotify上找到它: https://open.spotify.com/show/3K4LRyMCP44kBbiOziwJjb?si=432a337c28f14d97
我使用ChatGPT、Claude和Google研究了有趣的主题
我将NotebookLM链接到每个主题的维基百科页面,并生成了播客音频
我还使用NotebookLM编写了播客/每集的描述
我使用Ideogram为每一集以及整个播客创作了数字艺术
我这么做是为了探索生成式AI解锁的可能性空间,以及AI提供的巨大杠杆效应。作为一个人,在两个小时内能够策划(不是创作,而是策划)一个播客,我觉得这是相当不可思议的。我也完全理解并承认这里的潜在批评,比如AI生成的内容正在充斥互联网。不过,我想——下次你散步或开车的时候,可以听听这个播客,看看你有什么想法。
https://x.com/karpathy/status/1841594123381571863 产品 Meta Movie Gen Meta Movie Gen 是由 Meta 开发的先进媒体生成工具,利用 30 亿参数模型生成高质量图像和视频,并通过 13 亿参数模型创建同步音频。它支持精确的视频编辑和个性化视频生成,为创作者提供全新的创作可能性。 Text input summary: A red-faced monkey with white fur is bathing in a natural hot spring. The monkey is playing in the water with a miniature sail ship in front of it, made of wood with a white sail and a small rudder. The hot spring is surrounded by lush greenery, with rocks and trees.
https://ai.meta.com/research/movie-gen/ video-sdk-3-0 Video SDK 是一个强大的开发平台,允许开发者快速集成实时音频和视频功能,适用于在线教育、远程医疗和企业视频会议等场景。它可以提供简单易用的 API 和多平台支持,简化音视频集成过程,从而提升用户体验。
https://www.videosdk.live/character-sdk Sembian Semblian 2.0 是一款 AI 驱动的工作自动化工具,提升用户的工作效率。它能够智能记录会议内容,生成个性化的文档和后续步骤,并支持多种语言,帮助用户更好地管理和分析会议信息。通过自动化,Semblian 2.0 助力用户节省时间,专注于更重要的任务。
https://www.sembly.ai/semblian Hedy Hedy AI 是一款实时 AI 会议助手,帮助用户在会议和讲座中获得即时的智能建议和洞察,增强自信心和参与感。它支持多种语言,能够分析对话并提供上下文相关的建议,尤其适合非母语人士和希望提升沟通能力的专业人士和学生。
CostGPT.ai CostGPT 是一款利用人工智能帮助用户估算软件项目成本和时间的工具,提供详细的功能分解、用户故事、网站地图和里程碑规划,提高项目管理的准确性和效率。
JOGG AI
JoggAI 是一款基于人工智能的视频广告生成工具,能够快速将网址或产品视觉内容转化为引人注目的视频广告,从而提升销售和流量。它提供丰富的模板、AI 头像和剪辑理解功能,方便营销人员和内容创作者轻松制作高质量的营销视频。
投融资 OpenAI完成66亿美元融资,估值达1570亿美元,创下史上最大风险投资轮记录 OpenAI近期宣布完成66亿美元融资,本轮融资由Thrive Capital领投,其他参与方包括微软、英伟达、软银、Khosla Ventures、Altimeter Capital、Fidelity和MGX等。此次融资使得OpenAI的估值达到1570亿美元,创下风险投资历史上最大单轮融资记录。至此,OpenAI的总融资金额达到179亿美元。 据《纽约时报》报道,Thrive Capital投资了约13亿美元,并拥有到2025年追加投资10亿美元的独家选择权。微软则投资了不到10亿美元,而英伟达和软银分别出资1亿美元和5亿美元。本轮融资将用于进一步加强OpenAI在前沿AI研究领域的领导地位,提升计算能力,并继续开发帮助人们解决复杂问题的工具。 本轮融资还附带了特定的条款,要求投资者避免支持OpenAI的竞争对手,如Anthropic和xAI等。另据彭博社报道,若OpenAI未能在两年内完成从非营利性组织向营利性结构的转变,投资者有权收回投资款项。此次融资标志着OpenAI在AI领域的强劲增长,同时也凸显了其未来面临的巨大资金需求和市场竞争压力。 尽管OpenAI的ChatGPT用户量已超2.5亿,其中1000万为付费用户,公司2023年年化营收已超过34亿美元,但为了应对未来的竞争压力,OpenAI可能会将ChatGPT Plus的月费从目前的20美元提升至44美元,并计划调整公司结构以吸引更多投资。此次融资的资金还将用于AI芯片研发、数据中心建设及与数据提供商的许可协议签署,帮助OpenAI在未来保持竞争优势。
