我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。


信号
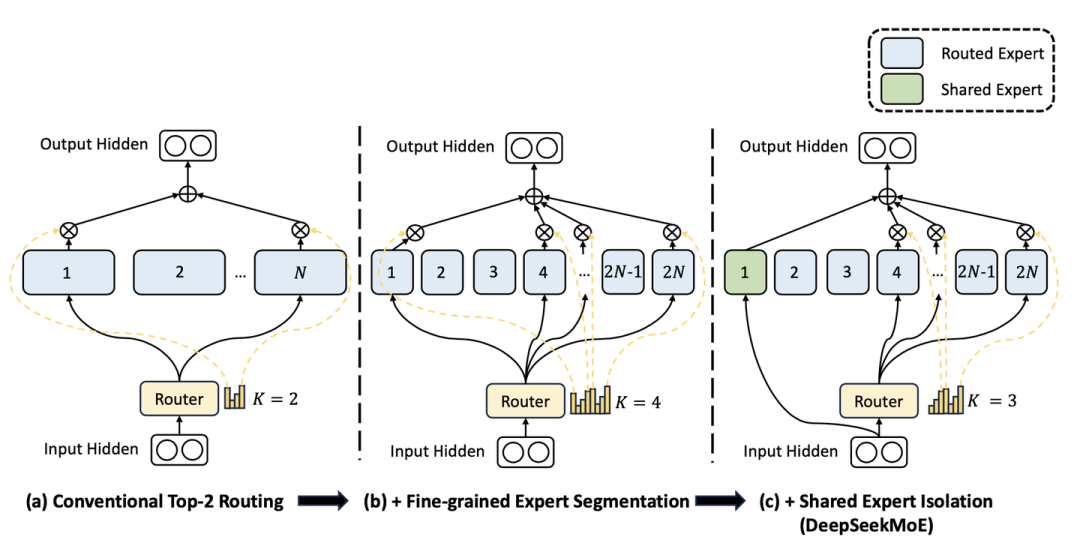
关于 MoE 大模型负载均衡策略演进的回顾:坑点与经验教训
从 GShard 开始,稀疏专家(Sparse MoE)架构的出现揭示了通过“稀疏化”来实现超大规模模型的训练。其核心思想是,每个 token 只激活少数专家,而不是全量激活所有专家,从而大幅提升计算效率。然而,这也带来了负载均衡问题,即如何确保每个专家的负担均匀,避免某些专家过载,而其他专家则空闲。
GShard 是首个大规模实现 MoE 的框架,采用 top-2 gating 的路由机制,在每个层次上只激活排名前两的专家。为了避免某些专家被过多 token 激活,GShard 引入了容量因子(每个专家最大处理的 token 数)和辅助负载均衡损失,以促进负载均衡。然而,这种方法会牺牲一些精度,因为过度均衡可能会限制专家的多样性。
Switch Transformer 通过只为每个 token 选择一个专家(top-1 gating)进一步简化了路由机制。这使得模型计算更加高效,但也带来了负载不均的问题,特别是在容量因子设置不当时。尽管如此,Switch Transformer 的成功展示了 MoE 模型在大规模扩展时的潜力。
GLaM 引入了能效优化,重新采用 top-2 gating,同时关注减少计算和能耗。通过辅助损失和容量约束,GLaM 达到较高的效率,尽管仍然需要精细调节路由和容量因子。DeepSpeed-MoE 则从训练和推理两个阶段优化了负载均衡,通过多专家并行和动态重分配 token 来保证效率。
ST-MoE 提出了路由器 Z-Loss,旨在稳定训练过程,减少数值不稳定带来的问题,并进一步调优容量因子,以提升模型质量。Mixtral 采用时间局部性分析,优化了专家分配,使得相邻 token 经常由同一个专家处理,减少了负载的波动。此外,它还引入了稀疏 Kernel 优化,进一步提升了 GPU 负载均衡。
DeepSeekMoE 通过细粒度专家和共享专家的概念,减少了参数冗余,并提出了双重负载均衡损失——专家级和设备级负载均衡,确保了模型在大规模并行计算中的高效性。JetMoE 则实现了“无 token 丢弃”策略,通过流水线并行减少了通信开销。
Skywork-MoE 提出了 gating logit 归一化和自适应辅助损失,解决了不同层次负载均衡的问题。最后,DeepSeek-V3 通过偏置调节替代了大规模辅助损失,提出了无辅助损失的负载均衡策略,并在并行计算中引入了动态路由和节点限制的优化,减少了通信开销。
