我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢 迎 大 家 一 起 交 流 !
资讯 COLM奖项公布:被ICLR拒稿的Mamba入选杰出论文
2023年,为了更好地探索语言模型领域,一批知名青年学者发起了COLM(Conference on Language Modeling)会议,旨在创建一个专注语言模型研究、改进和交流的学术平台。今年,COLM公布了2024年杰出论文奖,共有4篇论文获奖,其中引起广泛关注的包括Mamba模型。
Mamba模型的研究解决了Transformer在长序列处理中的效率问题。Mamba通过将状态空间模型(SSM)参数化为输入函数,根据当前token选择性传播或遗忘信息,实现了线性时间序列建模。Mamba在语言、音频、基因组学等多种模态中达到SOTA水平,并在语言建模中表现优于同规模Transformer模型。该模型的硬件感知算法将SSM与Transformer的MLP块融合,形成同质架构,能够支持百万token长度的推理,提升5倍推理吞吐量,并能与两倍规模的Transformer模型媲美。
另一篇获奖论文“Dated Data: Tracing Knowledge Cutoffs in Large Language Models“研究了LLM的“有效截止日期”问题,提出了一种无需访问预训练数据的方法来估计不同数据集的实际有效时间点,并揭示了数据版本错位与重复数据处理导致的知识偏移问题。
第三篇论文“AI-generated text boundary detection with RoFT”提出了在文本中检测人类与AI生成部分的边界。通过测试不同边界检测算法,作者发现基于困惑度的检测方法在处理跨领域数据时更为鲁棒,指出了现有检测方法在处理特定文本特征时的局限性。
最后一篇获奖论文“Auxiliary task demands mask the capabilities of smaller language models”探讨了任务需求对小型语言模型能力评估的影响。实验表明,任务复杂度越高,小型模型表现越差,这种“需求差距”使得模型性能不能直接代表智能水平。
COLM致力于促进语言模型技术的发展,并推动学术界与产业界的深度交流。Mamba模型及其他获奖论文展示了语言模型领域的前沿探索,为未来的研究指明了方向。
在 Google Cloud TPU 上微调 LLaMa3.1,成本降低 30%,并实现无缝扩展! 随着AI模型参数量的增长,对算力需求也急剧上升。例如,Llama-3.1的405B版本需要900GB以上的内存,对算力构成巨大挑战。为了解决这一问题,Felafax公司致力于简化AI训练集群的搭建,采用了性价比更高的AMD GPU,并通过JAX对LLaMA 3.1 405B模型进行微调。 JAX是一个强大的机器学习库,它结合了类似NumPy的API、自动微分功能和Google的XLA编译器,在非英伟达硬件上表现优异。使用JAX可以在多种硬件设备上高效运行,而无需修改代码。这种硬件无关的设计使JAX成为非英伟达硬件上的最佳选择。相比之下,PyTorch在迁移至AMD GPU或TPU时,需要更多适配工作。Felafax利用JAX在8张AMD MI300X GPU上成功微调了LLaMA 3.1 405B模型。每张MI300X拥有192GB的HBM3内存,使得LLaMA 405B在AMD节点上能够高效运行。 模型微调采用了LoRA(Low-Rank Adaptation)方法,将所有权重和LoRA参数设为bfloat16格式。LoRA通过将权重更新分解为低秩矩阵,减少了可训练参数的数量,有效降低了内存开销。LoRA的rank值设为8,alpha值设为16,最终模型占用总显存的77%,即约1200GB。在此设置下,使用JAX急切模式时模型训练速度为35 tokens/秒,显存利用率达到70%。虽然由于硬件和显存限制无法使用JIT编译,但整体扩展性在8张GPU上表现接近线性。 模型分片策略是Felafax优化的关键。使用JAX的设备网格(device mesh)功能,可将模型的参数和计算任务分配到不同GPU上。在此应用中,设备网格形状为(1, 8, 1),表示数据并行(dp)、全分片数据并行(fsdp)和模型并行(mp)。模型的LM head(lm_head/kernel)张量在第一个轴上被分片到8个GPU,而没有设置分片规范的参数(如层归一化)则会被复制到所有设备上。 训练过程中,Felafax还对LoRA参数进行了分片策略优化。LoRA的A矩阵参数沿着fsdp轴分片到8个设备,而B矩阵则沿着mp轴分片,减少了通信开销,增强了训练并行性。最终,该策略在训练LLaMA 405B模型时,仅计算LoRA参数的梯度,保持主模型权重不变,从而降低了内存使用并加快了训练速度。 https://github.com/felafax/felafax
