Adaptive Data Optimization: Dynamic Sample Selection with Scaling Laws
目前并没有一个标准指南来指导如何在有限的计算预算下分配不同数据源。大多数现有方法要么依赖于对较小模型的广泛实验,要么通过需要Proxy模型的动态数据调整,这两者都显著增加了工作流程的复杂性和计算开销。本篇论文引入了一种名为Adaptive Data Optimization(ADO)的算法,该算法在模型训练过程中在线优化数据分布。ADO使用每个领域的Scaling Law来估计 该领域在训练过程中的学习潜力,并相应调整数据组合,使其更具可扩展性并更易于集成。https://x.com/SadhikaMalladi/status/184869662976501810302
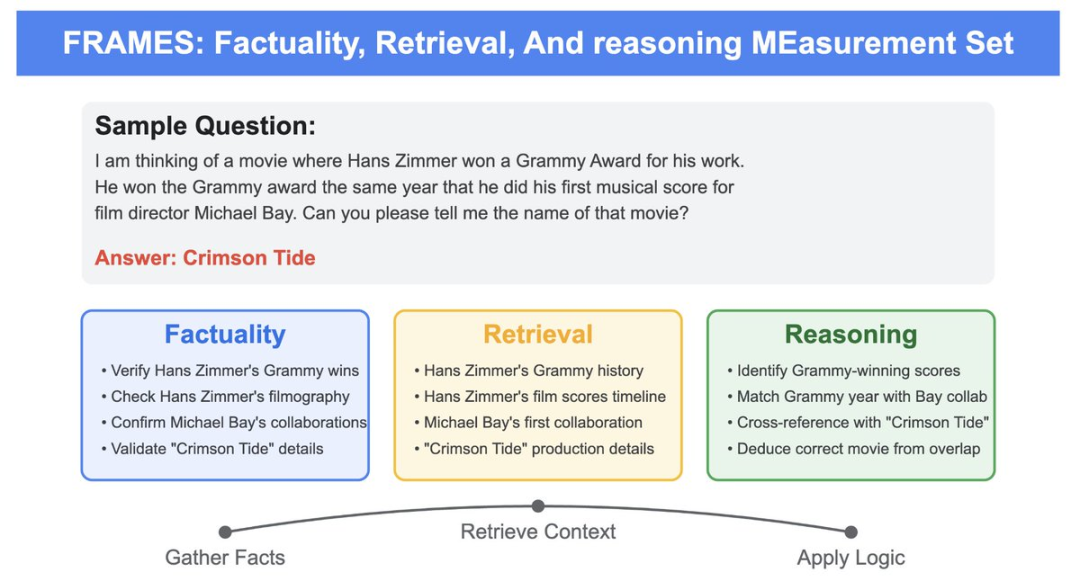
Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation
大型语言模型(LLMs)在各种认知任务中表现出显著的性能提升。一个新兴的应用是利用 LLMs RAG 的能力。这些系统要求LLMs理解用户查询,检索相关信息,并生成连贯且准确的回应。鉴于此类系统在现实世界中的应用日益增加,全面的评估变得至关重要。为此,作者提出了FRAMES(Factuality, Retrieval, And reasoning MEasurement Set),这是一个高质量的评估数据集,旨在测试LLMs提供事实性回应的能力、评估其检索能力以及生成最终答案所需的推理能力。虽然之前的研究提供了评估这些能力的单独数据集和基准,FRAMES则提供了一个统一的框架,可以更清晰地展示LLMs在端到端RAG场景中的表现。https://x.com/SatyaScribbles/status/184872168170949848003
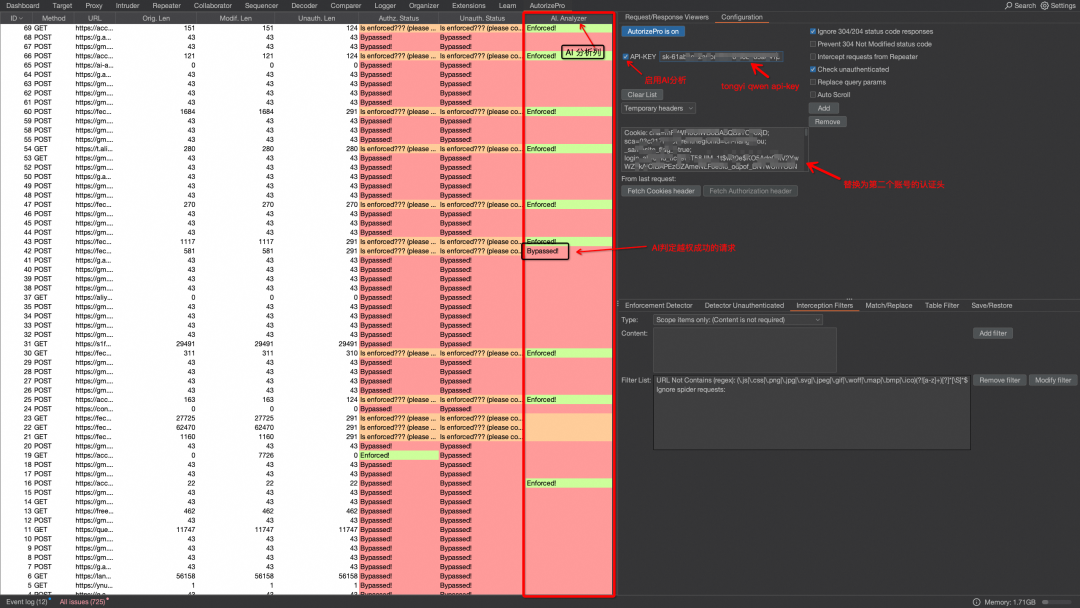
AutorizePro 是一款专注于越权检测的 Burp 插件。它基于 Autorize 插件进行二次开发,通过增加 AI 分析模块和优化检测逻辑,大幅降低了误报率,提升了越权漏洞检出效率。https://github.com/sule01u/AutorizePro02
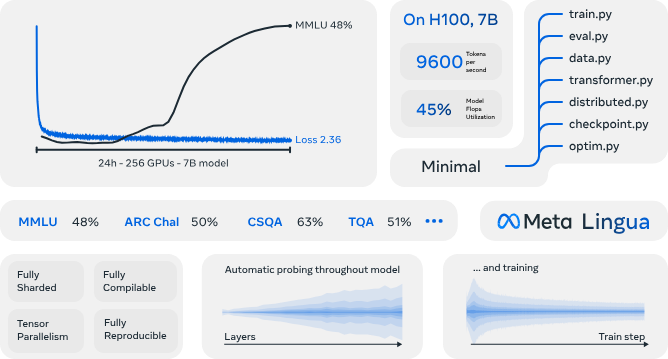
Meta Lingua
Meta Lingua 是一个轻量级、高效和易于修改的 PyTorch LLM 训练库,可以为 LLM 研究提供一个简单易用的框架。https://github.com/facebookresearch/lingua 推荐阅读 — END —1. The theory of LLMs|朱泽园ICML演讲整理