我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


信号
Nemotron-CC: Transforming Common Crawl into a Refined Long-Horizon Pretraining Dataset
最近的 English Common Crawl 数据集(例如 FineWeb-Edu 和 DCLM)通过积极的基于模型的过滤取得了显着的基准收益,但代价是删除了 90% 的数据。这限制了它们对长token范围训练的适用性,例如 Llama 3.1 的 15T token。在本文中,我们展示了如何通过结合分类器集成、合成数据重写和减少对启发式过滤器的依赖,在准确性和数据量之间实现更好的权衡。当为 1T token训练 8B 参数模型时,使用我们数据的高质量子集将 MMLU 比 DCLM 提高了 5.6,这证明了我们的方法在相对较短的token范围内提高准确性的有效性。此外,我们完整的 6.3T token数据集与 MMLU 上的 DCLM 相匹配,但包含的独特真实token数量是 DCLM 的四倍。
https://arxiv.org/abs/2412.02595
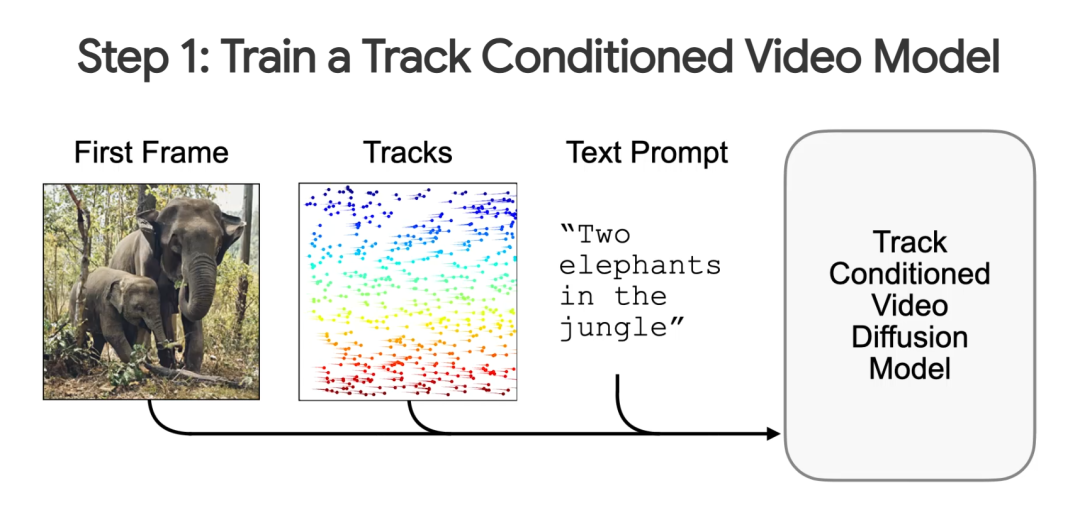
Motion Prompting: Controlling Video Generation with Motion Trajectories
运动控制对于生成富有表现力和引人注目的视频内容至关重要;然而,大多数现有的视频生成模型主要依靠文本提示进行控制,很难捕捉动态动作和时间合成的细微差别。为此,我们训练了一个以时空稀疏或密集运动轨迹为条件的视频生成模型。与之前的运动调节工作相比,这种灵活的表示可以编码任意数量的轨迹、特定对象或全局场景运动以及时间稀疏运动;由于其灵活性,我们将这种调节称为运动提示。虽然用户可以直接指定稀疏轨迹,但我们还展示了如何将高级用户请求转换为详细的半密集运动提示,我们将这个过程称为运动提示扩展。我们通过各种应用展示了我们方法的多功能性,包括相机和对象运动控制、与图像“交互”、运动传输和图像编辑。我们的结果展示了新兴行为,例如现实物理,表明运动提示在探索视频模型以及与未来生成世界模型交互方面的潜力。最后,我们进行定量评估,进行人体研究,并展示强大的性能。
https://motion-prompting.github.io/
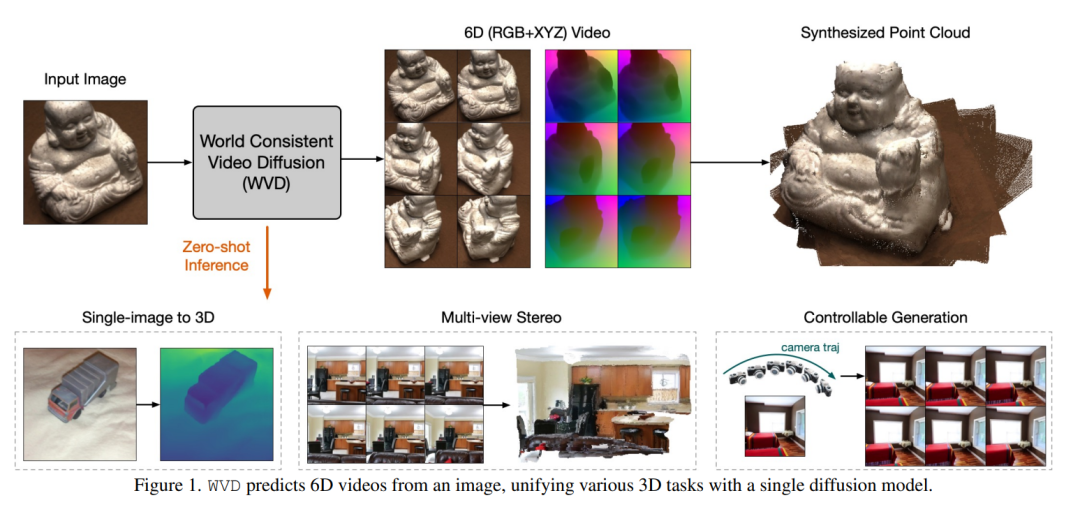