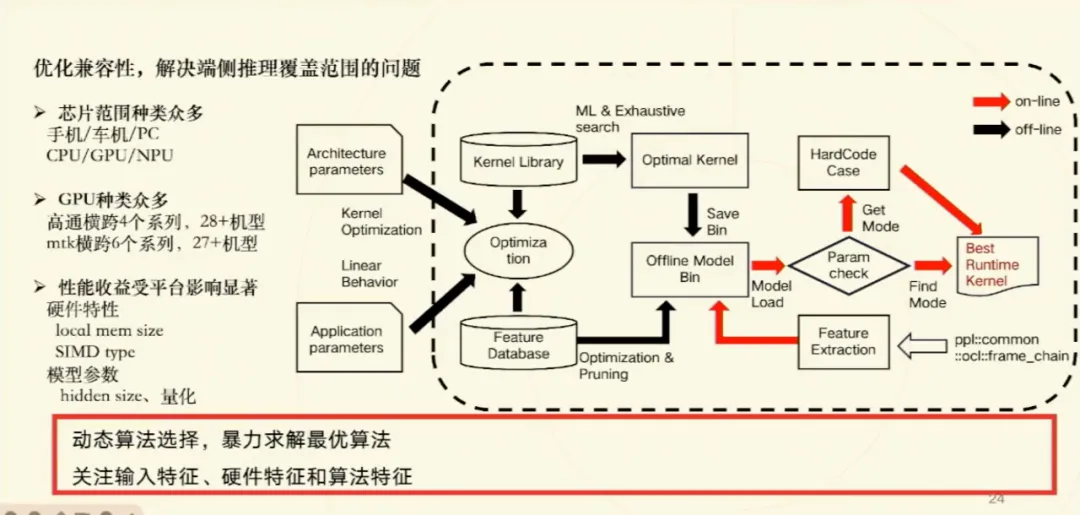
商汤 SensePPL 深度调优实践 端侧大模型在2024年迎来了广泛关注,手机、汽车、PC等领域的AI应用逐渐成熟。各大厂商如苹果、vivo、OPPO、小米纷纷推出端侧AI系统,理想汽车和小米汽车也推出了自研语音大模型,AIPC逐步成为热点。端侧推理的快速发展得益于大模型的小型化及硬件算力的迭代,如LLAMA3、Phi-3、Mini CPM模型与高通、联发科的AI芯片,为端侧推理提供了坚实的技术基础。 端侧推理流程可分为prefill和decoding阶段。prefill阶段以计算密集型操作为主,decoding阶段则是访存密集型操作。评估推理系统性能的常用指标包括吞吐量、每秒请求数、首次延迟和解码延迟。云侧推理侧重提升吞吐量和并发处理能力,而端侧推理则更关注首次延迟和整体响应时间的优化。端侧推理面临内存占用、延迟、模型效果和跨平台兼容性四大挑战。 优化端侧推理的显存占用是关键,采用W4A16量化方案,并结合AWQ量化技术可有效降低权重尺寸,提升量化精度。KV Cache采用INT8量化方案,并对算子进行优化融合,通过减少量化和反量化过程中的开销实现更高效的MHA计算。prefill阶段主要优化矩阵乘法,decoding阶段优化矩阵向量乘法。在GPU资源受限情况下,结合GPU内存特性使用n连续、k连续和K8N4等算法策略,选择适合不同数据规模的算法方案。 端侧推理在跨平台兼容性上也面临挑战。芯片种类繁多,包括手机、车机和PC的CPU、GPU、NPU等异构架构。为此,端侧推理框架需针对不同硬件架构进行适配,并根据硬件特性和模型参数选择合适算法及分块策略。实际应用中,通过离线处理和Kernel编译进一步提升系统兼容性。 Serving Pipeline优化在端侧推理中扮演重要角色,从接收用户输入到分词、推理、采样,再到输出的整个流程,通过Serving层进行统一管理,并实现KV Cache管理与多轮对话优化。多轮对话优化可以在KV Cache中拼接历史prompt与回答,减少整体推理过程中的计算开销。 在应用场景中,SensePPL已在高通和MTK的旗舰机型中得到验证。prefill和decoding性能分别提升30%,内存占用降低50%。在WAIC大会上,展示的多模态模型部署方案在LLM性能上比开源方案提升了三倍。未来,SensePPL将继续拓展至AIPC和机器人领域,推动AI技术更广泛地普及和落地。
https://mp.weixin.qq.com/s/KhWLmWugFmTswUOj8JkIIg Ceph:20 年前沿边缘存储的发展历程
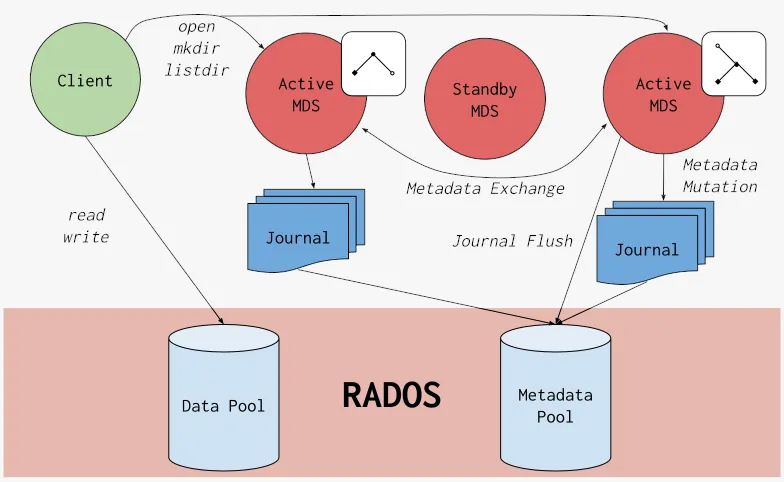
在2023年OpenInfra Summit Asia大会上,Ceph的使用率已达到82%,成为全球范围内广泛应用的数据存储解决方案。Ceph最初是加州大学圣克鲁斯分校一个学生项目,由Sage Weil作为博士研究的一部分启动,逐渐发展成为业界领先的分布式存储系统。Ceph具备独特的技术特性,如分布式对象存储、数据与元数据解耦、动态分布式元数据管理和CRUSH算法,使其能够在多个节点上横向扩展,提供一致可靠的存储服务。 Ceph采用RADOS作为基础架构,引入CRUSH算法来确定性地放置数据,消除集中式分配表的需求。它通过动态子树分区(DSP)自适应地分配元数据管理,实现元数据和数据的分离,提升了系统可扩展性。Ceph的设计理念将更多智能推向边缘设备,与当时的主流存储解决方案如Lustre和GFS区别开来,强调自主管理和单点故障避免。 