
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即
可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!



HuggingFace&Github
Chinese-DeepSeek-R1-Distill-data-110k
-
主要信息:数据集中不仅包含math数据,还包括大量的通用类型数据,总数量为110K。
-
蒸馏方式:按照DeepSeek R1官方提供细节进行蒸馏
-
字段说明:input: 输入,reasoning_content: 思考,content: 输出,repo_name: 数据源,score: 模型打分结果
功能:有助于研究人员复现R1蒸馏模型的效果

https://huggingface.co/datasets/Congliu/Chinese-DeepSeek-R1-Distill-data-110k
信号
Distillation Scaling Laws
知识蒸馏(Knowledge Distillation)是一种通过让小规模的学生模型模仿大规模教师模型的输出来提升性能的技术。然而,其有效性在不同场景下存在争议,且缺乏理论指导。本文旨在通过提出蒸馏缩放定律,深入理解知识蒸馏的机制,并量化其在不同资源分配下的表现。
本文提出了一个描述学生模型性能与教师模型、学生模型参数以及蒸馏数据量之间关系的公式:
主要发现:
-
教师模型的影响: 教师模型的交叉熵是决定学生模型性能的关键因素,而教师模型的大小和训练数据量仅通过影响教师模型的交叉熵来间接影响学生模型。
-
容量差距现象: 当教师模型过于强大时,学生模型的性能会下降。这种现象被称为“容量差距”,其根源在于教师和学生之间的学习能力差距,包括假设空间和学习优化能力的差异。
-
学生模型性能的上限: 当学生模型拥有足够的计算资源或数据时,其性能不会超过监督学习下的性能。
研究意义:
-
资源分配: 在资源有限的情况下,蒸馏可以成为监督学习的有力替代方案,但需要根据具体场景选择合适的教师模型和计算资源分配策略。
-
教师模型选择: 选择教师模型时,不应仅仅关注其大小,而应更关注其交叉熵,因为教师模型的交叉熵是决定学生模型性能的关键因素。
-
蒸馏 vs 监督学习: 当目标只是训练一个目标大小的最佳模型时,监督学习通常是更好的选择。但如果教师模型有其他用途,或者需要训练多个学生模型,蒸馏可能更有效。

原文链接:https://arxiv.org/abs/2502.08606
LIMO: Less is More for Reasoning
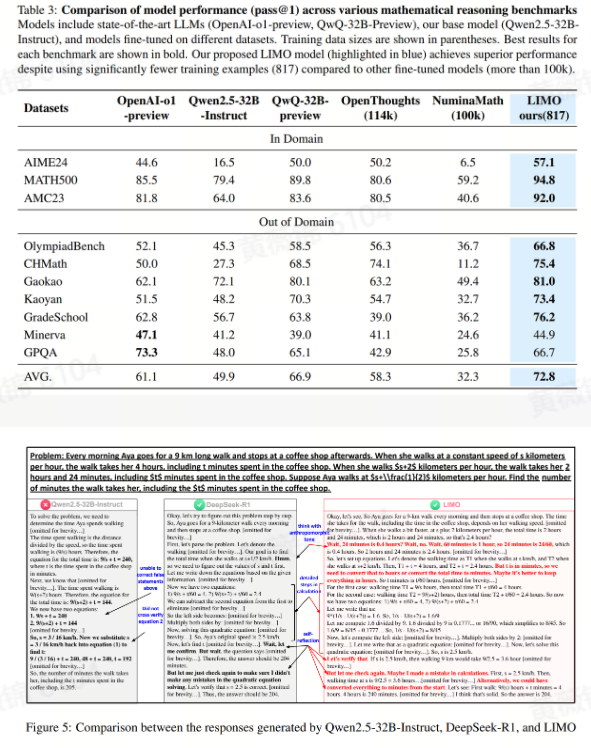
本文提出了一项挑战传统认知的基础性发现,即复杂推理在大语言模型中的涌现不一定需要大量训练数据(超过10万例)。
研究表明,通过少量精心挑选的示例,可以有效地激发复杂数学推理能力。提出的模型LIMO在数学推理任务中表现出前所未有的性能。在仅使用817个精选训练样本的情况下,LIMO在AIME和MATH数据集上的准确率分别达到了57.1%和94.8%,相较于之前基于监督微调(SFT)的模型(分别为6.5%和59.2%)有显著提升,而使用的训练数据仅为之前方法的1%。LIMO还展示了卓越的分布外泛化能力,在10个不同的基准测试中实现了40.5%的绝对提升,超越了那些使用100倍数据训练的模型,这挑战了SFT导致记忆而非泛化的观点。
基于这些结果,作者提出了“少即是多推理假设”(LIMO Hypothesis):在预训练过程中已经全面编码了领域知识的基础模型中,复杂的推理能力可以通过少量但精确设计的认知过程示范来激发。该假设认为,复杂推理的激发阈值由两个关键因素决定:
(1)预训练期间模型编码的知识基础的完整性;
(2)后训练示例作为“认知模板”的有效性,这些示例展示了模型如何利用其知识库来解决复杂的推理任务。
原文链接:https://arxiv.org/abs/2502.03387
Monte Carlo Tree Diffusion for System 2 Planning
扩散模型最近已成为规划的强大工具。然而,与蒙特卡洛树搜索(MCTS)不同——MCTS的性能会随着额外的测试时计算(TTC)自然提升——标准的基于扩散的规划器在TTC的可扩展性方面提供的机会有限。
本文提出了一种名为蒙特卡洛树扩散(MCTD)的新框架,该框架结合了扩散模型的生成能力与MCTS的自适应搜索能力。该方法将去噪过程重新定义为树状结构,允许部分去噪的计划被迭代评估、修剪和完善。通过有选择地扩展有前景的轨迹,同时保持重新访问和改进次优分支的灵活性,MCTD在扩散框架内实现了MCTS的优势,如控制探索与利用之间的权衡。在具有挑战性的长视距任务上的实证结果表明,MCTD优于扩散基线方法,并且随着TTC的增加,解决方案的质量也得到了提高。

