我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


非常感谢一直以来大家对101文档、llmspace公众号、小红书大模型空间站的喜爱与支持~为了进一步打造高质量的AI社媒账号并且帮助大家链接资源,我们欢迎大家花1分钟来填写【反馈问卷】,一起打造更优质的AI交流平台!

HuggingFace&Github
Zonos-v0.1-hybrid:开放权重文本转语音模型
Zonos-v0.1 是一个开放权重文本转语音模型, 能够根据给定的文本提示生成高度自然的语音。仅需 5 到 30 秒的说话人样本即可实现高保真语音克隆。它还允许根据语速、音调变化、音频质量以及悲伤、恐惧、愤怒、快乐和喜悦等情绪进行调节。该模型以 44kHz 的频率输出语音。
-
零样本TTS与语音克隆:输入所需文本和 10-30 秒的说话人样本,即可生成高质量的文本转语音输出。
-
音频前缀输入:添加文本和音频前缀,实现更丰富的说话者匹配。
-
多语言支持:Zonos v0.1 支持英语、日语、中文、法语和德语。
-
快速:我们的模型在 RTX 4090 上运行时的实时因子约为 2 倍。
-
WebUI Gradio 界面:Zonos 附带一个易于使用的 Gradio 界面来生成语音。
-
简单的安装和部署:只需使用我们存储库中打包的 Docker 文件,即可轻松安装和部署 Zonos。


