我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢 迎 大 家 一 起 交 流 !
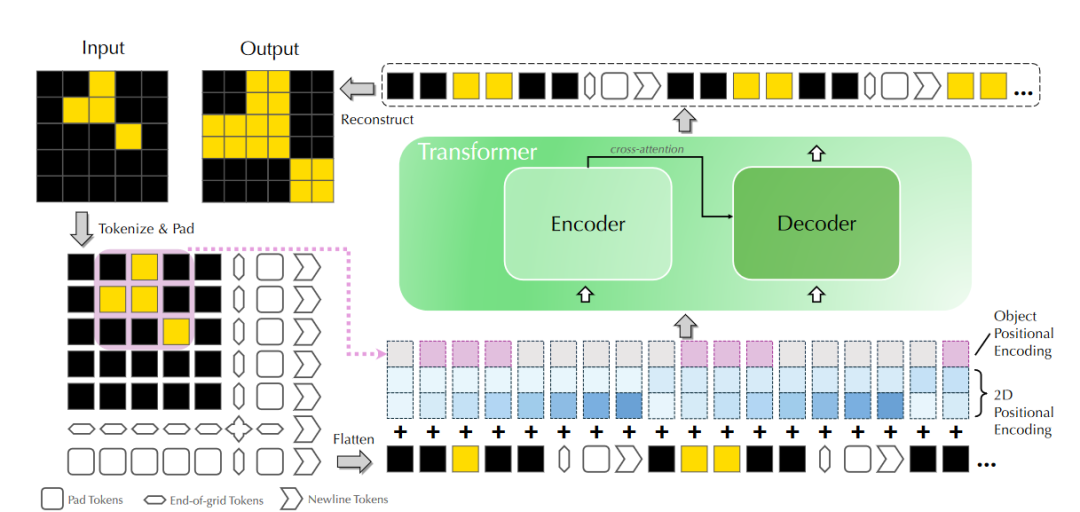
信号 Tackling the Abstraction and Reasoning Corpus with Vision Transformers: the Importance of 2D Representation, Positions, and Objects 抽象与推理语料库(ARC)是一种流行的基准测试,专注于人工智能系统评估中的视觉推理。在其原始框架中,ARC任务需要使用一些输入-输出训练对来解决小型2D图像上的程序合成问题。在这项工作中,我们采用了最近流行的数据驱动方法ARC,并询问VisionTransformer (ViIT)是否可以学习从输入图像到输出图像的隐式映射,这是任务的基础。我们表明,ViT(否则是最先进的图像模型)在大多数ARC任务上都会严重失败,即使每个任务训练了100万个样本。这表明ViT架构固有的代表性缺陷,使其无法揭示 ARC任务背后的简单结构化映射。基于这些见解,我们提出了ViTARC,这是一种ViT风格的架构,可解锁ARC所需的一些视觉推理功能。具体来说,我们使用像素级输入表示,设计空间感知标记化方案,并引入一种利用自动分割的新型基于对象的位置编码,以及其他增强功能。我们特定于任务的ViTARC模型严格通过输入输出网格的监督学习,在400个公共ARC任务中,有一半以上的任务实现了接近100%的测试解决率。这引起了人们对为强大的(Vision) Transformer 注入正确的归纳偏差以进行抽象视觉推理的重要性,即使在训练数据丰富且映射无噪声的情况下,这些偏差也至关重要。因此,ViTARC为未来使用基于transformer的架构进行视觉推理的研究提供了坚实的基础。
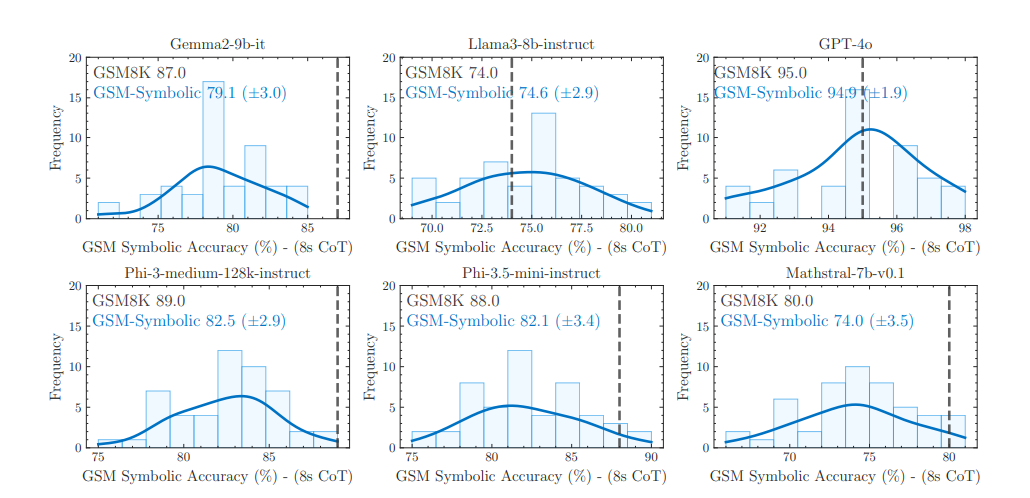
