
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即
可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!



HuggingFace&Github
WHAM:世界人类行为模型
World and Human Action Model (WHAM)是基于 Ninja Theory 的 Xbox 游戏《Bleeding Edge》(一款 3D、4v4 多人视频游戏)的游戏玩法数据训练的生成模型(视觉,控制器动作),以预测游戏视觉和玩家的控制器动作。
WHAM 由Microsoft Research的游戏智能小组与TaiX和Ninja Theory合作开发,目的在于探索生成式 AI 模型需要具备的能力,以支持人类的创意探索。
WHAM 是一种自回归模型,训练用于根据提示预测游戏视觉和控制器动作。允许用户通过以下模式运行模型:
-
(a) 世界建模模式(根据控制器动作生成视觉)
-
(b) 行为策略(根据过去的视觉生成控制器动作)
-
(c) 同时生成视觉和行为。
WHAM 能够持久的生成一致的游戏序列,支持各种创意迭代的使用场景。

https://huggingface.co/microsoft/wham
Mastra:开源 Typescript 代理框架
Mastra是一个开源 Typescript 代理框架,为开发者提供构建 AI 应用程序和功能所需的原语。
Mastra的功能包括:
-
工作流:基于图形的工作流引擎
-
Agent:提供代理调用工具(函数),保存代理记忆,并根据重复性、语义相似性或对话线程检索记忆。
-
RAG:提供 API,用于将文档(文本、HTML、Markdown、JSON)处理成块、创建嵌入并将其存储在矢量数据库中
-
部署:支持将代理和工作流捆绑在现有的 React、Next.js 或 Node.js 应用程序中,或捆绑到独立端点中
-
自动化评估:使用模型分级、基于规则和统计的方法来评估 LLM 输出
-
模拟路由:使用Vercel AI SDK进行模型路由,提供统一的接口与任何 LLM

https://github.com/mastra-ai/mastra
信号
HAMSTER: Hierarchical Action Models For Open-World Robot Manipulation
本文提出了一种新型的层次化视觉语言动作(VLA)模型——HAMSTER(Hierarchical Action Models with Separated Path Representations),旨在结合大型视觉语言模型(VLMs)的泛化能力和小型策略模型的效率、局部鲁棒性及巧灵性。以往的研究尝试通过微调预训练的VLMs直接生成机器人动作,但受限于昂贵的机器人数据采集成本和有限的数据规模与多样性,这些单体VLA模型未能展现出与VLMs和LLMs在其他领域相当的新兴能力。此外,小型机器人策略模型虽然在复杂任务中表现出色,但对环境和任务描述的剧烈变化较为脆弱,且难以有效利用仿真数据解决现实世界中的操作任务。
本文的核心创新在于提出一种层次化架构,将VLMs微调为生成中间表示,作为解决机器人操作任务的高级,指导而非直接预测机器人动作。这些中间表示可以被低级策略模型进一步转化为具体动作,从而减轻低级策略在长期规划和复杂语义推理上的负担。此外,通过选择易于从图像序列中获取、对机器人形态不敏感且对动态变化鲁棒的中间表示,VLMs可以利用非领域数据(如无动作视频、仿真数据、人类视频等)进行微调,这些数据无需在实际机器人硬件上采集,且通常更容易获取且数量丰富。
