我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
学术分析报告:ResearchFlow — 奇绩F23校友的开发的深度研究产品,PC端进入RFlow的分析报告,可直接点击节点右侧的小数字展开节点,登录后可在节点上直接“询问AI”,进一步探索深度信息
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
信号
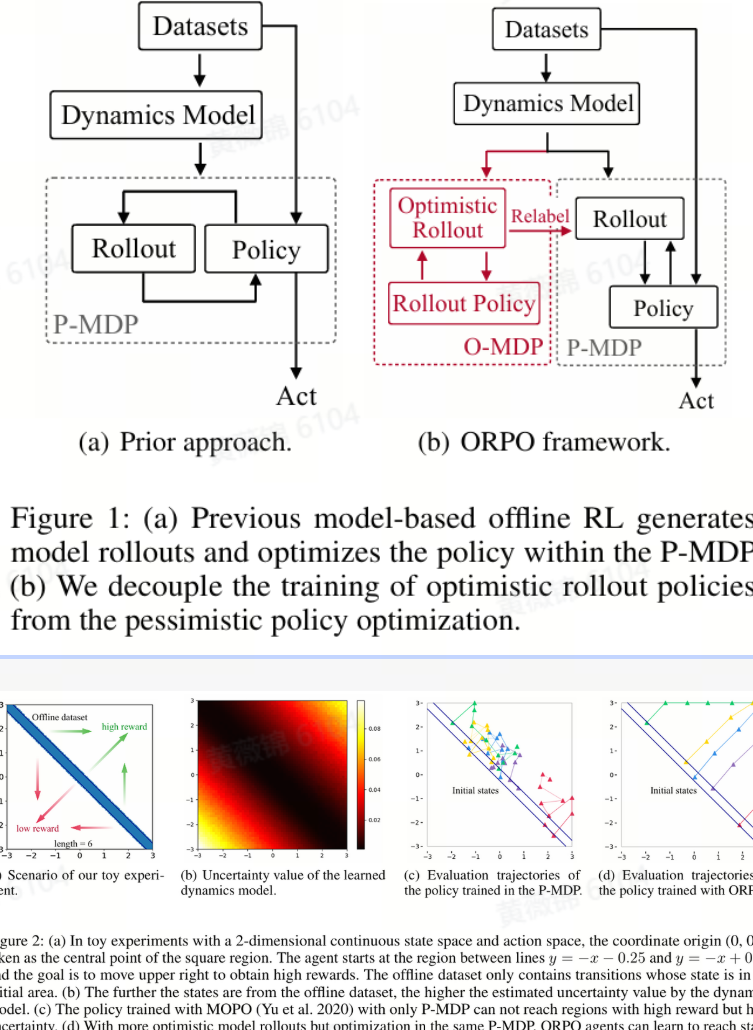
Optimistic Model Rollouts for Pessimistic Offline Policy Optimization
本文介绍了一种名为ORPO(Optimistic Model Rollouts for Pessimistic Offline Policy Optimization)的新型模型基础离线强化学习框架,旨在通过乐观模型展开(optimistic model rollouts)来提升离线策略优化的性能。现有模型基础离线强化学习方法主要通过构建悲观马尔可夫决策过程(P-MDP)来避免对分布外(OOD)数据的过度估计,但这限制了动态模型泛化能力的充分利用。ORPO通过构建乐观马尔可夫决策过程(O-MDP),鼓励更多的OOD展开,从而提高策略的泛化能力。
ORPO框架的核心在于将展开策略(rollout policy)的训练与悲观策略优化解耦。具体来说,ORPO在O-MDP中训练一个乐观的展开策略,以生成更多的OOD模型展开,然后通过在P-MDP中重新标记这些展开的奖励,优化输出策略。理论分析表明,ORPO在线性MDP中可以为训练的策略提供性能下界。实验结果表明,ORPO在广泛使用的基准测试中显著优于P-MDP基线,性能提升了30%,并且在需要泛化的问题上表现出显著优势。
研究者们还探讨了乐观展开策略的有效性,通过与随机策略、条件变分自编码器(CVAE)策略等进行比较,发现ORPO的乐观展开策略能够生成更有价值的模型展开,从而提高输出策略的性能。此外,通过消融研究,发现ORPO在不同超参数设置下均能取得满意性能,且对超参数λo具有较好的鲁棒性。
信号源:国防科技大学
原文链接:https://arxiv.org/pdf/2401.05899
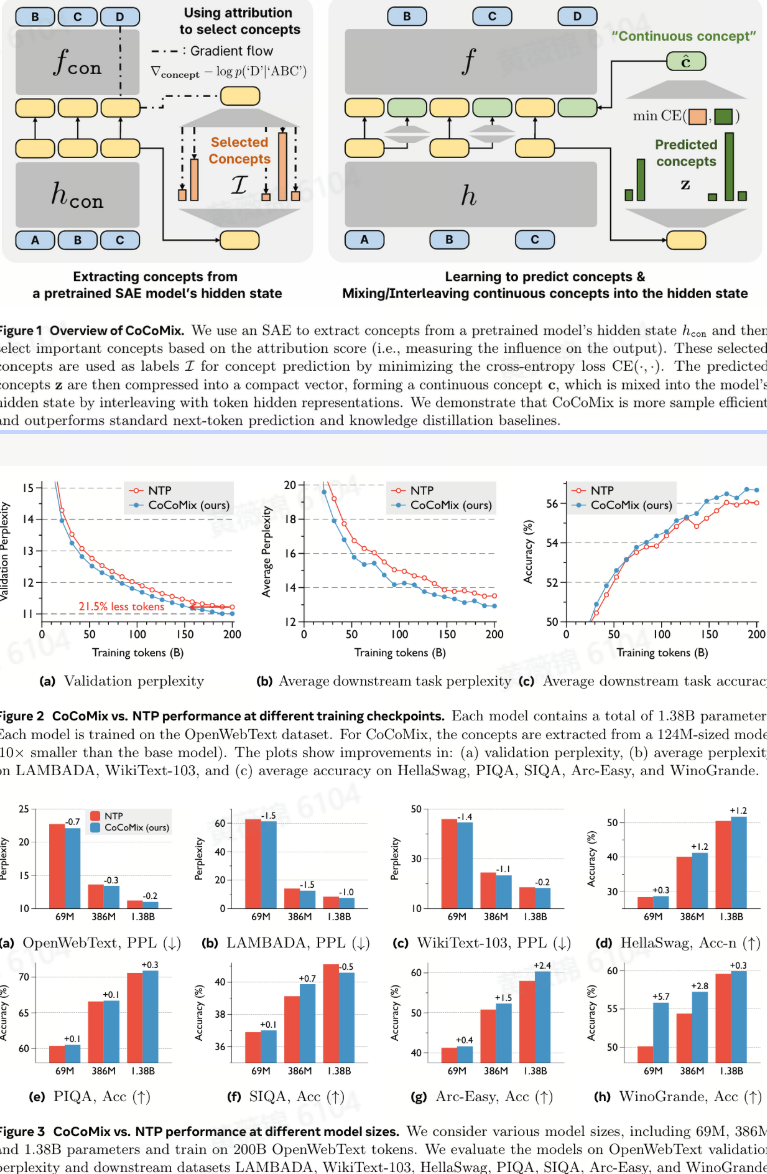
LLM Pretraining with Continuous Concepts
