
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


信号
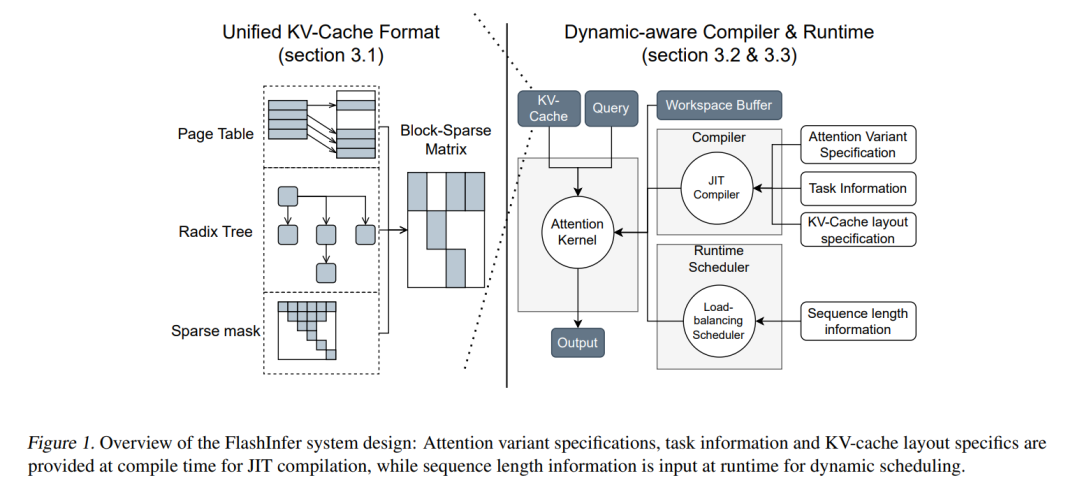
FlashInfer: Efficient and Customizable Attention Engine for LLM Inference Serving
-
灵活的块稀疏格式: FlashInfer采用块稀疏格式来应对KV缓存存储的异质性问题。这种格式为不同的KV缓存配置提供了统一的数据结构,允许调整块大小以实现精细的稀疏化,如向量级稀疏化。这种方法统一了多种KV缓存模式,并提升了内存访问效率。 -
可定制的注意力模板: FlashInfer提供了一个可定制的注意力模板,支持多种注意力变种。用户可以通过自定义编程接口实现其特定的注意力变体,并利用即时编译(JIT)技术将这些变体转化为高度优化的块稀疏实现,从而确保能够快速适应不同的注意力配置。 -
动态负载均衡调度框架: FlashInfer设计了一个动态负载均衡的调度框架,有效应对输入动态性。它将编译时的块大小选择与运行时的调度分离,通过轻量级API适应推理过程中KV缓存长度的变化,同时保持与CUDA-Graph在常配置要求下的兼容性,最大化硬件利用率。 -
全面的性能评估: 我们对FlashInfer在标准LLM推理环境和创新场景(如前缀共享和推测解码)中的表现进行了广泛评估。通过与主流LLM推理引擎(如vLLM、MLC-Engine和SGLang)集成,FlashInfer在端到端延迟和吞吐量方面表现出了显著的改进,特别是在长上下文推理和并行生成等新型应用中。
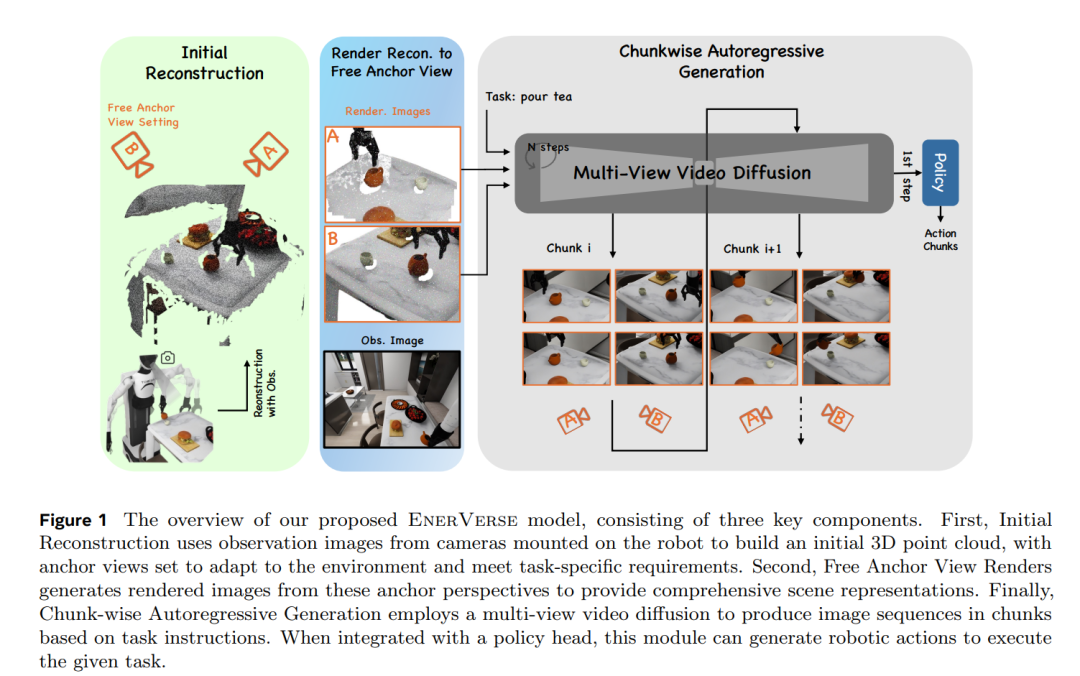
EnerVerse: Envisioning Embodied Future Space for Robotics Manipulation
-
块状自回归扩散模型:作者提出了一种新颖的自回归模型,结合了双向机制以实现局部一致性以及单向范式以进行长距离推理。这使得任务执行的推理更加准确,解决了机器人操作任务中冗余内存的挑战. -
稀疏上下文记忆机制:为了防止在长序列中模型崩溃,作者引入了一种稀疏上下文记忆机制,确保生成过程的非冗余性,使系统能够生成无限长度的序列,并具有连贯的序列理解能力. -
自由锚点视图(FAV)概念:FAV系统为机器人相机提供了灵活的任务特定视角,增强了空间感知能力,并缓解了身体安装相机的外部变化等问题。FAV系统通过提供多视角观察,减少了度量模糊性,加深了对环境的理解,从而提高了任务泛化能力和策略学习效果. -
4D高斯喷溅(4DGS)和数据飞轮:为了克服仿真到现实的差距和数据稀缺问题,论文引入了一个数据引擎管道,结合生成模型和4DGS优化。该系统生成了大量合成数据,并不断改进模型性能,显著增强了FAV系统的鲁棒性. -