基于此,HAMSTER架构将大型微调VLMs与低级策略模型通过2D路径表示连接。2D路径是机器人末端执行器在2D图像平面上的粗略轨迹,以及夹爪状态的变化位置。这些路径可以通过点跟踪、手绘或本体感知投影等方法从非领域数据中廉价且自动地获取。实验结果表明,与OpenVLA相比,HAMSTER在七个不同泛化维度上的成功率平均提高了20%,相对增益达到50%。此外,由于HAMSTER基于开源的VLMs和低级策略构建,可作为社区构建视觉语言动作模型全的开源工具。本文的另一创新点在于提出这种层次化分解方式能够利用丰富的非领域数据来提升现实世界中的控制能力,为使用更廉价和丰富的数据源训练大型视觉语言动作模型提供了新的思路。

原文链接:https://arxiv.org/abs/2502.05485
Muon is Scalable for LLM Training
本文针对LLM训练中的优化问题展开研究,提出了改进的优化器Muon,旨在提高训练效率并解决现有优化器在大规模场景下的局限性。随着LLMs的快速发展,其训练过程因计算资源需求高而面临挑战,尤其是优化器在其中扮演着关键角色。尽管Adam及其变体AdamW是当前主流选择,但近期优化算法的研究表明,仍有改进空间以提升训练效率。
本文的核心创新点和重要工作包括:首先,通过对Muon优化器的深入分析,发现权重衰减对其可扩展性至关重要,并提出了参数级更新规则的调整策略。这些调整使得Muon在无需超参数调整的情况下即可直接使用,并显著提高了训练稳定性。其次,开发了基于ZeRO-1优化的分布式Muon版本,实现了在保持算法数学性质的同时,优化内存效率并减少通信开销。最后,通过对比实验验证了Muon在不同训练阶段(包括预训练和监督微调)的泛化能力,并基于扩展性研究结果表明,Muon在训练效率上优于AdamW,仅需约52%的计算量即可达到与AdamW相当的性能。
本文的实验结果表明,Muon能够有效替代AdamW,成为大规模LLMs训练的首选优化器,显著提升训练效率和模型性能。基于这些成果,作者发布了使用Muon训练的16B参数的MoE模型Moonlight,并开源了实现代码和中间训练检查点,以促进LLMs可扩展优化技术的进一步研究。

原文链接:https://github.com/MoonshotAI/Moonlight/blob/master/Moonlight.pdf
The Relationship Between Reasoning and Performance in Large Language Models — o3 (mini) Thinks Harder, Not Longer
本文探讨LLM在推理过程中“思考链条”长度与性能之间的关系。随着LLMs的发展,模型规模、数据和计算资源的扩展使其能够处理更复杂的任务,例如通过强化学习和推理时计算扩展结合的新型推理模型,这些模型利用推理标记指导思考过程,并在训练中优化思考链条,从而在复杂问题解决任务中表现出色。然而,关于更强大的模型是否需要更长的思考链条以实现更高性能,目前仍存在讨论。
本文通过系统性比较OpenAI的o1-mini、o3-mini (m)和o3-mini (h)模型在Omni-MATH数据集上的表现,发现更强大的模型(如o3-mini (m))并不依赖更长的思考链条来提高准确率,反而在思考链条增长时准确率下降得更慢,表明其更有效地利用了推理标记。此外,模型性能的提升并非完全依赖于推理标记数量的增加,而是模型对推理标记的优化分配。
Omni-MATH数据集是本文的重要工具,它提供了奥林匹克级别的数学问题评估框架,包含超过33个子领域和10个不同难度级别的问题,能够细致评估LLMs在不同学科和复杂度下的数学推理能力。此外,Omni-Judge模型的引入为自动验证模型生成答案提供了支持。
