我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


信号
Towards World Simulator: Crafting Physical Commonsense-Based Benchmark for Video Generation
像 Sora 这样的文本转视频 (T2V) 模型在可视化复杂提示方面取得了重大进展,这越来越被视为构建通用世界模拟器的一条有希望的道路。认知心理学家认为,实现这一目标的基础是理解直觉物理的能力。然而,这些模型准确表示直觉物理的能力在很大程度上仍未得到探索。为了弥补这一差距,我们引入了 PhyGenBench,这是一个全面的 textbf{Phy}sics textbf{Gen}eration textbf{Ben} 基准,旨在评估 T2V 生成中的物理常识正确性。PhyGenBench 包含 160 个精心设计的提示,涵盖 27 个不同的物理定律,涵盖四个基本领域,可以全面评估模型对物理常识的理解。除了 PhyGenBench,我们还提出了一个名为 PhyGenEval 的新型评估框架。该框架采用分层评估结构,利用适当的高级视觉语言模型和大型语言模型来评估物理常识。通过 PhyGenBench 和 PhyGenEval,我们可以对 T2V 模型对物理常识的理解进行大规模自动评估,这与人类反馈密切相关。我们的评估结果和深入分析表明,当前的模型难以生成符合物理常识的视频。此外,简单地扩大模型规模或采用快速工程技术不足以完全解决 PhyGenBench 提出的挑战(例如动态场景)。我们希望这项研究能够激励社区优先考虑在这些模型中学习物理常识,而不仅仅是娱乐应用。
https://arxiv.org/abs/2410.05363
Temporal Reasoning Transfer from Text to Video
视频大型语言模型 (Video LLM) 在视频理解方面表现出了良好的能力,但它们在跟踪时间变化和推理时间关系方面却举步维艰。虽然先前的研究将这种限制归因于视觉输入的无效时间编码,但我们的诊断研究表明,视频表示包含足够的信息,即使是小型探测分类器也能实现完美的准确性。令人惊讶的是,我们发现视频 LLM 时间推理能力的关键瓶颈源于底层 LLM 在时间概念方面的固有困难,这从文本时间问答任务的糟糕表现中可以看出。基于这一发现,我们引入了文本时间推理迁移 (T3)。T3 从现有的图像文本数据集中合成纯文本格式的各种时间推理任务,解决了具有复杂时间场景的视频样本稀缺的问题。值得注意的是,在不使用任何视频数据的情况下,T3 增强了 LongVA-7B 的时间理解能力,在具有挑战性的 TempCompass 基准上将绝对准确率提高了 5.3,这使我们的模型的表现优于在 28,000 个视频样本上训练的 ShareGPT4Video-8B。此外,增强后的 LongVA-7B 模型在综合视频基准上实现了具有竞争力的性能。例如,它在 Video-MME 的时间推理任务上实现了 49.7 的准确率,超越了 InternVL-Chat-V1.5-20B 和 VILA1.5-40B 等强大的大型模型。进一步的分析揭示了文本和视频时间任务性能之间的强相关性,验证了将时间推理能力从文本转移到视频领域的有效性。
https://arxiv.org/abs/2410.06166
On The Planning Abilities of OpenAI’s o1 Models: Feasibility, Optimality, and Generalizability
大型语言模型 (LLM) 的最新进展展示了它们执行复杂推理任务的能力,但它们在规划方面的有效性仍未得到充分探索。在本研究中,我们评估了 OpenAI 的 o1 模型在各种基准任务中的规划能力,重点关注三个关键方面:可行性、最优性和可推广性。通过对约束密集型任务(例如,Barman, Tyreworld)和空间复杂的环境(例如,Termes, Floortile),我们强调了 o1-preview 在自我评估和约束遵循方面的优势,同时也确定了决策和内存管理方面的瓶颈,特别是在需要强大空间推理的任务中。我们的结果表明,o1-preview 在遵守任务约束和管理结构化环境中的状态转换方面优于 GPT-4。然而,该模型通常会生成具有冗余操作的次优解决方案,并且难以在空间复杂的任务中有效地概括。这项初步研究为 LLM 的规划局限性提供了基础性见解,为未来改进基于 LLM 的规划中的内存管理、决策和泛化的研究提供了关键方向。