https://arxiv.org/abs/2410.06405 nGPT: Normalized Transformer with Representation Learning on the Hypersphere 本研究提出了一种新颖的神经网络架构,即在超球面上进行表征学习的正则化 Transformer(nGPT)。在 nGPT中,形成嵌入、MLP、注意矩阵和隐藏状态的所有向量都是单位范数正则化的。输入的 token 流在超球面上传播,每一层都会向目标输出预测贡献一个位移。这些位移由 MLP 和注意块定义,它们的向量分量也位于同一个超球面上。实验表明,nGPT的学习速度要快得多根据序列长度,将实现相同准确度所需的训练步骤数减少了 4 到 20 倍。 https://arxiv.org/abs/2410.01131 GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models 大型语言模型(LLM)的最新进展引发了人们对其形式推理能力的兴趣,尤其是在数学方面。GSM8K 基准被广泛用于评估模型在小学水平问题上的数学推理能力。虽然近年来LLM 在GSM8K上的表现显着提高,但尚不清楚它们的数学推理能力是否真正提高了,这引发了人们对报告指标可靠性的质疑。为了解决这些问题,研究者对几个 SOTA 开放和封闭模型进行了大规模研究。为了克服现有评估的局限性,引入了GSM-Symbolic,这是一种改进的基准,由允许生成多样化问题的符号模板创建。研究结果表明,LLM 在回答同一问题的不同实例时表现出明显的差异。具体而言,当在GSM-Symbolic 基准中仅改变问题中的数值时,所有模型的性能都会下降。此外,研究者研究了这些模型中数学推理的脆弱性,并表明随着问题中子句数量的增加,它们的性能会显著下降。研究者假设这种下降是因为当前的LLM无法进行真正的逻辑推理;它们从训练数据中复制推理步骤。添加一个似乎与问题相关的子句会导致所有最先进模型的性能显著下降(高达65%),即使该子句对最终答案所需的推理链没有贡献。总的来说,笔者们的工作提供了对 LLM 在数学推理方面的能力和局限性的更细致的理解。
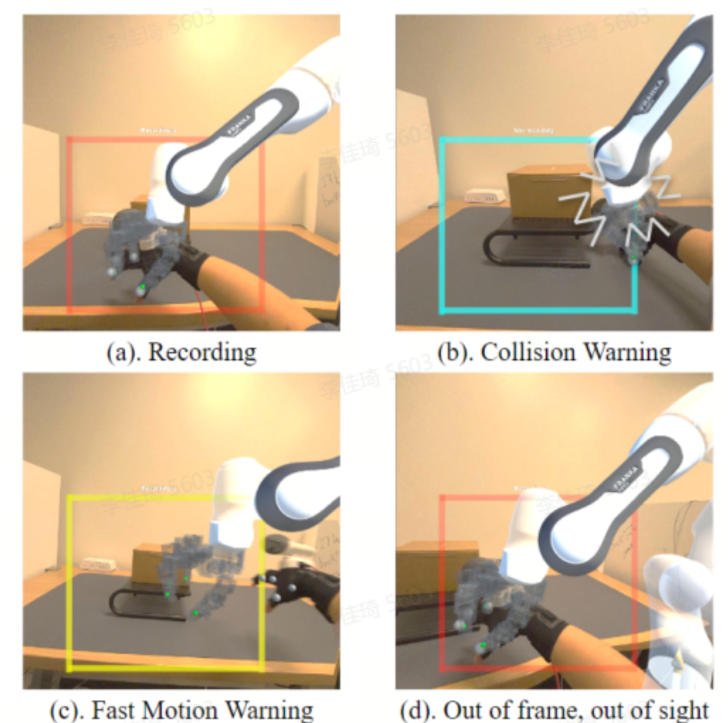