本文的研究不仅为“模型是否过度思考”这一问题提供了新的视角,还补充了关于推理步骤长度、输入长度、推理失败模式以及数学推理优化的相关研究。未来的研究可能会进一步探索更广泛的推理领域,包括语言理解和现实世界推理挑战,但目前数学和编码领域仍是重点,因为这些领域更容易实现客观的奖励模型和自动验证。
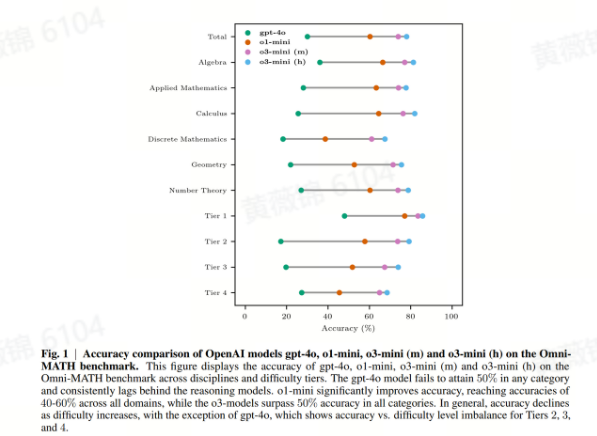
原文链接:https://arxiv.org/abs/2502.15631
SurveyX: Academic Survey Automation via Large Language Models
近年来,计算机科学在各个领域迅速发展,学术文献数量呈指数级增长。例如,arXiv.org 每天接收约千篇新论文,2022-2024 年间论文数量从 186,339 篇增长至 285,174 篇,预计 2025 年将达到 368,292 篇。这种爆炸性增长使得研究人员难以全面了解特定子领域的技术演变和发展轨迹。综述文章对于梳理研究现状和历史进程至关重要,但手动撰写综述的工作量不断增加,难以维持高质量和全面性。因此,开发高效的自动化综述生成系统迫在眉睫。LLM的出现为自动化综述生成提供了可能,但其应用面临技术与应用两方面的挑战。技术上,LLMs 依赖内部知识库,可能导致信息过时或错误,且其上下文窗口大小限制了对大量参考文献的处理能力。应用上,缺乏有效的工具获取最新相关参考文献,且综述生成缺乏统一的评估指标和基准,限制了其在学术领域的广泛应用。现有工作虽有进展,但仍存在不足,如检索方法缺乏时效性、参考文献预处理不充分以及生成综述形式单一等。
为此,我们提出 SurveyX 系统,将综述生成分为准备阶段和生成阶段。在准备阶段,SurveyX 通过检索算法获取高相关性参考文献,并采用 AttributeTree 方法提取关键信息,构建参考材料数据库,通过检索增强生成(RAG)技术实现高效检索。在生成阶段,SurveyX 依次生成综述大纲和主体内容,确保结构清晰、内容准确,并融入图表丰富呈现形式。此外,SurveyX 扩展了评估框架,引入更多指标评估生成综述和检索文献的质量。我们的主要贡献包括:提出一种高效的参考文献检索算法,通过关键词扩展扩大检索范围,并采用两步过滤法筛选高质量文献;设计 AttributeTree 方法高效提取文献关键信息,提升信息密度,优化 LLMs 上下文窗口使用;引入 Outline Optimization 方法生成逻辑严谨、结构清晰的大纲;扩展生成综述的表现形式,增加图表元素;扩充评估框架,结果表明 SurveyX 在多项指标上优于现有工作,接近人类专家水平。
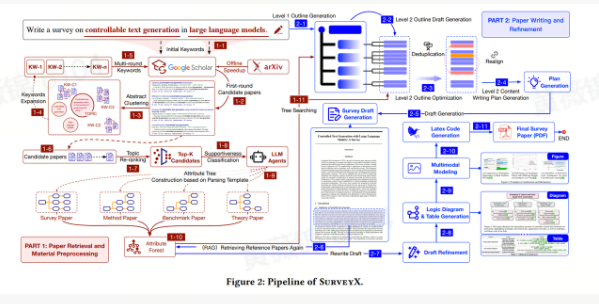
原文链接:https://arxiv.org/abs/2502.14776
Multimodal RewardBench: Holistic Evaluation of Reward Models for Vision Language Models
本文介绍了一个名为Multimodal RewardBench的多模态奖励模型基准测试,旨在全面评估视觉语言模型(VLMs)的奖励模型质量。现有基准测试主要集中在文本模态,且VLM评估多限于通用视觉问答任务,缺乏专家标注。为此,作者构建了涵盖六个关键能力(正确性、偏好性、知识、推理、安全性及视觉问答)的基准测试,收集了来自开源数据集的多样化文本+图像提示、多种VLM(如GPT-4o、Claude、Gemini、Llama3)的回答以及专家标注的选定和拒绝回答。基准测试包含5211个三元组(提示、选定回答、拒绝回答),可用于直接评估奖励模型的回答排序准确性,并支持更细致的性能测量,包括正确与错误回答以及人类偏好与非偏好回答的对比。