从 GShard 到 DeepSeek-V3,MoE 架构中的负载均衡问题逐步被细化和优化。每个方案都有其创新之处,但也面临着如超参数调优、容量因子调整、数据分布不均等挑战。未来的研究将进一步探索自动化、适应性更强的路由机制,利用更多的高性能计算技术来提升训练和推理效率。
https://zhuanlan.zhihu.com/p/19117825360
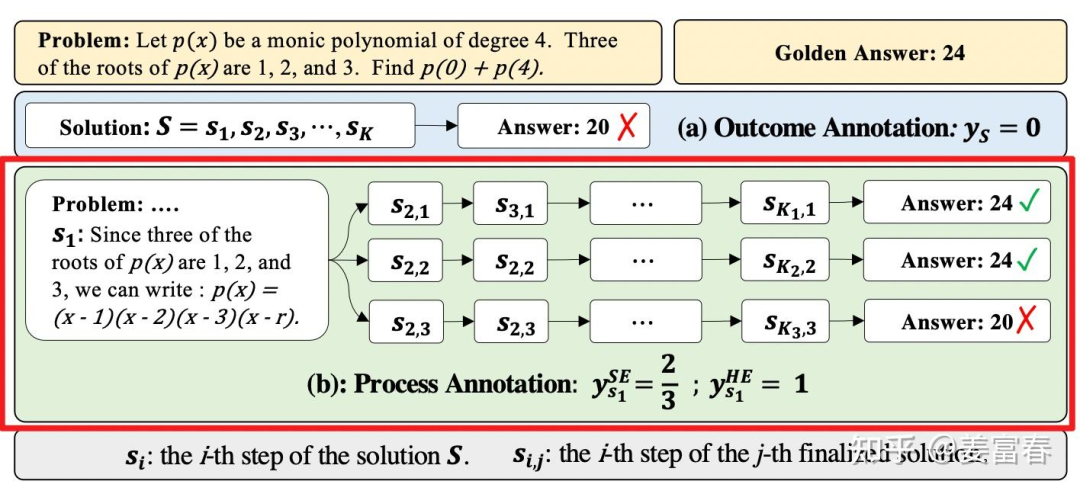
OpenRLHF源码解读:理解PRM(过程奖励模型)训练过程
PRM训练的样本数据来自两个主要来源:OpenAI的人工标注数据集PRM800K和北大等发布的Math-Shepherd数据集,后者通过MCTS(蒙特卡洛树搜索)方法进行自动标注。MCTS的基本原理是通过多次仿真交互生成一个搜索树,并计算每个节点的奖励值。在自动标注过程中,首先训练一个生成器模型(使用gsm8k数据集),该模型能够按照步骤生成解题过程。生成器训练后,通过MCTS选择未被探索的节点进行扩展,模拟后通过回传计算各节点的奖励值。这些奖励值用于指导自动标注过程,从而生成带有正确与否标记的样本数据。
在Math-Shepherd中,数据被处理为包含问题描述、按步骤的解题过程以及每个步骤的正负奖励标记的形式。每个步骤的奖励标记用“+”表示正确,”-“表示错误,这些信息构成了训练数据的核心。在数据预处理阶段,通过ProcessRewardDataset类提取每条数据的奖励值,并基于标记将输入数据处理成token化的格式,其中占位符”ки”用于分隔步骤,标签列则根据“+”与“-”标记生成对应的奖励值数组。
PRM模型的结构采用了基于CausalLM的架构,且使用交叉熵损失函数进行训练。PRMLoss是核心的损失计算模块,其计算过程如下:首先,通过mask提取出token序列中占位符位置的logits和标签。然后,从logits中提取“+”与“-”的预估值,并将标签转化为分类标识(0表示“+”,1表示“-”)。最后,利用交叉熵计算损失值,模型根据这个损失值进行反向传播和优化。
https://zhuanlan.zhihu.com/p/16027048017
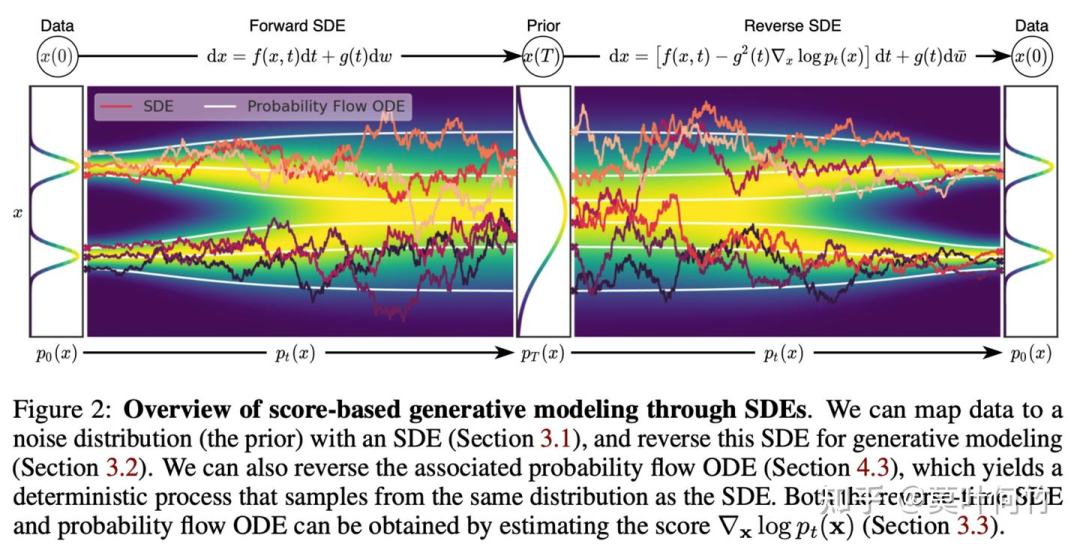
diffusion model(十九) :SDE视角下的扩散模型
生成模型的目标是通过建立从先验分布到数据分布的映射,实现在数据分布上采样生成样本。传统的生成模型包括前向过程和后向过程。前向过程将原始数据分布样本映射到先验分布,而后向过程则从先验分布中采样并通过训练好的生成模型映射回原始数据分布。扩散模型采用类似的方法,但将数据分布到先验分布的转移过程拆分为多个时间步,视为两个随机过程。
