
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。


学习
关于长推理(R1系列)模型应用于传统文本分类任务的探索
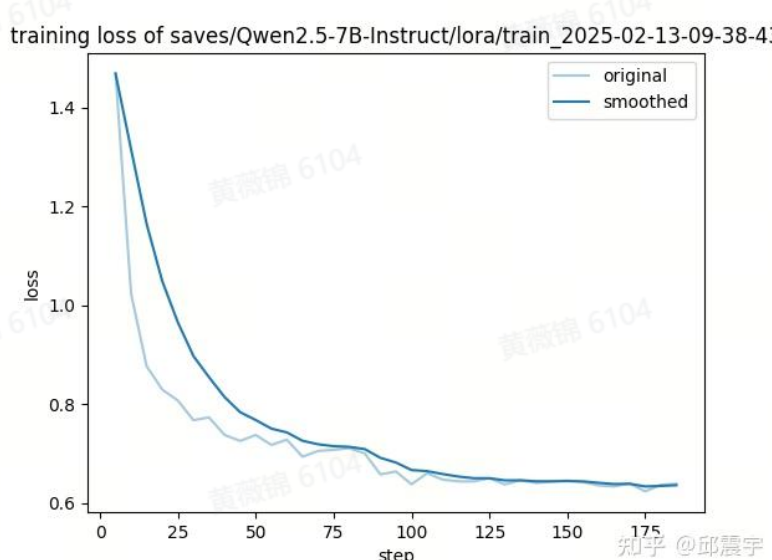
近期,DeepSeek的R1模型成为研究热点,许多机构致力于其私有化部署、复现以及在Agent、搜索等任务中的应用。本文专注于传统文本分类任务,探讨R1系列长推理模型相比传统大模型的效果提升,并分析其是否能替代现有模型。实验基于iFLYTEK和Tnews数据集,对比了DeepSeek-R1蒸馏模型与Qwen模型在相同参数量下的表现,以及基于长思考推理数据微调的效果。
实验一比较了R1蒸馏模型与Qwen模型在零样本(zero-shot)条件下的准确率。结果显示,R1蒸馏模型的整体效果不如经过指令微调和RLHF优化的Qwen模型。例如,在iFLYTEK数据集上,R1-distill-32B的准确率为0.452,而Qwen-2.5-32B-instruct为0.472。分析认为,R1蒸馏模型在长推理能力上有显著提升,但在通用任务上表现稍逊一筹。
实验二探讨了基于长思考推理数据微调的效果。原计划使用满血R1生成数据,但受限于成本和资源,最终采用R1-distill-32B和QWQ-32B生成数据,并对5000条采样数据进行微调。结果显示,长思考推理数据微调后的模型在iFLYTEK验证集上的准确率为0.474,低于普通指令微调数据的0.586。分析发现,长思考推理模型在分析过程中容易“想太多”,导致错过正确答案。例如,对于一款便民服务平台的新闻,模型最终将其归类为“综合预定”,而非更准确的“社区服务”。
此外,实验还发现部分长思考推理模型的错误答案实际上反映了其全面思考的优点。例如,对于一款教育平台的新闻,模型给出的“教辅”标签比标准答案“中小学”更具概括性。在训练过程中,长思考推理数据的训练损失更高,推测是由于其输出的token数量更多。
小结指出,长思考推理模型在传统文本分类任务中并未展现出明显优势,其推理链较长,导致生成速度变慢。同时,由于数据质量和训练步数的限制,实验结论尚需进一步验证。例如,使用满血R1生成的数据可能会带来更好的效果,但具体提升幅度仍不确定。
https://zhuanlan.zhihu.com/p/23462899050
deepseek r1完全满血版如何本地部署?