作者还分析了多种VLM评估器在Multimodal RewardBench上的表现,包括专有模型(GPT-4o、Claude、Gemini)、开源模型(Molmo、Aria)以及不同规模的Llama3。结果显示,大多数模型表现优于随机猜测(50%准确率),但仍未达到人类水平,表现最佳的Gemini 1.5 Pro和Claude 3.5 Sonnet整体准确率为72%。此外,多数模型在推理任务(数学和编程)和安全任务(尤其是毒性检测)上表现不佳。这表明Multimodal RewardBench是一个具有挑战性和独特性的多模态奖励模型评估平台。
本文的贡献包括:1)发布了一个涵盖六个领域的全面专家标注基准测试,填补了现有VLM奖励模型评估在知识、推理和安全领域空白;2)分析了当前最先进的VLM评估器的现状,揭示了VLM在规模扩展、知识和推理能力以及安全性(偏见和毒性检测)方面的趋势
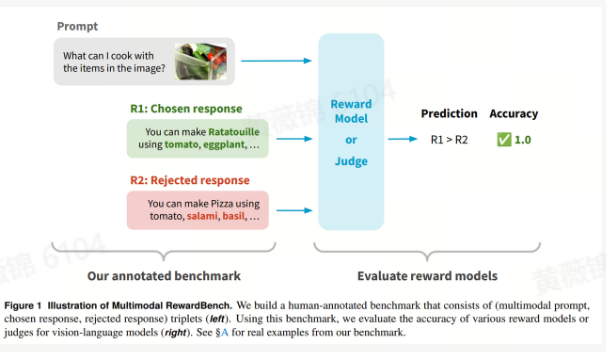
原文链接:https://arxiv.org/abs/2502.14191
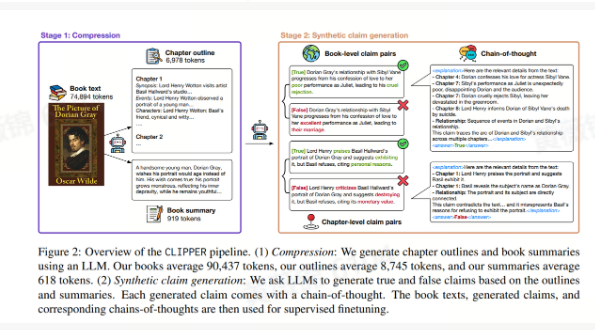
CLIPPER: Compression enables long-context synthetic data generation
本文针对LLM在长文本推理任务中合成数据生成的挑战,提出了一个名为CLIPPER的合成数据生成流程。由于人类标注数据成本高昂,开发者越来越多地依赖LLMs生成的合成数据来提升模型的指令遵循和推理能力。然而,现有方法在复杂推理任务(如叙事性声明验证)中表现不佳,因为这些任务需要对长文本中的事件、角色和关系进行全局推理。
CLIPPER通过两阶段流程解决这一问题:首先,使用LLM将长文档压缩为包含关键事件和描述的摘要或大纲;然后,基于压缩后的叙事生成需要跨章节推理才能验证的声明,并提供支持这些声明的推理链。与直接使用完整未压缩文本相比,CLIPPER显著减少了生成声明中的噪声,提高了解释的有根性,并将成本降低了约一半。
为了验证CLIPPER的有效性,作者使用该流程生成了包含19K个关于公共领域小说的声明数据集,并在这些数据上微调了多个开源模型(如Llama-3.1-8B-Instruct、ProLong-512K-8B-Base和Qwen2.5-7B-Instruct),在叙事性声明验证任务上取得了显著性能提升。例如,微调后的Llama-3.1-8B-Instruct在NoCha基准测试中的性能从16.5%提升至32.2%,测试集性能从27.9%提升至76.0%。此外,微调后的Qwen模型在小于10B的模型中达到了NoCha任务的新最佳性能。
尽管CLIPPER在提升长文本推理能力方面表现出色,但其生成的合成声明与人类编写的声明仍存在差距,尤其是在需要推理细节时。未来工作有望利用CLIPPER生成的数据微调更大规模的模型,以进一步提升全局推理能力。
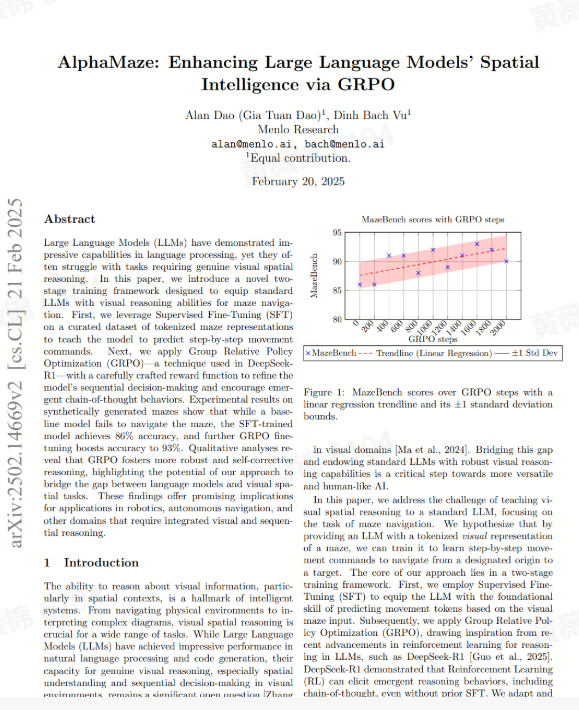
AlphaMaze: Enhancing Large Language Models’ Spatial Intelligence via GRPO
本文提出了一种创新的训练框架,旨在提升LLM在视觉空间推理任务中的表现,以迷宫导航任务为研究重点。研究的核心在于通过两阶段训练——监督微调(SFT)和群体相对策略优化(GRPO)——使LLM能够基于迷宫的离散化视觉表示学习逐步移动指令,从而从起点导航至目标点。SFT为模型提供了基于视觉输入预测移动指令的基础能力,而GRPO则借鉴了强化学习在LLM推理中的最新进展(如DeepSeek-R1),通过精心设计的奖励函数进一步优化模型的视觉推理能力。