扩散模型的前向和后向过程可以用Itô型随机微分方程(SDE)进行建模。布朗运动是SDE理论的基础,它描述了微小粒子在流体中随机运动的行为。通过Wiener过程和Itô方程的研究,SDE成为了描述随机过程的重要工具。前向SDE描述了数据从原始分布到先验分布的变化过程,而后向SDE则用于描述从先验分布到数据分布的恢复过程。
SMLD(Score Matching with Langevin Dynamics)和DDPM(Denoising Diffusion Probabilistic Models)是两种常见的扩散模型,它们通过不同的方式定义前向和后向过程的SDE。SMLD的前向过程通过引入高斯噪声扩展训练数据空间,并通过score matching最小化估计和实际score之间的误差。其反向过程利用朗之万采样生成数据。DDPM则通过加噪过程和去噪过程来实现数据生成,利用KL散度来优化噪声估计。
在SDE框架下,采样过程可以通过数值方法进行求解,例如欧拉丸山法(Euler-Maruyama)进行差分近似。PC-sampling方法则结合了预测和修正步骤,用于统一DDPM和SMLD的采样方法。在这一过程中,predictor基于反向扩散SDE求得当前时间步的样本,而corrector则利用退火朗之万动力学进行修正。
此外,所有的扩散过程都可以通过找到对应的确定性过程,用ODE(常微分方程)来描述。与SDE相比,ODE不包含随机性,采样结果是确定性的,这为生成模型提供了语义插值效应的可能性。
https://zhuanlan.zhihu.com/p/15735244511
基于开放模型的推理时计算缩放
近年来,大型语言模型(LLM)的进展主要依赖于训练时计算的缩放,但这一方式成本高昂且资源消耗巨大。因此,推理时计算的缩放作为一种补充方法逐渐受到关注,特别是在不依赖庞大预训练预算的情况下,通过动态推理策略使模型在推理过程中能够进行更长时间的“思考”。DeepMind的研究指出,通过迭代式自完善或奖励模型的解空间搜索,可以有效地提高推理时计算缩放的效率。较小的模型可以通过优化推理时计算来与更大的模型相媲美,甚至在某些任务中超越它们。
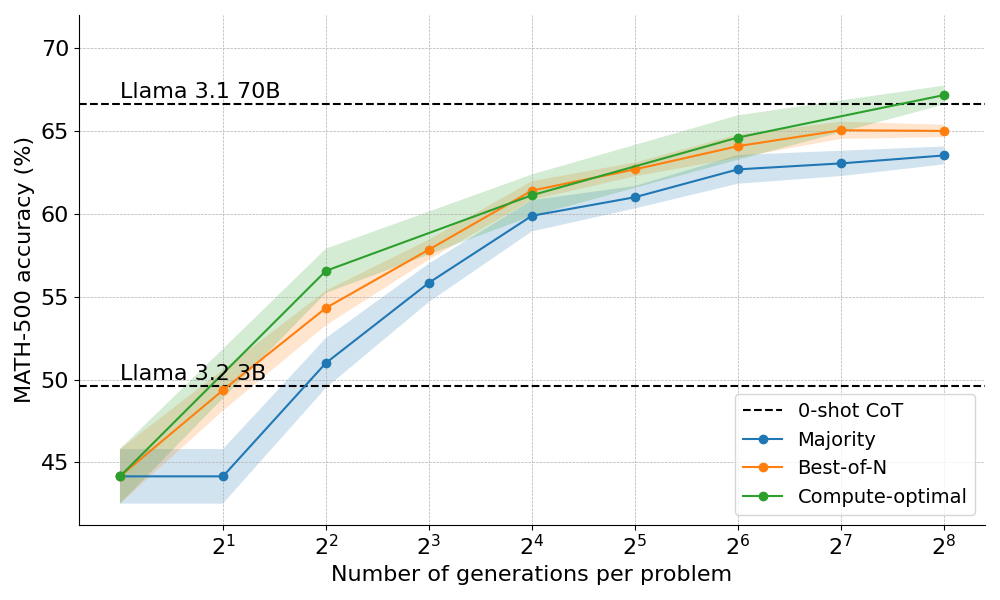
推理时计算缩放的策略有两种主要方法:自完善和基于验证器的搜索。自完善通过模型自我迭代来改进输出,而基于验证器的搜索则侧重于生成多个候选答案,并由验证器选择最佳答案。验证器的形式可以是启发式规则或奖励模型,常见的搜索方法包括拔萃采样(Best-of-N Sampling)、波束搜索和多样化验证器树搜索(DVTS)。这些方法各有优劣,尤其是在计算预算较高时,波束搜索和DVTS能有效提升模型的推理能力。