https://www.arxiv.org/abs/2409.19924
TableRAG: Million-Token Table Understanding with Language Models
语言模型 (LM) 的最新进展显著增强了它们推理表格数据的能力,主要是通过操纵和分析表格的程序辅助机制。然而,这些方法通常需要整个表作为输入,由于位置偏差或上下文长度限制,导致可扩展性挑战。为了应对这些挑战,我们推出了 TableRAG,这是一个专为基于 LM 的表格理解而设计的检索增强生成 (RAG) 框架。TableRAG 利用查询扩展与模式和单元格检索相结合来精确定位关键信息,然后再将其提供给 LM。这可以实现更高效的数据编码和精确的检索,从而显着减少提示长度并减少信息丢失。我们从 Arcade 和 BIRD-SQL 数据集开发了两个新的百万标记基准,以全面评估 TableRAG 在规模上的有效性。我们的结果表明,TableRAG 的检索设计实现了最高的检索质量,从而在大规模表格理解方面取得了新的最先进的性能。
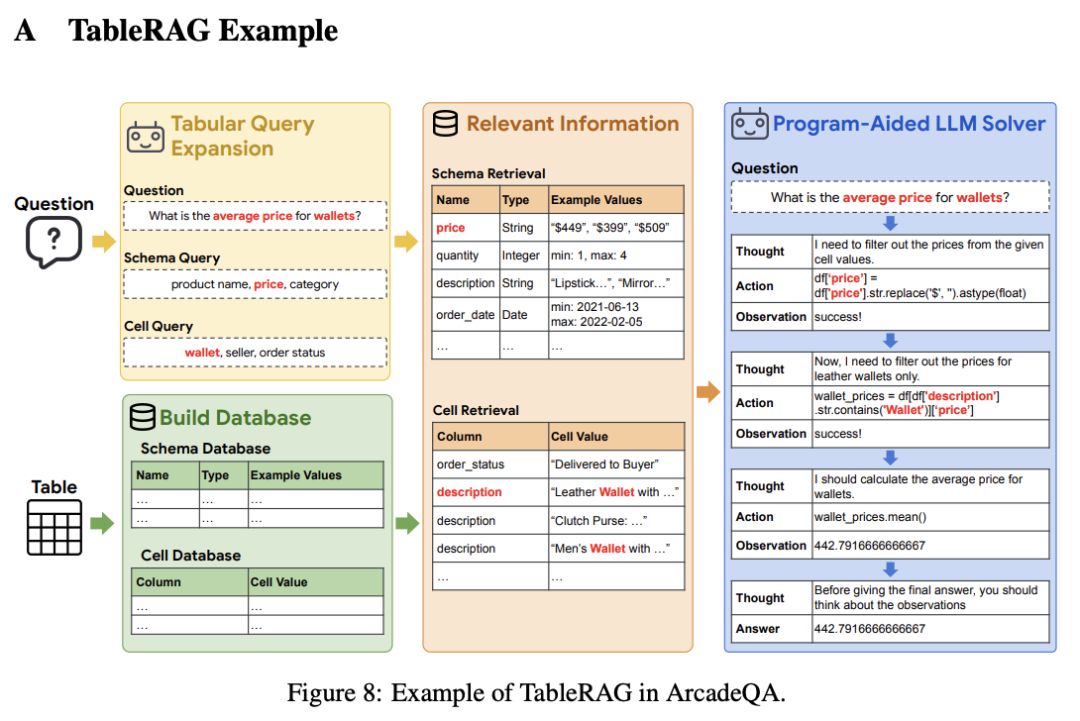
https://arxiv.org/abs/2410.04739
UniMuMo
UniMuMo 是一种统一的多模态模型,能够处理文本、音乐和动作数据,通过对非配对的音乐和动作数据进行基于节奏模式的对齐,解决了时间同步数据的缺乏。该模型采用统一的编码器-解码器变换器架构,将音乐、动作和文本转换为基于标记的表示,以实现跨模态的生成。通过引入运动与音乐的代码本编码、并采用音乐-动作并行生成方案,UniMuMo 将所有生成任务整合为单一的训练任务,显著降低了计算需求。

https://hanyangclarence.github.io/unimumo_demo/
Mistral-NeMo-Minitron-8B-Instruct
英伟达发布的大语言模型可用于生成各种文本生成任务(角色扮演、检索增强生成和函数调用)的响应,支持8K上下文长度。
https://huggingface.co/nvidia/Mistral-NeMo-Minitron-8B-Instruct/tree/main
-
-
-
— END —
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/10/21566.html