为系统评估LLM的迷宫解决能力,本文引入了MazeBench——一个涵盖多种迷宫规模和复杂度的综合基准测试环境。实验结果表明,该训练框架能够显著提升LLM在迷宫导航任务中的准确率,并使其在生成移动序列时展现出链式推理等新兴行为。此外,本文还详细分析了GRPO阶段中奖励函数的设计及其对模型推理性能的关键影响,并与DeepSeek-R1等前沿推理模型在方法和行为表现上进行了对比,明确了本研究在当前LLM推理领域的定位。
最后,本文提出了MazeBench这一基准测试,为视觉迷宫导航任务提供了一个涵盖广泛空间挑战的评估平台,为未来相关研究提供了有力支持。
Scaling Text-Rich Image Understanding via Code-Guided Synthetic Multimodal Data Generation
本文提出了一种名为Code Guided Synthetic data generation system(CoSyn)的框架,旨在通过生成合成数据提升视觉语言模型(VLMs)在文本丰富图像理解任务中的表现。当前的VLMs在处理自然图像时表现出色,但在处理图表、文档、图表、标签等文本丰富图像时能力不足,因为这些任务需要结合文本理解和空间推理能力,而高质量的数据集稀缺。
CoSyn框架的核心思想是利用文本丰富图像通常由代码生成的特性,通过自然语言指令生成合成数据。CoSyn利用擅长代码生成的纯文本语言模型(LLMs),结合11种支持的渲染工具(如Python、HTML、LaTeX),从简单的自然语言查询生成多样化的目标领域合成数据,包括图像和对应的文本指令。基于此框架,作者构建了CoSyn400K——一个大规模、多样化的合成视觉语言指令调优数据集,专门用于文本丰富图像理解。
实验表明,使用CoSyn生成的合成数据训练的模型在七个文本丰富视觉问答(VQA)基准测试中达到了最先进的性能,超越了GPT-4V和Gemini 1.5等专有模型。此外,CoSyn合成数据支持样本高效学习,即使在少量数据上也能实现更强性能。CoSyn还可以生成链式推理(CoT)数据,提升多跳推理任务的表现。在ChartQA数据集的细粒度分析中,CoSyn训练的模型对人类编写的自然问题具有更强的泛化能力,而仅在现有学术数据集上训练的模型则容易过拟合。
作者进一步指出,开源VLMs在未训练过的领域任务上泛化能力较差。为此,他们引入了NutritionQA——一个用于理解营养标签照片的新基准测试。开源VLMs即使在数百万图像上训练后,仍难以适应这一新任务,但通过在CoSyn400K上训练,模型在零样本设置下能够快速适应新领域。仅使用CoSyn生成的7K营养标签合成数据进行微调,模型就超越了在数百万图像上训练的大多数开源VLMs,突显了CoSyn在数据效率和帮助VLMs适应新领域方面的优势。
此外,CoSyn还被用于生成合成指针数据,用于代理任务(如“指向结账按钮”)。在ScreenSpot点击预测基准测试中,使用合成指针数据训练的模型达到了最佳性能。总体而言,本文证明了合成数据在提升VLMs理解文本丰富图像方面具有巨大潜力,并为VLMs作为多模态数字助手在现实世界应用中解锁了新的可能性。

2. 「理论与实践」AIPM 张涛:关于Diffusion你应该了解的一切
3. 「奇绩潜空间」吕骋访谈笔记 | AI 硬件的深度思考与对话
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/02/43095.html