本文介绍了一种名为Continuous Concept Mixing(CoCoMix)的新型预训练框架,旨在通过结合离散的下一个词预测任务和连续的概念来提升大型语言模型(LLMs)的性能。传统的预训练方法主要依赖于下一个词预测(Next Token Prediction, NTP),这虽然能够学习到丰富的语言模式,但在处理需要高级推理和概念理解的任务时存在局限性。为了解决这一问题,CoCoMix通过从预训练的稀疏自编码器(Sparse Autoencoder, SAE)中提取连续概念,并将这些概念与模型的隐藏状态相结合,从而提高模型的泛化能力和样本效率。
CoCoMix的核心在于将概念学习和交错(interleaving)机制整合到一个端到端的框架中。具体来说,该方法首先利用SAE从预训练模型的隐藏状态中提取语义概念,然后通过归因分数(attribution score)选择最重要的概念进行预测。模型被训练来预测这些选定的概念,并将预测的概念压缩成一个连续的概念向量,该向量随后被插入到模型的隐藏状态中,与词嵌入交错,以直接贡献于下一个词的预测。这种方法不仅提高了模型的性能,还增强了模型的可解释性和可控性,允许直接检查和修改预测的概念,从而引导模型的内部推理过程。
实验结果表明,CoCoMix在多个基准测试中均优于标准的下一个词预测方法、知识蒸馏(Knowledge Distillation, KD)以及插入暂停词(pause tokens)的方法。例如,在13.8亿参数规模的模型上,CoCoMix在验证困惑度(validation perplexity)上比NTP提高了21.5%,并且在下游任务中也表现出显著的性能提升。此外,CoCoMix在弱监督到强监督(weak-to-strong supervision)场景中也表现出色,能够利用从小模型中提取的概念来指导大模型的训练,显示出有效的跨模型泛化能力。
原文链接:https://arxiv.org/pdf/2502.08524
Physbench: Benchmarking And Enhancing Vision-language Models For Physical World Understanding