World-consistent Video Diffusion with Explicit 3D Modeling
扩散模型的最新进展为图像和视频生成树立了新的基准,实现了跨单帧和多帧上下文的逼真视觉合成。然而,这些模型仍然难以高效、明确地生成 3D 一致的内容。为了解决这个问题,我们提出了世界一致视频扩散(WVD),这是一种新颖的框架,它结合了使用 XYZ 图像的显式 3D 监督,对每个图像像素的全局 3D 坐标进行编码。更具体地说,我们训练一个扩散变换器来学习 RGB 和 XYZ 帧的联合分布。这种方法通过灵活的修复策略支持多任务适应性。例如,WVD 可以根据真实 RGB 估计 XYZ 帧,或者使用沿指定相机轨迹的 XYZ 投影生成新的 RGB 帧。为此,WVD 统一了单图像到 3D 生成、多视图立体和摄像机控制视频生成等任务。我们的方法在多个基准测试中展示了具有竞争力的性能,为使用单个预训练模型生成 3D 一致的视频和图像提供了可扩展的解决方案。
 https://arxiv.org/abs/2412.01821
https://arxiv.org/abs/2412.01821
Digma 无需离开 IDE 即可持续识别性能问题工具
Digma 是一款在运行时分析应用程序执行情况并识别关键性能问题的工具。Digma 由一个分析后端(在容器上本地运行)和一个作为主要前端的 IDE 插件组成(目前仅限 Jetbrains)。该插件提供与性能、查询问题、瓶颈扩展问题等相关的代码级洞察。
Digma 的后端从您的应用程序接收 OTEL 数据(在本地运行应用程序时自动收集),对其进行分析,并识别代码执行中的特定问题。所有数据都在本地处理,以支持合规性要求,无需更改代码。Digma 摄像头配置文件数据来自多个环境,包括开发、测试、准备、生产等。
Digma认为,除非应用程序分析是连续且自动的(就像测试一样),否则它不会有效。目前有许多可观察性工具,但它们都需要积极和手动地花费时间、注意力和专业知识才能获得结果。当发生可怕的事情时,它们只会被动使用,这并不奇怪。可观察性的最终目标不应该是创建仪表板,而应该是改进我们的应用程序和代码。
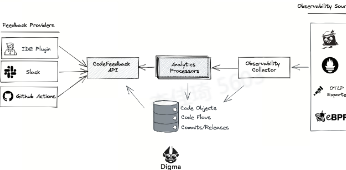
https://github.com/digma-ai/digma
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/12/24315.html