https://techcrunch.com/2024/10/02/openai-raises-6-6b-and-is-now-valued-at-157b/ Voyage AI完成2000万美元A轮融资,致力于构建RAG工具以减少AI“幻觉”现象 Voyage AI是一家专注于开发检索增强生成(RAG)工具的初创公司,旨在通过定制AI模型和嵌入技术来减少AI“幻觉”现象(即错误生成信息)。公司近期完成了2000万美元的A轮融资,此轮融资由CRV领投,Wing VC、Conviction、Snowflake和Databricks参与投资。此次融资使Voyage AI的总融资金额达到2800万美元。 Voyage AI由斯坦福大学教授Tengyu Ma于2023年创立,旨在提升企业级AI系统中的搜索和检索效率及精度。公司主要客户包括Harvey、Vanta、Replit和SK电信等,客户总数已超过250家。Voyage专门为不同领域(如编码、金融、法律和多语言应用)以及企业的特定数据开发RAG系统,并提供定制模型服务。 Voyage AI的解决方案基于将文本、文档、PDF等数据转换为数值表示形式(即向量嵌入),以捕捉数据之间的含义和关系。特别是公司采用了一种名为“上下文嵌入”的技术,不仅捕捉数据的语义意义,还能反映数据出现的上下文。例如,对于句子“我坐在河岸上”和“我在银行存了钱”中的“bank”一词,Voyage的嵌入模型将生成不同的向量,反映出两种不同的含义。 此次融资将帮助Voyage进一步推出新嵌入模型,并计划将员工数量翻倍。Ma表示,Voyage的嵌入模型在检索精度方面表现出色,能显著提升RAG系统的整体响应质量。目前,Voyage的模型可部署在本地、私有云或公有云环境中,并根据客户需求进行细化和定制。 Voyage AI的成功得到了业界认可,包括OpenAI的主要竞争对手Anthropic在内的支持。Anthropic在其支持文档中将Voyage的模型描述为“最先进”的解决方案之一。这表明Voyage AI在减少AI“幻觉”现象和提升检索准确性方面,具有独特的竞争优势。 公司官网:https://www.voyageai.com/
https://techcrunch.com/2024/10/03/voyage-ai-is-building-rag-tools-to-make-ai-hallucinate-less/ Submer完成5550万美元C轮融资,推动数据中心液冷技术发展 随着数据中心需求的增加和AI工作负载的激增,传统的冷却技术已难以应对日益增长的散热需求。巴塞罗那初创公司Submer推出了创新的液冷技术,通过将服务器机架浸没在专有的可生物降解、不导电的冷却液中,来更高效地管理数据中心的散热问题。公司最新完成了5550万美元的C轮融资,估值达到5亿美元。 此次融资由M&G领投,先前的投资者Planet First Partners和Norrsken VC,以及新投资者Mundi Ventures均参与其中。Submer计划利用这笔资金扩大业务规模,并推动其液冷解决方案在更多数据中心的应用。Submer现已拥有包括全球知名“超大规模”数据中心运营商、电信公司(如Telefonica)、大型企业(如ExxonMobil)、欧盟委员会以及主要研究中心在内的客户群体。 Submer的冷却液由一组退役的工业工程师和材料科学家团队开发,冷却液具有水的粘度,并且是不可燃、可生物降解的合成混合物。此外,Submer还提供一系列沉浸式冷却液体和容器,并在某些型号中集成了水冷系统,可以将冷却过程中产生的热量重新利用,例如用于建筑物供暖。 Submer的液冷技术获得了包括戴尔、Supermicro、英特尔等在内的主要服务器OEM厂商的支持,并与他们达成了组件兼容性的合作协议。凭借延长服务器使用寿命、无尘无噪音等优势,Submer的解决方案在市场上脱颖而出,并正在快速扩展其生态系统和客户群体。 Submer的成功也引发了同行业的关注。英国的Icetope和美国得克萨斯州的两家初创公司(LiquidStack和Green Revolution Cooling)也在开发类似的液冷技术,LiquidStack甚至获得了老虎全球基金的投资支持。此次融资将帮助Submer进一步巩固其在数据中心液冷市场的领先地位,并推动其在全球范围内的扩张。
https://techcrunch.com/2024/10/02/as-data-center-usage-heats-up-submer-raises-55-5m-to-cool-things-down/
— END —
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/10/21450.html