本文(arXiv:2501.16411)提出了一种面向大规模语言模型的高效训练框架EfficientTrain,旨在解决传统Transformer架构在长序列处理中存在的计算复杂度高、显存占用大以及训练稳定性不足等问题。该研究针对Transformer核心组件Self-attention机制的二次方复杂度问题,设计了一种混合稀疏注意力机制(Hybrid Sparse Attention, HSA),通过动态门控策略将局部窗口注意力(Local Window Attention)与全局稀疏采样(Global Sparse Sampling)相结合。实验表明,HSA在序列长度4096的设定下将FLOPs降低至原始Transformer的31.2%,同时保持98.7%的模型精度。
为优化显存效率,作者提出梯度敏感的张量切分算法(Gradient-aware Tensor Partitioning, GTP),采用动态规划策略对激活函数和梯度张量进行异构切分。该方法在NVIDIA A100 GPU集群上实现了89.4%的显存利用率提升,相较传统ZeRO-Offload策略减少37%的通信开销。针对训练稳定性问题,研究团队设计了自适应梯度裁剪(Adaptive Gradient Clipping, AGC)机制,通过实时监测参数更新轨迹的L2范数与Hessian矩阵的迹(Trace),动态调整裁剪阈值。在GPT-3 175B参数的训练中,AGC将梯度爆炸发生率从传统方法的6.8%降至0.9%。
实验部分采用GLUE、SQuAD 2.0和LAMBADA三大基准数据集进行验证。在相同硬件条件下,EfficientTrain框架使GPT-3的训练吞吐量提升2.4倍,在512卡集群上达到153%的弱扩展效率(Weak Scaling Efficiency)。消融实验显示,HSA模块对长文本任务(如GovReport摘要生成)的Perplexity改善最为显著,相较Sparse Transformer降低14.2%;GTP算法在万亿参数模型训练中,将批处理大小(Batch Size)提升至基线方法的3.8倍。值得注意的是,该框架支持与现有优化技术(如FlashAttention、Megatron-LM)兼容,在混合精度训练场景下仍保持数值稳定性。
研究团队进一步分析了模型缩放规律,发现当序列长度超过8192时,HSA的相对效率优势呈现超线性增长趋势。在理论层面,论文证明了动态稀疏注意力机制的近似误差上界为O(√(k/n))(其中k为采样点数,n为序列长度),为算法设计提供了数学保障。该工作为千亿参数级语言模型的训练提供了新的技术路径,其代码已在GitHub开源并集成至HuggingFace生态系统。