最先进的(SOTA)性能:作者通过将扩散模型和朴素策略头整合用于未来空间生成,展示了其方法的有效性,在长距离操作任务中取得了SOTA结果.
VITA-1.5: Towards GPT-4o Level Real-Time Vision and Speech Interaction
-
三阶段训练方法: -
第一阶段:视觉-语言训练:在第一阶段,模型通过训练视觉适配器,并使用描述性字幕和视觉问答数据进行微调,从而奠定了模型在图像和视频理解方面的基础能力。 -
第二阶段:音频输入训练:第二阶段引入了语音数据,训练了一个音频编码器,使用语音与转录对数据进行训练,并通过语音问答数据进行微调。这个阶段使得模型能够有效理解并响应语音输入,架起了视觉和语音模态之间的桥梁。 -
第三阶段:音频解码器训练:最后,模型训练了音频解码器,使其能够进行端到端的语音生成,从而消除了对传统文本转语音(TTS)系统的依赖。这一创新使得VITA-1.5能够生成流畅且自然的语音回复,提升了多模态对话系统的自然性和交互性。 -
缓解模态冲突: 视觉和语音数据的整合是复杂的,因为它们在信息表达上存在本质差异。视觉数据传递空间信息,而语音数据则涉及时间序列的动态变化。VITA-1.5通过逐步训练的方法,有效缓解了训练过程中模态之间的冲突,确保了三种模态在多模态任务中的强大表现。 -
端到端的多模态对话: 与传统的语音对语音系统依赖单独的自动语音识别(ASR)和文本转语音(TTS)模块不同,VITA-1.5将这些功能集成在一起,减少了延迟,并提升了系统的连贯性,尤其适用于实时应用。模型能够同时处理视觉和语音输入,并生成语音输出,从而实现更加自然、流畅的人机交互。 -
性能评估: 在图像、视频和语音理解的多个基准测试中,VITA-1.5展现了与领先的多模态语言模型相当的感知和推理能力,尤其在语音能力方面取得了显著的提升。这表明VITA-1.5在多模态理解方面表现强劲,是高级交互系统的理想选择。

Virgo: A Preliminary Exploration on Reproducing o1-like MLLM
-
基于文本的长思维数据增强MLLM的慢思维能力: 本文提出了一种简单的思路,通过使用文本数据来微调MLLM,从而增强其慢思维推理能力。研究的核心问题是:是否可以通过基于文本的长思维数据来迁移慢思维能力?文本推理指令是否能与多模态推理系统的慢思维能力相媲美?为此,本文设计了一个名为Virgo(视觉推理与长思维)的系统,结合了多种指令数据集对MLLM进行微调,以研究这些问题。 -