在2007至2011年,DreamHost为Ceph的发展提供了关键支持,核心组件逐步稳定并引入了大量新特性。随着Inktank的成立,Ceph的企业级支持进一步增强,并最终被红帽收购,推动Ceph成为企业级生产系统。2011年,Ceph被纳入Linux内核2.6.34主线版本,性能大幅提升。Ceph的重大突破之一是引入BlueStore,它通过直接管理SSD和HDD设备,避免传统文件系统的性能瓶颈。BlueStore采用嵌入式RocksDB键值数据库存储元数据映射,提升了数据存取效率和可靠性。 Ceph在存储数据的可靠性和恢复能力上表现出色。不同于传统的“磁盘复制”或“对象复制”方法,Ceph采用对象分组机制,即使发生故障,也能在数分钟内快速重建数据,显著缩短了恢复时间。Ceph的创新理念和技术特性使其在企业和云基础设施中得到广泛应用,并在人工智能和机器学习领域也具备潜力。2018年,Ceph基金会成立,进一步推动其生态发展。未来,Ceph将在数据存储领域继续发挥重要作用,为各类应用场景提供高效可靠的存储解决方案。
https://mp.weixin.qq.com/s/58WsOP9hZGxE6jw2CKK7yg 推特 Sully分享使用OpenAI o1的工作流:如何正确使用o1来看到真正的魔力 所以我制作了一段视频,展示了我经常使用的工作流程。
不要像用 GPT-4 那样(来回对话)使用它,那样是浪费时间。
先构建上下文(语音模式),创建一个大文档,然后用另一个模型进行优化。
最后把所有内容交给 O1,这样才能看到真正的魔力。
https://x.com/SullyOmarr/status/1843425434501091718 Supervision-0.24.0:按类别统计线的穿越次数 你终于可以按类别统计线的穿越次数了。很多人一直在要求这个功能,现在我们终于实现了! 我用 Supervision 花了不到 30 分钟就做了这个演示! 链接: https://github.com/roboflow/supervision
https://x.com/skalskip92/status/1843321679210279043 LeLaN:从野外视频中学习语言条件导航策略 我们的新论文关于使用 YouTube 视频进行语言条件导航学习已经发布!通过利用预训练模型和从网络中获取的视频数据,我们可以让机器人更好地理解语言指令。 很高兴分享我们最近的研究 LeLaN,它用于从野外视频中学习语言条件导航策略,由加州大学伯克利分校和丰田北美共同研究。我们将在 CoRL 2024 上展示 LeLaN。 https://x.com/svlevine/status/1843181197163483495 Imrat整理Lex Fridman 播客与 Cursor 团队中10个片段 我刚看了 Lex Fridman 播客与 Cursor 团队的第一小时内容。 我整理了其中我最喜欢的 10 个片段,并剪辑了播客的部分内容,放在下面。 总结一下:这是关于 AI 编程最深入的讨论之一。不仅仅是 Cursor 粉丝,任何对 AI 编程感兴趣的人都应该看。 无论你是使用 Claude、O1、Aider、GPT Engineer、Copypasta、Amazon CodeWhisperer 还是 Replit Agent,这里都有你能学到的东西。
RunwayML分享:为生成模型制定的安全性、公平性和诚信度的保障措施 随着我们不断构建能够提升人类创造力、支持艺术家、增强媒体和娱乐行业的通用世界模型,我们也更加深刻地感受到构建对世界产生正面影响的工具的责任感。 今天,我们分享了我们为生成模型制定的安全性、公平性和诚信度的保障措施,旨在防止我们工具的滥用。 链接: https://runwayml.com/research/foundations-for-safe-generative-media
https://x.com/runwayml/status/1843285078002061611 产品 OpenBB Terminal OpenBB 是一个基于 AI 的金融终端,可以通过无缝的数据集成和 AI 助手提升投资研究效率。它提供强大的数据分析、定制化功能和社区支持,适合各类用户使用。
https://openbb.co/