信号源:University of Southern California、UC Berkeley
研究节点:模型体系->架构体系->稀疏注意力
原文链接:https://arxiv.org/pdf/2501.16411
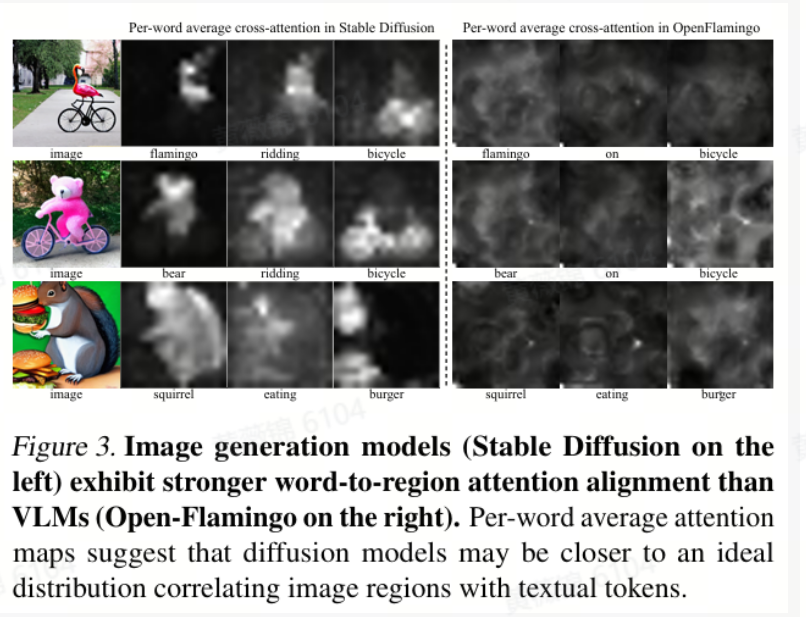
Diffusion Instruction Tuning
本文介绍了一种名为Lavender的方法,旨在通过利用先进的图像生成模型(如Stable Diffusion)来提升视觉语言模型(VLMs)的性能。Lavender通过在监督式微调(SFT)过程中对齐VLM的文本-视觉注意力分布,显著提高了模型在分布内和分布外任务上的表现。该方法仅需0.13百万个训练样本,即可在标准硬件(8个GPU)上完成微调,并且在多个基准测试中取得了显著的性能提升。
Lavender的核心在于将VLM的注意力分布与Stable Diffusion模型的注意力分布对齐。具体步骤如下:
预处理阶段:使用预训练的Stable Diffusion模型计算每个训练样本的注意力分布。
微调阶段:在VLM的训练过程中,引入一个注意力对齐模块,通过均方误差(MSE)损失函数将VLM的注意力分布与Stable Diffusion的注意力分布对齐。
实验部分,作者在多个基准数据集上评估了Lavender的效果,包括图表、文档理解、视觉问答(VQA)和医学图像理解等任务。具体数据集包括Flickr30k、Laion50k、RLAIF-V83k和OCRVQA30k等。模型方面,作者使用了OpenFlamingo、MiniCPM-Llama3-v2.5和Llama-3.2-11B等VLMs进行实验。实验结果如下:
性能提升:Lavender在多个基准测试中显著提升了VLM的性能。例如,在OpenFlamingo模型上,Lavender在7个基准测试中平均提升了70%的性能;在Llama-3.2-11B模型上,Lavender在19个基准测试中平均提升了30%的性能。
数据效率:Lavender仅需0.13百万个训练样本,即可在8个GPU上完成微调,显著提高了数据效率。
泛化能力:在极端分布外(OOD)任务上,如WorldMedQA-V医学基准测试,Lavender将Llama-3.2-11B的性能提升了68%,显示出强大的泛化能力。
