我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。


信号
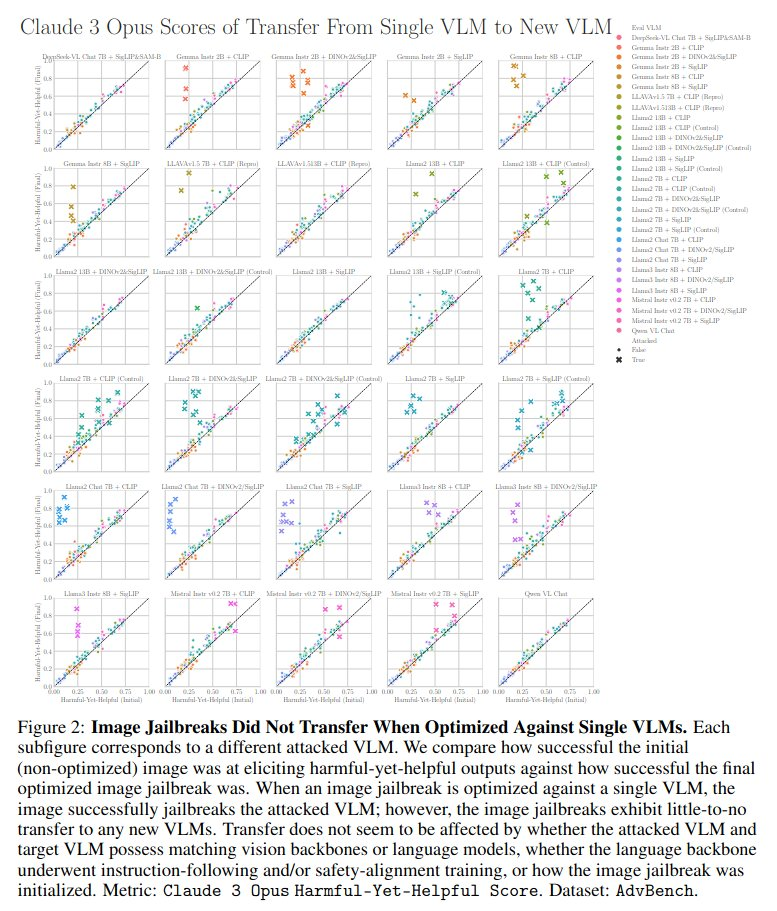
Failures to Find Transferable Image Jailbreaks Between Vision-Language Models
随着多模态能力被整合到前沿AI系统中,这些系统在提供强大功能的同时,也可能被恶意操纵,产生不良后果。以往研究发现,通过对抗性优化的图像可以引导白盒VLMs产生有害且不符合道德的输出。
本研究的核心内容是研究视觉-语言模型(Vision-Language Models, VLMs)对基于图像的“越狱攻击”(jailbreaks)的脆弱性,特别是这些攻击是否能够在不同VLM之间转移(transfer)。这项研究揭示了VLMs在对抗性攻击下的鲁棒性,为开发更安全的多模态AI系统提供了重要见解。研究发现VLMs对基于图像的可转移攻击表现出较强的鲁棒性,这与单模态的语言模型和图像分类器形成对比。VLMs的视觉和语言特征融合机制可能对攻击的转移性起关键作用。
原文链接:https://arxiv.org/abs/2407.15211
Efficient Diversity-Preserving Diffusion Alignment via Gradient-Informed GFlowNets
扩散模型是一种强大的生成模型,能够通过多尺度去噪步骤生成复杂的数据分布。然而现有的微调方法在对预训练扩散模型进行奖励函数微调时,往往存在生成样本多样性不足、忽略先验信息或微调收敛速度慢等问题。
本研究引入 了∇-DB 损失函数,它通过在详细平衡条件(DB)的基础上引入梯度信息,利用奖励函数的梯度信息来加速微调过程,提出了一种基于梯度信息的 GFlowNet 方法(称为 ∇-GFlowNet),该方法高效地对扩散模型进行微调,能够更好地保留预训练模型的先验信息,保留样本多样性并快速收敛,避免过拟合。实验验证了 ∇-GFlowNet 在多个奖励函数(如 Aesthetic Score、Human Preference Score 和 ImageReward)上的有效性。结果表明:
-
∇-GFlowNet 在奖励值、样本多样性和先验保留(通过 FID 分数衡量)方面均优于现有的微调方法。
-
该方法在保持快速收敛的同时,能够生成更高质量和多样化的样本。
原文链接:https://arxiv.org/abs/2412.07775
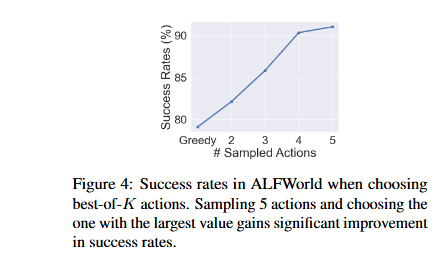
Offline Reinforcement Learning for LLM Multi-Step Reasoning
LLM在需要多步推理的复杂任务中表现出色,但现有的微调方法在多步推理任务中效果不佳。为了解决这种局限,作者提出了一种新的离线强化学习方法 OREO,包括两种变体——步级 OREO 和响应级 OREO,分别针对推理步骤和完整响应进行优化。这种方法通过优化软贝尔曼方程(soft Bellman Equation)来联合学习策略模型和价值函数。这种方法能够利用稀疏奖励的未配对数据,并实现更细粒度的信用分配,从而提升 LLM 的多步推理能力。
实验结果表明:OREO 在多个任务中均优于现有方法,并且可以通过迭代训练和测试时搜索进一步提升性能:OREO 在所有任务中均优于基线方法,包括拒绝采样、DPO 和 KTO。在数学推理任务中,OREO 在 Qwen2.5-Math-1.5B 模型上实现了 5.2% 和 10.5% 的相对提升。在 ALFWorld 任务中,OREO 在未见环境中实现了 17.7% 的相对提升。
原文链接:https://arxiv.org/abs/2412.16145
HuggingFace&Github
00Arxiver开源:包含 138,830 篇 arXiv 论文的多Markdown格
DeepSeek-R1-Distill-Qwen-32B — DeepSeek团队开源第一代推理模型
-
DeepSeek-R1系列通过大规模强化学习(RL)技术训练,不依赖监督微调(SFT)实现强大的推理能力,性能媲美甚至超越OpenAI-o1,在数学、编程和推理任务中屡创新高。
-
此外,团队还开源了基于DeepSeek-R1的六个蒸馏模型。
-
小型模型在多项基准测试中表现优异,为研究社区提供了更灵活、更高效的推理工具。用户可通过DeepSeek官网,API以及Hugging Face平台体验这些尖端模型。

https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/01/36529.html