https://huggingface.co/Zyphra/Zonos-v0.1-hybrid
学习
Is Self-Play RL the Key to Learning-Based Planning?
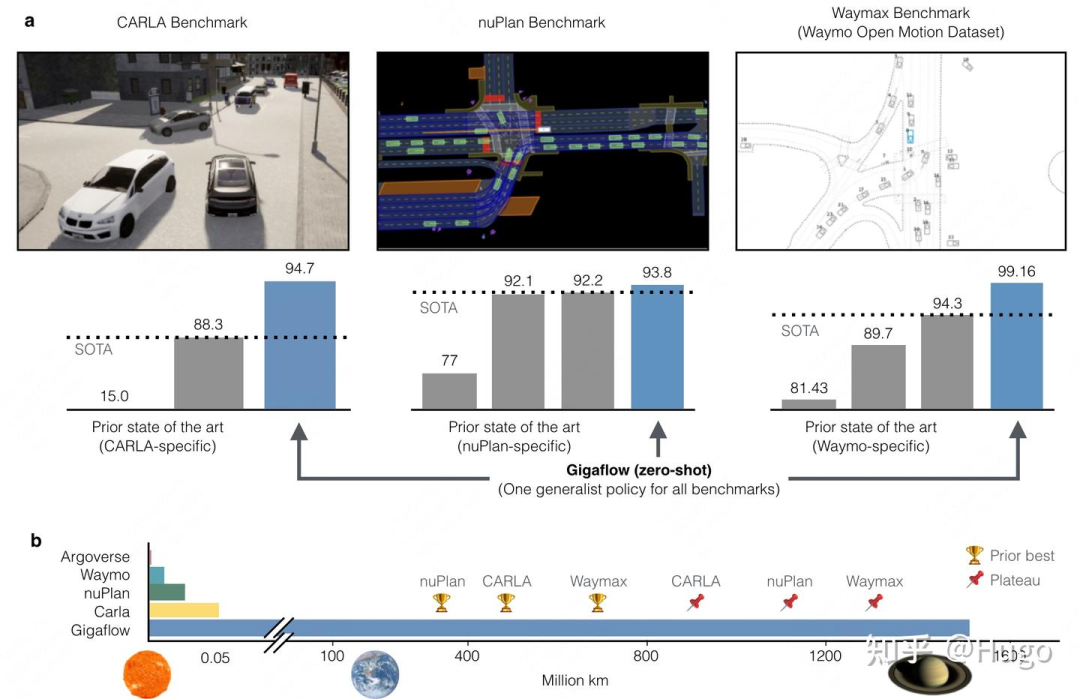
近日,我刷到一篇令人振奋的文章《Robust Autonomy Emerges from Self-Play》。该研究通过采用自我对弈(self-play)强化学习(RL)的方法,使用model-free规划器(Planner),在多个闭环基准测试中取得了令人惊叹的成果,甚至突破了现有的SoTA水平。以下是我对这篇工作的技术分析与看法。
该工作的核心思想是通过自我对弈RL生成无限的训练数据,不断优化模型。尤其是在nuPlan、CARLA、Waymax等闭环环境中,测试结果显示该方法不仅突破了PDM(之前23年冠军算法)所设的性能瓶颈,而且达到近乎完美的表现。传统上,hybrid方案(结合了规则和学习方法)往往需要在输出多个轨迹后,使用像PDM的评价函数进行搜索优化,但这些方法效果上并没有超越基于规则的Bot-Drive算法。而该工作展示了在无监督学习的框架下,如何通过RL自我对弈完成类似任务,甚至取得更高水平的性能。
文章中,系统使用了名为Gigaflow的仿真器,其核心特点是能够高效并行地进行大量场景仿真。8卡A100 GPU可以同时仿真38400个场景,且每个场景最多包含150个agent,仿真效率极高。通过对动作空间的离散化,结合前向运动学模型,模型能从速度、位置等信息中推断出合理的动作。特别地,reward的设计采用了随机参数化的策略,增强了训练过程中的多样性和鲁棒性。
为了提高训练效率,系统采用了PPO和GAE等强化学习算法,且使用了优先经验回放(Advantage Filter)来筛选有效数据。这种做法大幅提升了训练速度,特别是在庞大的仿真数据下,能有效减少低效数据的干扰。实验表明,通过这种大规模的数据训练,所生成的model-free Planner能够在多个真实环境中进行零-shot迁移,并且实现了接近0%的故障率。
该研究的最大创新之一是它强调了reward设计和领域随机化(domain randomization)的重要性。通过这种方式,模型能够学习到各种不同的驾驶行为,增强了其在实际环境中的鲁棒性。此外,随着训练步骤的增多,系统逐渐能够处理复杂的交通场景并执行长时间预测和决策。
总结来看,这篇工作表明通过自我对弈强化学习,结合合理的reward设计和大量的仿真数据,可以极大提升自动驾驶系统的鲁棒性和决策能力。强化学习通过模拟实际驾驶场景的状态-动作对,促使模型学习到均衡策略,并泛化到未见的测试场景中,从而为自动驾驶技术的进一步发展开辟了新道路。
https://zhuanlan.zhihu.com/p/22350404499
NPU的核心-加速阵列设计详解
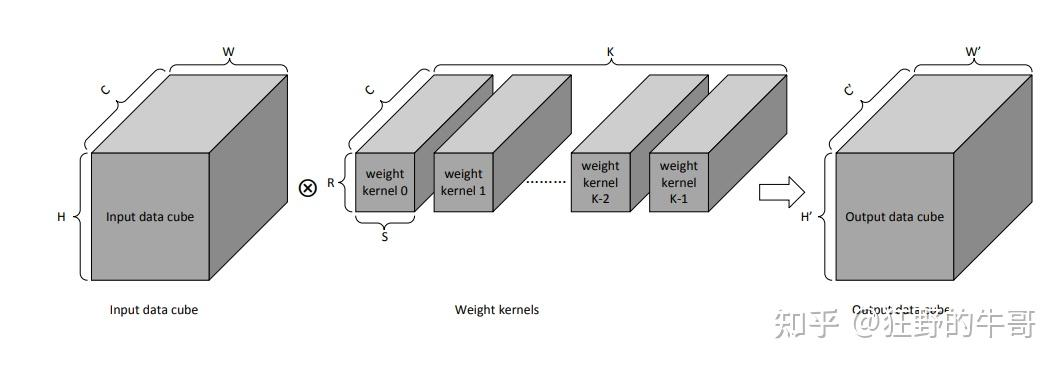
随着AI的迅猛发展,NPU(神经网络处理单元)成为硬件加速领域的重要突破之一。与CPU和GPU相比,NPU的设计较为简单,属于专用计算架构(DSA)范畴,常见的包括Google的TPU、NVIDIA的NVDLA、华为的昇腾等。这些NPU的核心部分都是硬件运算加速阵列,旨在加速卷积和GEMM(矩阵乘法)运算,从而提升AI模型的训练和推理效率。
在硬件加速阵列的设计中,最重要的是并行度的实现。卷积操作可以通过并行计算将传统的串行计算转换为高效的并行计算,从而加速处理过程。NVDLA、TPU和华为达芬奇的设计各自采取了不同的并行策略。
NVDLA的加速阵列通过Atomic_K×Atomic_C的二维乘法单元,结合权重寄存器、特征寄存器和累加器进行逐步计算。计算时,通过逐个cell_col加载和广播特征数据,在硬件上进行并行计算。其优点是设计简单,但由于大规模阵列启动时会产生瞬时电流冲击,能效较低。
TPU则采用了渐进式启动的“脉动阵列”控制方式。与NVDLA的全员启动方式不同,TPU通过逐步启动每个cell,减少了电流冲击,并优化了能效。其控制逻辑较为复杂,但通过精细化控制,能够在大规模阵列中实现更高效的计算。
华为的达芬奇架构则引入了三维立方体的加速阵列设计(cube),并在PK、PC和PE三个维度上进行并行计算。这种设计能够在特定情况下提供更高效的计算,特别是在处理小K和小C的卷积时,优势更加明显。虽然其ACC group的存储需求较高,但能够减少PK和PC维度的负担,提升在特定场景下的计算性能。
在卷积和GEMM的计算之间,卷积计算可以转化为矩阵运算(GEMM),通过额外的存储空间将输入的特征和卷积核展开为矩阵,从而利用矩阵乘法加速计算。虽然这意味着需要重复存储,但可以利用现有的加速阵列设计实现高效的矩阵乘法运算,尤其适合大型矩阵运算任务。
总的来说,NVDLA、TPU和华为达芬奇的加速阵列各有优劣,选择合适的设计需要根据实际应用的需求来决定。在硬件加速领域,未来的发展将可能侧重于如何在不断变化的计算任务中寻找到最优的平衡点,以应对大规模模型的挑战。
https://zhuanlan.zhihu.com/p/22537704473
万字长文总结多模态大模型评估最新进展
随着多模态大模型(MLLMs)在人工智能领域的广泛应用,如何全面、有效地评估这些模型的能力逐渐成为一个重要议题。传统的单一任务评估方法已无法满足多模态模型的复杂性和多样性需求,亟需开发一个系统化的评估框架。近期,多个研究团队提出了针对MLLMs的评估综述,包括MME-Team、MMBench Team以及LLaVA团队等,他们的工作旨在为研究人员提供系统的评估指南,帮助快速识别合适的评估工具,并促使更能反映模型优缺点的评估方法的创新。
文章首先提出了一种分层分类法,将现有的基准测试分为三类:基础能力、模型行为分析和扩展应用。在基础能力的评估方面,VQA v2和MME等基准通过全面测试模型的视觉常识任务,帮助评估其推理和理解能力。文中还介绍了包括OCR、图表理解、数学推理等多领域基准,展示了MLLMs在不同子任务中的表现,并强调了其在细粒度感知任务和复杂文档理解中的挑战。
在模型行为分析方面,评估的重点包括“幻觉”现象(模型输出与实际视觉内容不一致)、模型偏见(如年龄、性别偏见)和安全性(如分布外鲁棒性、对抗攻击等)。例如,VLBiasBench揭示了开源与闭源模型在社会偏见上的差异,而MultiTrust则测试了模型在越狱攻击下的安全性。当前的评估表明,尽管闭源模型通常表现较好,但MLLMs仍面临显著的安全隐患和鲁棒性问题。
扩展应用方面,MLLMs在医学、情感分析、遥感等领域的应用能力逐渐受到关注。在医学图像分析方面,尽管现有模型在处理医学任务时的表现未必理想,但通过专门微调,MLLMs的表现可与专业模型媲美。在情感分析中,经过领域特定微调的模型明显优于零样本模型,表明领域知识的注入对于提升性能至关重要。此外,基于遥感图像的评估显示,MLLMs在特定领域任务中的表现逐渐超越传统模型,展现出在解决实际问题中的巨大潜力。
总的来说,当前的评估框架仍然面临许多挑战,尤其是在处理长视频、细粒度感知等任务时。未来的研究方向将聚焦于能力导向评估、任务导向评估以及多模态整合等领域,旨在进一步提升评估方法的准确性和实用性。