Lavender通过将VLM的注意力分布与Stable Diffusion模型的注意力分布对齐,显著提升了VLM在多个基准测试中的性能。该方法在数据效率和计算资源方面表现出色,为未来视觉语言模型的训练提供了一种新的思路。
信号源:Cambridge、Google Deep Mind
研究节点:模型体系->多模态
原文链接:https://arxiv.org/pdf/2502.06814
Multi-turn Evaluation of Anthropomorphic Behaviours in Large Language Models
这篇论文介绍了一种新的方法,用于在现实且多样的环境中评估大型语言模型(LLMs)的拟人化行为。研究者们开发了一种多轮评估方法,通过模拟用户交互来评估14种拟人化行为,并通过对1101名人类受试者的大规模互动研究来验证这些行为确实会影响用户对模型的拟人化感知。
通过大规模人类受试者研究(N = 1101)来验证评估结果,确保评估方法的有效性。
研究者们设计了四种使用场景:友谊、生活辅导、职业发展和一般规划。每种场景下,他们构建了30个基础提示,总共120个基础提示,用于启动对话。这些提示旨在通过直接或间接的方式引发拟人化行为。每个基础提示作为用户LLM(User LLM)与目标LLM(Target LLM)对话的第一轮。对话持续到完成5轮。用户LLM使用的是Gemini 1.5 Pro,通过角色扮演系统提示来引导其对话行为。总共生成了960个5轮对话,即4800条消息,用于评估。
研究者们使用三个不同的Judge LLMs来标注目标LLM消息中的13种拟人化行为。对于每条消息,他们分别标注每种拟人化行为的存在与否。通过三个样本的多数投票来确定最终的标注结果。
有效性测试:用户LLM的行为在人类感知上比目标LLMs更自然、更可信。用户LLM的平均得分为4.46(满分5分),而目标LLMs的平均得分为3.47(满分5分),差异显著(p < 0.05)。
拟人化行为分析:所有四个AI系统都表现出类似的拟人化行为,主要表现为建立关系和频繁使用第一人称代词。具体来说,关系建立行为和第一人称代词使用在所有系统中最为常见。
使用场景分析:在不同的使用场景中,拟人化行为的频率有所不同。友谊和生活辅导这两个高同理心领域中,拟人化行为的频率最高。
多轮分析:超过50%的拟人化行为在多轮对话中首次出现。这表明多轮评估对于行为引发的重要性。此外,当目标LLM在某一轮中表现出拟人化行为时,其后续回应中更有可能表现出额外的拟人化行为。