具体的推理过程通常包括生成多个中间步骤,并由过程奖励模型(PRM)对每个步骤进行评分,最终通过不同的搜索策略选择最优路径。实验中,使用Llama-1B模型和PRM对数学基准MATH-500子集进行推理,结果表明,在较高的推理预算下,波束搜索和DVTS能够显著提高模型的表现。波束搜索能够系统地探索解空间,优先考虑潜力路径,而DVTS则通过扩展子树来提高解的多样性,尤其在计算预算较大的情况下表现更为出色。
为进一步优化推理时计算,研究提出了计算最优缩放策略。该策略通过分析不同难度问题的表现,结合推理时计算预算来选择最合适的搜索方法。例如,在简单问题和低计算预算下,拔萃法表现较好;而在难题中,波束搜索更为高效。这种方法已成功扩展到Llama 3B模型,并使其超越了Llama 70B模型,证明了计算时缩放策略的强大潜力。
未来的研究方向包括增强验证器的鲁棒性、探索自验证机制,以及将搜索策略扩展到更广泛的任务领域。推理时计算缩放不仅能优化LLM在数学和代码推理上的能力,还可能为解决其他复杂任务提供新思路。
https://zhuanlan.zhihu.com/p/15951981658
HuggingFace&Github
00Arxiver开源:包含 138,830 篇 arXiv 论文的多Markdown格
MiniCPM-o 2.6 :多模态大语言模型
MiniCPM-o 2.6是一个多模态大语言模型,支持视觉、语音和多模态实时流媒体处理。能同时处理图像、视频、文本和音频输入,并生成高质量的文本和语音输出,同时具有强大的端到端处理能力。
-
支持高效的光学字符识别(OCR),可处理最大1.8百万像素的图像,超越了大多数同类模型
-
-
在自动语音识别(ASR)、语音翻译等语音理解任务上表现优秀
-
支持语音创建(Instruction-to-Speech),语音克隆(Voice Cloning)和 多回合对话和视频输入的聊天
-
高效支持iPad 等端侧设备上的多模态直播。在多个视觉基准测试中表现出色,尤其在单图像、多图像和视频理解上超越了如GPT-4o-202405、Claude 3.5 Sonnet等模型。
https://github.com/OpenBMB/MiniCPM-o?tab=readme-ov-file
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/01/36485.html