https://zhuanlan.zhihu.com/p/16815782175
LLM Pretrain Data Project
随着从初期的代码预训练到现在的通用预训练,数据的重要性愈发显著,特别是对于深度学习的核心作用不容忽视。数据的质量与处理方式直接影响模型的性能和泛化能力。企业级的基础模型要求考虑多个维度,尤其是在训练时达到10T token的规模时,如何保证长尾知识的覆盖和多样性。模型是否能高效地处理特定的推理任务,取决于数据的丰富性与精准度,特别是在base能力不足的情况下,如何通过退火和强化学习等技术优化训练过程。
对于数据的处理,特别是合成数据的使用,必须谨慎。格式化的数据(如PPL、Markdown等)对模型的损失函数有极大的影响,合成数据的PPL普遍较低,并且其N-grams特征和真实数据差异较大。尤其是在QA数据的预训练阶段,模型的增益会随着规模扩大而逐渐减少,因此合成数据的使用需要更加严格的验证。特别是B级别的改写数据,必须考虑其验证过程,以避免不合格数据的影响。
当模型训练到一定规模时,竞争的焦点转向了数据解析和文本特征的处理。HTML到文本的解析成为大模型训练中的瓶颈,特别是针对代码和推理任务,必须使用专门的提取流水线进行处理。许多大模型如Llama3.1和Nemotron-CC,已经在HTML解析上投入大量资源,使用了定制的提取和文本过滤技术,以应对代码和数学领域的特殊需求。
模型基于的技术方法,如fastText,被用于高质量数据的召回,尤其是在代码和数学领域。通过多轮召回,生成大量的相关数据,并通过人工标注不断扩充种子池,最终获得了极具价值的数据集。例如,DeepSeek通过这种方式召回了120B数学相关网页,而Mistral公司则用类似的策略召回了70B代码相关tokens。Qwen2.5模型也在数据清洗过程中取得了突破,采用了更为复杂的评估方法,使得低质量数据的过滤更加有效。
对于高质量数据的处理,不仅是筛选,更是通过如token-level的编辑和重生等技术,解决了合成数据所面临的困惑度问题。此外,模型训练中的各种策略,如数据增强与训练数据的多样性调整,也在不断优化着模型的预训练效果。总体而言,深度学习模型的表现不仅依赖于数据的量,更在于数据的质量和处理技术。

https://zhuanlan.zhihu.com/p/22520117646
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/02/38144.html