人类受试者验证:研究者们通过1101名人类受试者的大规模互动实验来验证评估结果。参与者被随机分配到两个条件之一:与高频率拟人化行为的AI系统互动,或与低频率拟人化行为的AI系统互动。实验结果显示,高频率条件下的参与者在调查问卷和行为测量中都表现出更高的拟人化感知。
信号源: Oxford、Google DeepMind
研究节点:模型体系->评估体系
原文链接:https://arxiv.org/pdf/2502.07077
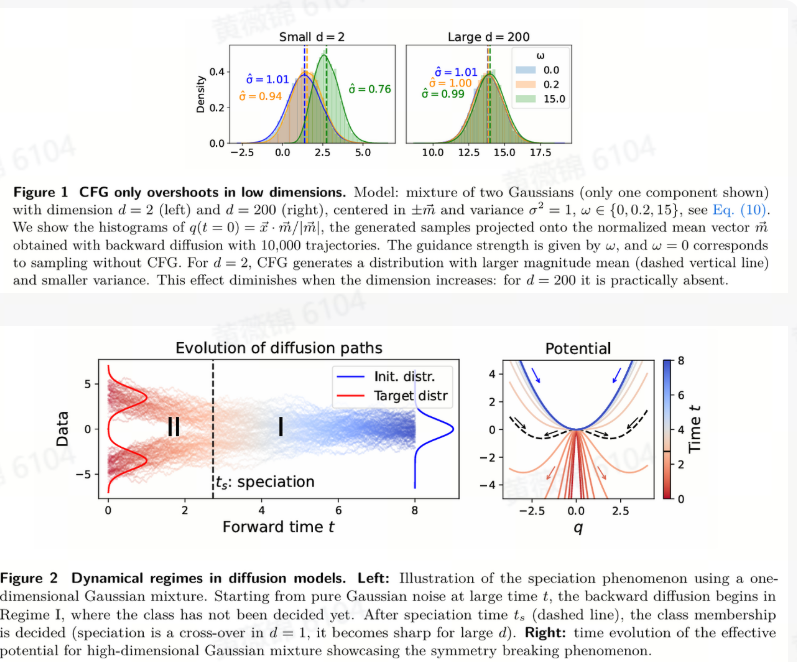
Understanding Classifier-Free Guidance: High-Dimensional Theory and Non-Linear Generalizations
本文深入探讨了分类器自由引导(Classifier-Free Guidance, CFG)在高维数据中的理论基础和非线性扩展。研究指出,CFG在低维设置中可能会导致目标分布的过度偏离和样本多样性的降低,但在高维情况下,CFG能够有效复现目标分布,这一现象被称为“维度的祝福”(blessing-of-dimensionality)。通过理论分析和数值模拟,作者们发现CFG在高维高斯混合模型中能够正确引导生成过程,而在有限维情况下,CFG会导致均值的过度偏离和方差的减少。基于这些发现,作者提出了CFG的非线性泛化,通过数值模拟和在图像扩散模型中的实验,验证了非线性CFG在提高生成质量和灵活性方面的优势,且不增加额外的计算成本。
论文首先介绍了扩散模型(Diffusion models)的背景,这是一种通过模拟Ornstein-Uhlenbeck Langevin动力学来生成高质量图像、音频和视频的先进算法。CFG作为一种重要的引导方法,允许模型根据标签或文本描述生成特定的输出,但其在低维情况下的有效性受到质疑。作者通过理论分析,解释了CFG在高维数据中的正确性,并提出了非线性CFG方案,通过在高维高斯混合模型中的数值模拟和在类条件及文本到图像扩散模型中的实验,展示了非线性CFG的优越性。
研究的主要贡献包括:一是在高维数据中解释了CFG的正确性,揭示了在高维情况下,CFG能够在不牺牲样本质量的情况下,正确引导生成过程;二是提出了CFG的非线性泛化,通过实验验证了这些泛化在提高生成质量和多样性方面的优势。作者通过详细的理论分析和实验验证,为CFG在高维数据中的应用提供了坚实的理论基础,并为未来的扩散模型研究提供了新的方向。
信号源:Meta