实验验证与效果: 研究通过在四个具有挑战性的基准任务上(MathVerse、MathVision、OlympiadBench、MMMU)进行广泛实验,验证了基于文本的长思维数据的有效性。结果显示,即便仅使用文本数据,Virgo也能在推理能力上与商业推理系统相媲美,甚至在某些情况下超越它们。这表明,文本推理指令在激发MLLM慢思维能力方面通常比多模态推理数据更为有效。 -
慢思维能力的迁移: 通过基于文本的长思维数据进行微调,Virgo成功将慢思维推理能力从文本推理系统迁移到多模态系统,展示了文本指令对多模态推理任务的显著影响。这一发现为进一步提升多模态LLM的推理能力提供了新的视角,并强调了跨模态学习的潜力。

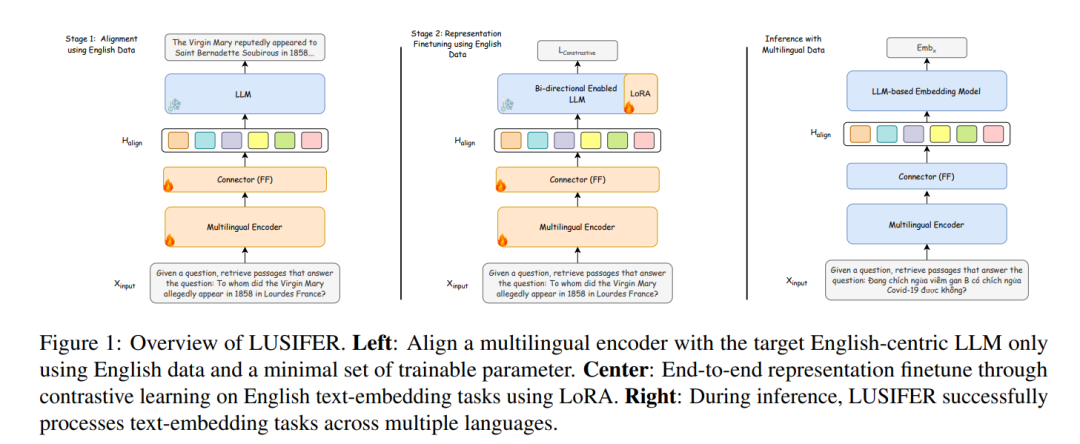
LUSIFER: Language Universal Space Integration for Enhanced Multilingual Embeddings with Large Language Models
-
zero-shot多语言嵌入: LUSIFER采用了一种独特的架构,将XLM-R(一种强大的多语言编码器)的多语言表示与英语LLM嵌入模型的高级嵌入能力结合。通过引入可学习的连接机制,LUSIFER能够有效地将XLM-R的多语言理解能力转移到目标LLM,并在不需要显式的多语言训练数据的情况下,实现多语言表示能力的提升。 -
跨语言任务的显著提升: LUSIFER在123个多样化数据集上进行了全面的实验,涵盖了14种语言,并聚焦于五个基本的嵌入任务:分类、聚类、重排序、检索和语义文本相似度(STS)。实验结果表明,LUSIFER在所有任务上的平均提升为3.19分,尤其对中低资源语言的提升效果显著(最高可达22.15的提高)。此外,在跨语言任务中,LUSIFER比现有的英语中心嵌入模型平均提高了5.75分。 -
语言无关的通用空间: LUSIFER的理论基础在于其通过集成多语言编码器(如XLM-R)创建了一个语言无关的通用空间。这一空间使得模型能够独立于输入语言处理语义信息,从而增强了目标LLM对各种语言的嵌入质量,尤其是对于在预训练中少见的语言。通过将这些语言中立的表示映射到目标LLM的输入空间,LUSIFER显著提高了不同语言间的语义捕捉能力。 -
跨语言应用的广泛适应性: 为了验证LUSIFER的广泛适用性,作者还在超过100种语言的四个跨语言数据集上进行了测试。结果显示,LUSIFER在这些跨语言场景中大幅优于现有的英语中心嵌入模型,表现出强大的跨语言能力和对低资源语言的优越适应性。
2. 「理论与实践」AIPM 张涛:关于Diffusion你应该了解的一切
3. 「奇绩潜空间」吕骋访谈笔记 | AI 硬件的深度思考与对话
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/01/32612.html