opencord.AI Opencord AI 是一个社交媒体 AI 助手,提供 24/7 的目标客户互动服务,帮助用户找到潜在客户、提升内容创作效果,并个性化社交媒体交流。它通过分析社交平台上的信息,自动化处理和回复,可以节省时间并提高在线存在感。
https://www.opencord.ai/
投融资 VESSL AI 获得1200万美元融资,致力于降低高达80%的GPU成本 韩国MLOps平台VESSL AI近日完成了1200万美元的A轮融资,旨在利用混合基础设施和多云策略降低GPU成本,为企业提供更高效的机器学习模型开发和部署平台。本轮融资的投资方包括A Ventures、Ubiquoss Investment、未来资产证券(Mirae Asset Securities)、Sirius Investment、SJ Investment Partners、Wooshin Venture Investment和新韩风险投资(Shinhan Venture Investment)。截至目前,VESSL AI的总融资金额已达1680万美元。
VESSL AI创立于2020年,由Jaeman Kuss An(首席执行官)、Jihwan Jay Chun(首席技术官)、Intae Ryoo(首席产品官)和Yongseon Sean Lee(技术负责人)共同创办,创始团队成员曾供职于Google、PUBG和多家AI初创公司。该公司主要通过混合基础设施模式和多云策略,最大限度地降低GPU开销,并优化大规模语言模型(LLM)和垂直AI代理的开发流程,旨在满足企业级客户的定制化需求。
目前,VESSL AI已拥有50家企业客户,包括现代汽车、LIG Nex1、TMAP Mobility、Yanolja、Upstage、ScatterLab和Wrtn.ai等,并与Oracle和Google Cloud在美国市场建立了战略合作关系。其平台的核心功能包括自动化模型训练的VESSL Run、实时部署的VESSL Serve、集成训练和数据预处理的VESSL Pipelines以及优化GPU资源使用的VESSL Cluster。
该轮融资将用于加速平台的基础设施开发,进一步提升其在机器学习模型开发中的成本效益和资源管理能力。
公司官网:https://vessl.ai/
https://techcrunch.com/2024/10/07/vessl-ai-secures-12m-for-its-mlops-platform/ Kobold Metals利用AI技术寻找关键矿产,完成4.91亿美元融资 AI驱动的矿产勘探初创公司Kobold Metals近日在其最新一轮融资中获得4.91亿美元(目标为5.27亿美元),这一轮融资后,Kobold的估值有望达到20亿美元。该公司专注于利用人工智能技术寻找铜、锂、镍和钴等关键矿产,以推动能源转型,并且在今年早些时候发现了全球最大高品位铜矿床之一,该矿床每年可能生产数十万吨铜。 Kobold Metals成立之初主要专注于矿产资源的发现,通过应用AI技术分析大量数据,提升矿产发现的成功率,而传统矿产勘探的成功率仅为千分之三左右。此次融资将帮助该公司进一步开发其在赞比亚发现的巨型铜矿资源,同时推进其他60多个矿产勘探项目。Kobold预计将自主开发赞比亚的铜矿项目,这一开发可能需要23亿美元的资金投入。 Kobold Metals此前的投资者包括比尔·盖茨、杰夫·贝佐斯、马云、Andreessen Horowitz和Breakthrough Energy Ventures等知名人士和风投公司。此前的一轮1.95亿美元融资曾使公司估值达到10亿美元。目前,该公司正致力于转型为既能勘探又能开发资源的综合性矿产公司,以加速矿产资源的开发与商业化。 公司官网:https://www.koboldmetals.com/
https://techcrunch.com/2024/10/07/ai-powered-critical-mineral-startup-kobold-metals-has-raised-491m-filings-reveal/
— END —
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/10/21452.html