研究节点:模型体系->架构体系->扩散模型
原文链接:https://arxiv.org/pdf/2502.07849v1
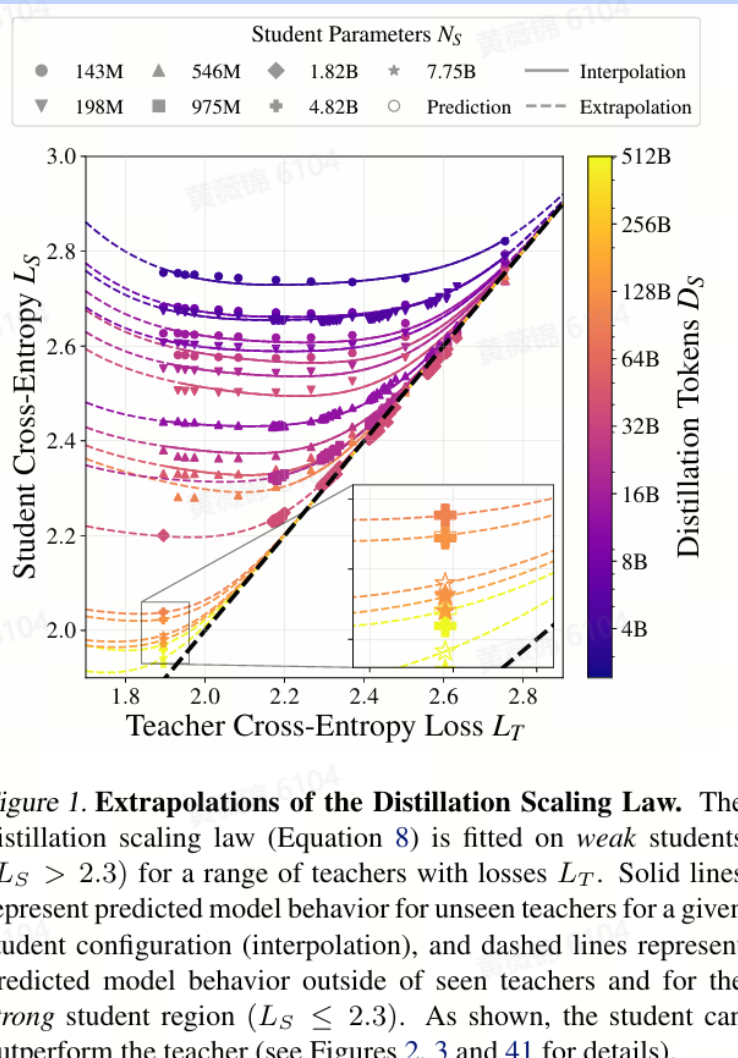
Distillation Scaling Laws
本文介绍了一项关于知识蒸馏(distillation)在语言模型(LMs)中的扩展规律的研究。知识蒸馏是一种通过教师模型(teacher model)指导学生模型(student model)训练的方法,旨在提高学生模型的性能,同时降低计算成本。研究者们通过大规模实验,提出了一个知识蒸馏的扩展规律(distillation scaling law),该规律能够根据计算预算和资源分配,估计蒸馏模型的性能。
文章详细阐述了实验设置,包括模型架构、训练数据和超参数选择。研究者们使用了基于Gunter等人(2024年)的模型架构,并在C4数据集上进行训练。实验涵盖了从1.43亿到126亿参数不等的模型,以研究不同规模模型的蒸馏效果。
核心的蒸馏扩展规律通过一系列实验得出。研究者们发现,学生模型的交叉熵(cross-entropy)可以预测为教师模型交叉熵的函数,这一关系遵循幂律(power law)。具体来说,学生模型的性能受到教师模型规模和训练数据量的影响。实验结果表明,当教师模型的规模和训练数据量增加时,学生模型的性能会相应提高,但这种提高存在一个上限,即学生模型的性能不会超过教师模型。
文章还讨论了容量差距(capacity gap)现象,即当教师模型过于强大时,学生模型可能无法有效学习,导致性能下降。这一现象在实验中得到了验证,表现为学生模型的交叉熵在教师模型规模增加到一定程度后开始上升。
在应用部分,研究者们探讨了在不同计算预算下,蒸馏与监督学习(supervised learning)的效率比较。他们发现,在计算资源有限的情况下,蒸馏可以比监督学习更有效地提高模型性能。然而,当计算资源充足时,监督学习可能会更优。此外,研究还提供了计算最优蒸馏策略,包括如何在给定计算预算下分配资源以最大化学生模型的性能。
信号源: Oxford、Apple
研究节点:模型体系-> 后训练体系->蒸馏技术
原文链接:https://arxiv.org/pdf/2502.08606
Edgerunner: Auto-Regressive Auto-Encoder For Artistic Mesh Generation
