我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


信号
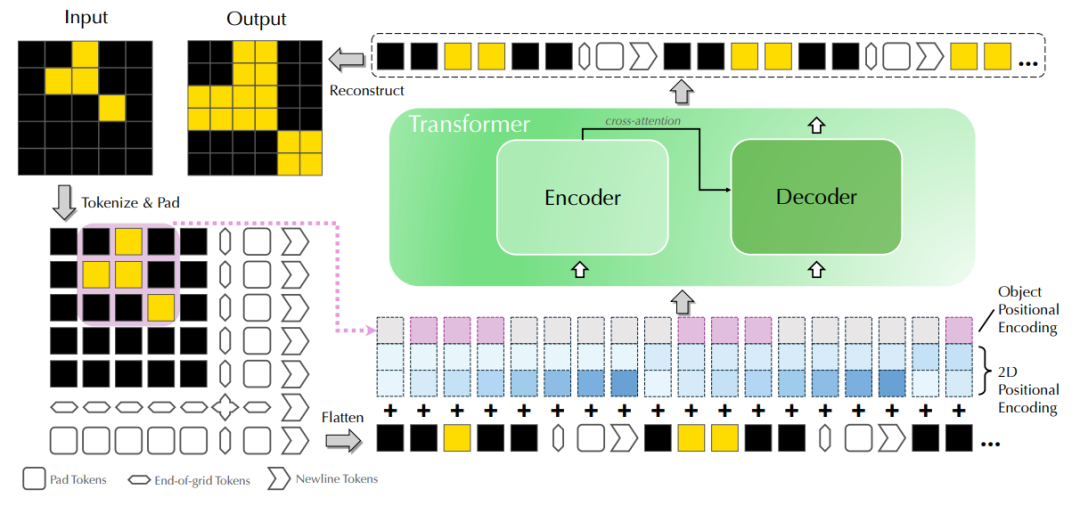
Tackling the Abstraction and Reasoning Corpus with Vision Transformers: the Importance of 2D Representation, Positions, and Objects
抽象与推理语料库 (ARC) 是一种流行的基准测试,专注于人工智能系统评估中的视觉推理。在其原始框架中,ARC 任务需要使用一些输入-输出训练对来解决小型 2D 图像上的程序合成问题。在这项工作中,我们采用了最近流行的数据驱动方法 ARC,并询问 Vision Transformer (ViT) 是否可以学习从输入图像到输出图像的隐式映射,这是任务的基础。我们表明,ViT(否则是最先进的图像模型)在大多数 ARC 任务上都会严重失败,即使每个任务训练了 100 万个样本。这表明 ViT 架构固有的代表性缺陷,使其无法揭示 ARC 任务背后的简单结构化映射。基于这些见解,我们提出了 ViTARC,这是一种 ViT 风格的架构,可解锁 ARC 所需的一些视觉推理功能。具体来说,我们使用像素级输入表示,设计空间感知标记化方案,并引入一种利用自动分割的新型基于对象的位置编码,以及其他增强功能。我们特定于任务的 ViTARC 模型严格通过输入输出网格的监督学习,在 400 个公共 ARC 任务中,有一半以上的任务实现了接近 100% 的测试解决率。这引起了人们对为强大的 (Vision) Transformer 注入正确的归纳偏差以进行抽象视觉推理的重要性,即使在训练数据丰富且映射无噪声的情况下,这些偏差也至关重要。因此,ViTARC 为未来使用基于 transformer 的架构进行视觉推理的研究提供了坚实的基础。
https://arxiv.org/abs/2410.06405
First-Person Fairness in Chatbots
数亿人使用 ChatGPT 之类的聊天机器人,目的多种多样,从简历写作到娱乐。这些现实世界的应用不同于机构用途,例如简历筛选或信用评分,后者一直是人工智能研究偏见和公平性的重点。确保在这些第一人称情境中公平对待所有用户至关重要。在这项工作中,我们研究“第一人称公平”,即对与聊天机器人互动的用户公平。这包括向所有用户提供高质量的响应,无论他们的身份或背景如何,并避免有害的刻板印象。
https://cdn.openai.com/papers/first-person-fairness-in-chatbots.pdf
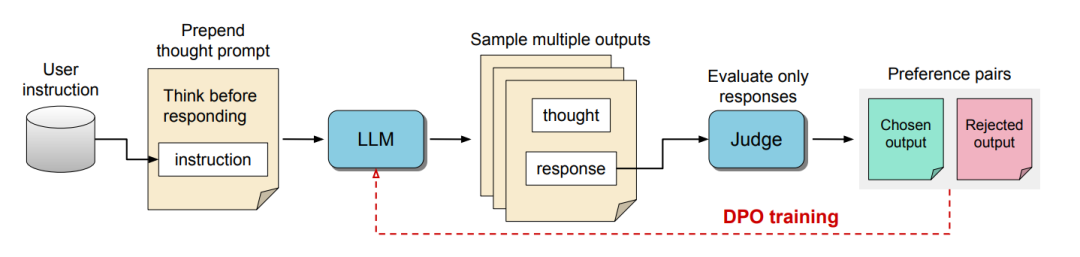
Thinking LLMs: General Instruction Following with Thought Generation
LLMs 通常经过训练,可以回答用户问题或遵循说明,类似于人类专家的回答方式。然而,在标准对齐框架中,他们缺乏在回答之前进行明确思考的基本能力。对于需要推理和规划的复杂问题,思考很重要 – 但可以应用于任何任务。我们提出了一种训练方法,使现有的 LLMs 具有这种思维能力,以便在不使用额外的人类数据的情况下进行一般教学。我们通过迭代搜索和优化程序来实现这一目标,该程序探索可能的思维生成空间,使模型能够在没有直接监督的情况下学习如何思考。对于每条指令,使用裁判模型对候选思想者进行评分,以仅评估他们的回答,然后通过偏好优化进行优化。我们展示了这个程序在AlpacaEval和Arena-Hard上的卓越表现,并且展示了从思考非推理类别如营销、健康和一般知识,以及更传统的推理和问题解决任务中获得的收益。
https://arxiv.org/abs/2410.10630
Animate-X
Animate-X 是一种基于潜在扩散模型的通用动画框架,可以为各种角色(包括拟人角色)生成高质量视频。通过引入姿势指示器,该框架能够全面捕捉运动模式,增强运动表示的能力,并通过新创建的动画拟人基准评估性能。实验结果表明,Animate-X 在动画生成方面优于现有方法。

https://lucaria-academy.github.io/Animate-X/
IterComp
IterComp 是一种先进的文本到图像生成方法,基于 SDXL Base 1.0 进行训练,利用迭代组合感知反馈学习。它可以作为多种生成方法的基础,推荐与 RPG 和 Omost 集成以提升生成效果。
https://huggingface.co/comin/IterComp
1. The theory of LLMs|朱泽园ICML演讲整理
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/10/21589.html