https://arxiv.org/abs/2410.05229 ARCap: Collecting High-quality Human Demonstrations for Robot Learning with Augmented Reality Feedback 这篇文章介绍了一种名为ARCap的便携式数据收集系统,它通过增强现实(AR)提供视觉反馈和触觉警告来指导用户收集高质量的演示数据。ARCap旨在解决使用便携设备进行数据收集时缺乏机器人实时反馈的问题,使得即使是新手用户也能收集到符合机器人运动学要求且避免场景碰撞的数据。实验表明,使用ARCap收集的数据可以帮助机器人执行复杂的任务,如在杂乱环境中操作物体以及跨不同机器人形态的长时间操作。ARCap是完全开源的,并且易于校准,所有组件都是由现成产品构建而成。
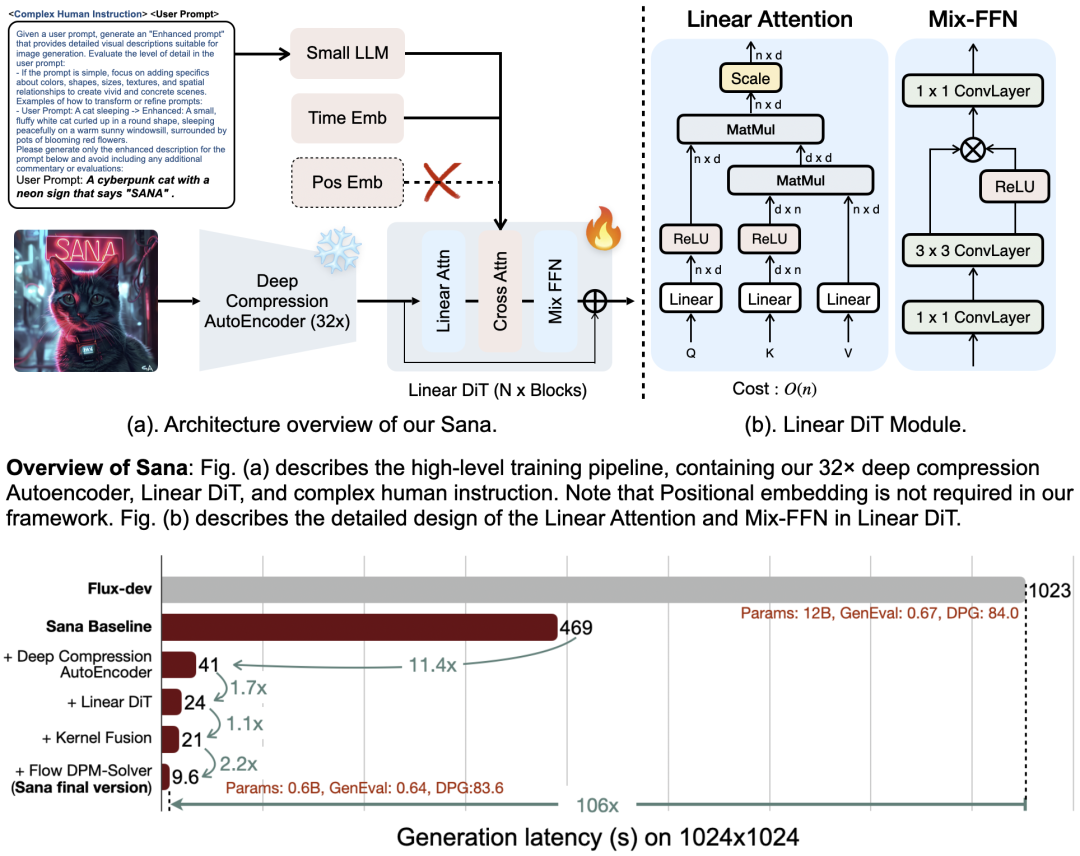
https://arxiv.org/abs/2410.08464 Sana Sana 是一个高效的文本到图像生成框架,能够生成高达 4096 × 4096 分辨率的图像。其核心设计包括深度压缩自编码器、线性 DiT 和仅解码的小型 LLM 作为文本编码器,显著提高了图像生成的速度和质量。Sana-0.6B 相比大型模型更小、更快,可在 16GB 笔记本 GPU 上快速生成图像,提供低成本的内容创作解决方案。 https://nvlabs.github.io/Sana/ Qihoo-T2X Qihoo-T2X是一系列基于PT-DiT架构的模型,可以处理不同的生成任务,包括图像生成(T2I)、视频生成(T2V)和多模态视频生成(T2MV)。这些模型利用了稀疏代表性注意力机制,以高效地捕捉全局视觉信息,同时降低计算复杂度。Qihoo-T2X系列的模型通过优化自注意力机制和跨注意力机制,能够在生成任务中实现竞争力的性能,尤其是在图像和视频生成方面。 https://360cvgroup.github.io/Qihoo-T2X/
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/10/21628.html