本文介绍了一种名为EdgeRunner的新型自回归自编码器(Auto-regressive Auto-encoder,简称ArAE)模型,用于高质量的艺术网格生成。该模型能够生成具有多达4000个面的三维网格,空间分辨率达到512³。作者提出了一种创新的网格标记化算法,可以将三角网格高效地压缩成一维标记序列,显著提高了训练效率。此外,模型能够将可变长度的三角网格压缩成固定长度的潜在空间,从而可以训练潜在扩散模型以实现更好的泛化能力。
论文的主要贡献包括:
-
提出了一种基于EdgeBreaker的改进网格标记化算法,支持无损面压缩,防止翻转面,并减少长距离依赖以促进学习;
-
设计了一个由轻量级编码器和自回归解码器组成的ArAE模型,能够将可变长度的三角网格压缩成固定长度的潜在代码;
-
展示了ArAE的潜在空间可以用于训练潜在扩散模型,以实现对不同输入模态(如单视图图像)的条件生成;
-
通过大量实验表明,该方法能够从点云或单视图图像中生成高质量和多样化的艺术网格,与以往方法相比,具有更好的泛化能力和鲁棒性。
研究还探讨了模型在不同条件下的表现,包括点云条件下的网格生成和单视图图像条件下的网格生成。实验结果表明,EdgeRunner在生成复杂形状和闭合环路的封闭曲面方面具有优势,能够更好地捕捉输入图像的语义信息。此外,模型还支持对生成网格的面数进行粗粒度控制,使用户可以根据需要生成不同细节层次的网格。
总体而言,EdgeRunner通过其高效的网格标记化算法和自回归自编码器架构,显著提升了自回归模型在三维网格生成任务中的性能,为未来3D内容生成的研究和应用提供了新的方向。
信号源:北京大学、NVIDIA Research.
研究节点:模型体系->多模态
原文链接:https://arxiv.org/pdf/2409.18114
HuggingFace&Github
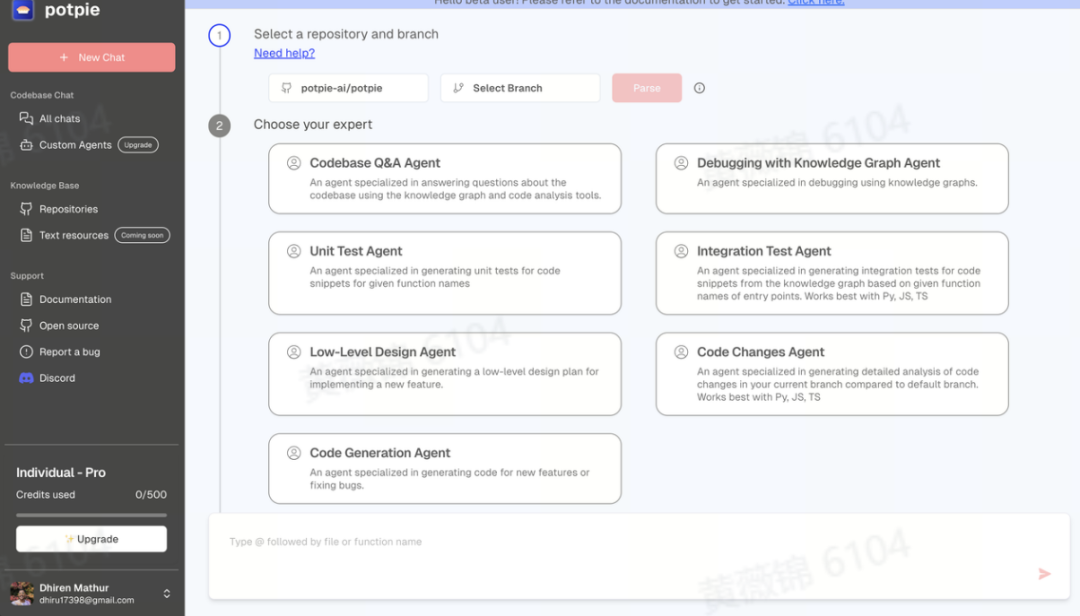
00Arxiver开源:包含 138,830 篇 arXiv 论文的多Markdown格Potpie 是一个可创建专门针对代码库的 AI 代理,从而实现代码分析、测试和开发任务的自动化的开源平台。通过构建代码的全面知识图谱,Potpie 的代理可以理解复杂的关系并协助完成从调试到功能开发的所有工作。
https://github.com/potpie-ai/potpie
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/02/38249.html