目前网上关于 DeepSeek R1 的本地部署大多是基于 Ollama 的阉割版,而完全满血版的本地部署需求较高,尤其是对于大规模模型的推理优化。近期,KTransformers 项目团队在 LocalLLaMA 社区发布了支持 DeepSeek R1/V3 模型的部署工具,支持 671B int4 和 int8 量化,并在单 GPU 或多 GPU 环境下实现了显著的加速效果。
KTransformers 是一个灵活的 Python 框架,专注于本地部署优化,尤其适合资源受限的环境。它支持 CPU/GPU 异构计算,能够通过简单的代码注入实现模型优化。例如,V0.2 版本可以在单 GPU(24GB VRAM)或多 GPU 环境下实现高达 14 tokens/s 的推理速度,而即将发布的 V0.3 版本预览版能够达到 286 tokens/s 的 prefill 速度,相比 llama.cpp 提升了 28 倍。
部署 DeepSeek R1 完全满血版的具体步骤如下:
-
克隆 KTransformers 仓库:
-
bash复制
git clone https://github.com/kvcache-ai/ktransformers.git
cd ktransformers
git submodule init
git submodule update
-
安装依赖并编译:
-
bash复制
export USE_NUMA=1make dev_install 或运行 sh ./install.sh
-
启动模型推理:
-
bash复制
python ./ktransformers/local_chat.py --model_path <your_model_path> --gguf_path <your_gguf_path> --prompt_file <your_prompt_file> --cpu_infer 65 --max_new_tokens 1000
-
其中,
--cpu_infer参数用于指定 CPU 推理的线程数,--max_new_tokens用于设置生成的最大新 token 数量。
KTransformers 通过 YAML 模板实现模块替换,支持将原始 PyTorch 模块替换为优化后的模块,例如使用 Marlin 的 4-bit 量化内核。此外,该项目还提供了 RESTful API 和 Web UI,方便用户通过简单的命令启动服务。
目前,KTransformers 社区反馈积极,用户已成功在不同硬件配置下复现优化效果。例如,有用户在单 socket 环境下实现了 10 tokens/s 的推理速度,而多 socket 环境下则需启用 libnuma 支持以达到更高性能。
对于希望在双服务器(16 张 H800 或 A800)上部署 DeepSeek R1 的用户,KTransformers 提供了详细的部署文档和技术支持。感兴趣的用户可以通过 GitHub 提交 issue 或加入微信群获取进一步帮助。
https://www.zhihu.com/question/11385894245/answer/98216514346
大语言模型 RLHF 全链路揭秘:从策略梯度、PPO、GAE 到 DPO 的实战指南
本文从基础的梯度策略优化(Gradient Policy Optimization)讲起,逐步深入到经典的 REINFORCE 算法、近端策略优化(PPO)以及广义优势估计(GAE),并对比了在线(On-Policy)和离线(Off-Policy)强化学习方法,最后探讨了离线训练方法如直接偏好优化(DPO)的原理与局限性。
在线强化学习以 PPO 为代表,通过模型生成数据并实时更新策略,虽然训练效率较低,但能根据当前模型状态进行探索和更新,理论上效果上限更高。PPO 通过策略梯度优化,利用优势函数和剪切操作来稳定训练过程,其损失函数包括策略损失、价值函数损失和熵损失,旨在平衡策略更新的稳定性和效率。广义优势估计(GAE)通过结合多步估计和时间差分估计,平衡偏差与方差,进一步优化策略更新。
离线强化学习以 DPO 为代表,通过离线数据进行训练,避免了在线生成的高计算开销,但依赖数据与模型能力的匹配度。DPO 的目标是让模型学会评估回答的好坏,但其局限性在于缺乏在线生成和探索过程,可能导致模型在实际生成时表现不佳。此外,DPO 对数据质量要求较高,若数据覆盖不足或与目标分布不匹配,可能导致模型生成不合理的结果。
总体而言,PPO 和 DPO 各有优缺点。PPO 通过在线生成和实时反馈实现策略优化,适合需要高生成质量和探索能力的场景;而 DPO 通过离线数据训练,适合对生成效率要求较高的场景,但需要高质量的偏好数据来保证训练效果。

深度强化学习—Actor-Critic/TRPO/PPO/DPO
文章从深度强化学习的Actor-Critic架构讲起,深入剖析了TRPO、PPO以及DPO的技术细节与改进点。Actor-Critic架构包含Actor模型用于生成策略数据,Critic模型用于评估策略。Critic输出可有多种形式,如轨迹总回报、动作价值等,其中优势函数A(s,a)=Q(s,a)-V(s)被广泛应用,其核心在于引入基线V(s)避免梯度更新方向错误。A2C是使用优势函数的Actor-Critic模型,其优势在于仅需State Value输出,使模型更稳定。
文章进一步介绍了TRPO(信任区域策略优化),其核心在于通过定义新旧策略下的目标函数差距,并利用重要性采样与KL散度约束新旧策略接近,确保梯度更新在信任区域内进行,从而避免因Critic预估不准确导致的策略更新偏差。TRPO强调单调性,即每次策略更新都应更优。
PPO(近端策略优化)是对TRPO的改进,将KL散度约束融入主目标函数,简化了求解过程。PPO引入了近端策略惩罚与裁剪机制,通过动态调整KL散度约束超参数与限制重要性采样值的范围,进一步稳定策略更新。此外,PPO还采用GAE(广义优势估计)平衡方差与偏差,将优势从一步TD扩展到多步TD。
最后,文章介绍了DPO(直接偏好微调),其目标是简化RLHF-PPO框架中奖励模型训练的复杂性。DPO绕过奖励模型,将LLM直接作为奖励模型进行训练,通过化简PPO目标函数,将其退化为KL散度问题,从而将训练奖励模型与优化PPO目标函数融合。DPO基于BT(Bradley-Terry)模型与PT(Plackett-Luce)模型构建奖励模型目标函数,通过自定义Z(x)常量进一步简化公式,最终得到适用于DPO的损失函数,实现了对目标策略的优化。
文章详细阐述了从Actor-Critic到PPO、DPO的技术演进,展示了强化学习在策略优化与奖励模型训练方面的不断改进与创新。

HuggingFace&Github
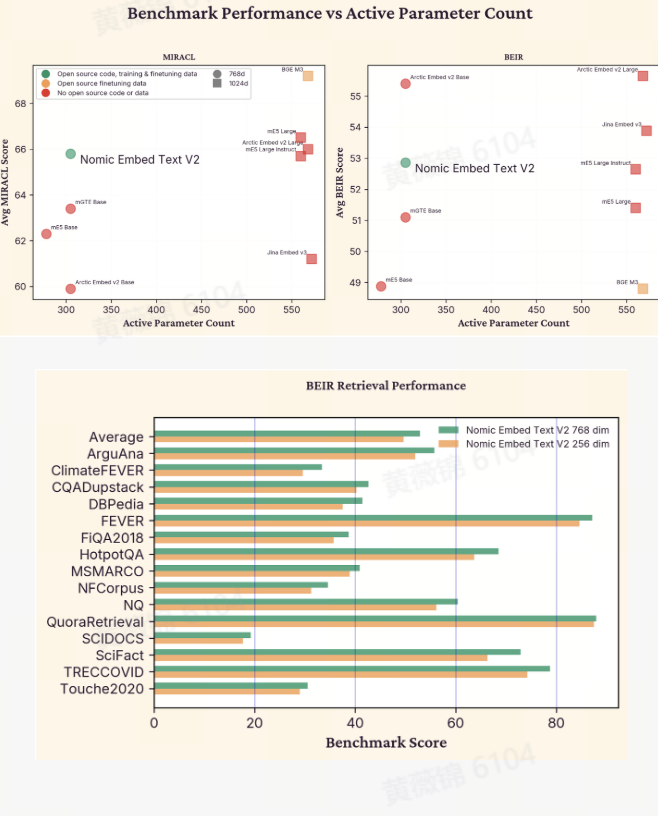
nomic-embed-text-v2-moe:多语言混合专家文本嵌入模型
nomic-embed-text-v2-moe 是一种擅长处理多语言检索任务的 MoE(混合专家)文本嵌入模型
-
高性能:与约 3 亿参数的模型相比,多语言性能更加出色,甚至与 2 倍大小的模型相媲美。
-
多语言支持:支持约 100 种语言,超过 16 亿数据的训练。
-
灵活的嵌入维度:采用 Matryoshka 嵌入方法,存储成本降低 3 倍,性能下降最小。
-
完全开源:模型权重、代码和训练数据(见代码库)全部开源。
-
模型架构:混合专家 (MoE),475M的总参数,305M的推理期间活动参数
-
MoE 配置:8 位专家,拥有前 2 名的路由
-
嵌入维度:通过 Matryoshka 表示学习支持从 768 到 256 的灵活维度
-
最大序列长度:512 个 token
https://huggingface.co/nomic-ai/nomic-embed-text-v2-moe
Scira:简约的AI 驱动搜索引擎
Scira 是一款简约的 AI 搜索引擎,前身为 MiniPerplx,可以在互联网上查找信息。由 Vercel AI SDK 提供支持,使用 Grok 2.0 等模型进行搜索。
-
AI 驱动搜索:使用 Anthropic 的模型获取问题的答案。
-
网页搜索:使用 Tavily 的 API 进行网页搜索,帮助你快速找到相关信息。
-
URL 特定搜索:获取特定 URL 中的信息,精准定位你的查询目标。
-
功能亮点:天气查询,编程功能地图查询,搜索 YouTube 视频,学术搜索,X 帖子搜索,航班追踪,热门电影和电视节目搜索。

2. 「理论与实践」AIPM 张涛:关于Diffusion你应该了解的一切
3. 「奇绩潜空间」吕骋访谈笔记 | AI 硬件的深度思考与对话
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/02/38276.html