原文链接:https://arxiv.org/pdf/2502.13928
Automated Hypothesis Validation with Agentic Sequential Falsifications
假设在信息获取、决策和发现过程中至关重要,但许多现实世界中的假设是抽象的、高层次的,难以直接验证。随着大型语言模型(LLMs)生成假设能力的提升,这一挑战变得更加严峻,因为这些模型容易产生幻觉,并且生成的假设数量庞大,难以手动验证。
为此,本文提出了Popper,一个用于严格自动化验证自由形式假设的代理框架。Popper基于卡尔·波普尔的证伪原则,通过设计并执行旨在验证假设可测量含义的证伪实验来验证假设。其新颖的序贯测试框架在积极收集来自不同观察的证据的同时,确保了严格的I型错误控制,无论这些观察来自现有数据还是新进行的程序。研究在包括生物学、经济学和社会学在内的六个领域展示了Popper的应用,结果表明Popper能够提供强大的错误控制、高效能和可扩展性。此外,与人类科学家相比,Popper在验证复杂生物假设方面达到了相当的性能,同时将时间缩短了10倍,为假设验证提供了一种可扩展且严格的方法。

原文链接:https://arxiv.org/abs/2502.09858
Computational-Statistical Tradeoffs at the Next-Token Prediction Barrier: Autoregressive and Imitation Learning under Misspecification
在自回归序列建模中,基于对数损失的下一个词预测虽然是一个核心方法,但在实际应用中会因误差放大问题而受到影响,即随着序列长度$$H$$的增加,模型中的误差会累积,导致生成质量下降。尽管在设定良好的情况下理论上不应出现这种现象,但越来越多的实证研究表明,模型指定不足可能是误差放大的根本原因。在模型指定不足的情况下,目标是最小化与最佳同类模型的乘数近似因子 $$C$$。研究表明,对于下一个词预测,$$C$$会随着$$H$$的增加而增加,这支持了上述实证假设。研究进一步探讨了算法上、计算上或信息理论上避免这种误差放大模式的可能性,并揭示了固有的计算-统计权衡。具体来说,信息理论上可以避免误差放大,实现$$C=O(1)$$;下一个词预测可以通过增强实现 $$C=O(widetilde{H} )$$,但这是固有限制;自回归线性模型的自然测试平台中,没有高效的算法能实现次多项式近似因子 $$C=e^{(logH)^{1-Omega(1)}} $$,但对于二元词空间,可以在亚指数时间内通过计算换取统计能力来改进 $$C=Omega (H)$$的结果。这些结果对模仿学习领域也有启示,其中行为克隆算法是下一个词预测的推广。
原文链接:https://arxiv.org/abs/2502.12465
When One LLM Drools, Multi-LLM Collaboration Rules
这篇立场论文认为,在许多现实场景(复杂、情境化、主观)中,单一的大型语言模型(LLM)难以产生可靠的结果。该论文挑战了仅依赖单一通用LLM的现状,主张通过多LLM协作来更好地代表数据、技能和人群的多样性。
首先,论文指出单一LLM无法充分代表现实世界的数据分布、多样化的技能和多元化的群体,且这种代表不足的问题无法通过进一步训练单一LLM轻易解决。
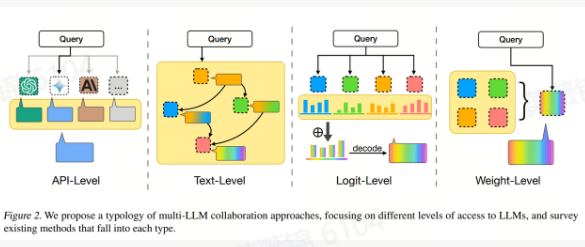
随后,论文将现有的多LLM协作方法组织成一个层次结构,基于访问和信息交换的级别,从API级、文本级、logit级到权重级协作。基于这些方法,论文展示了多LLM协作如何应对单一LLM难以解决的挑战,如可靠性、民主化和多元化。
最后,论文指出现有多LLM方法的局限性,并激励未来的研究。论文认为,多LLM协作是实现组合智能和协作AI发展的关键路径。
原文链接:https://arxiv.org/abs/2502.04506
Interactive Agents to Overcome Ambiguity in Software Engineering
随着AI代理被越来越多地用于自动化任务,它们常常需要基于模糊和不明确的用户指令进行操作。如果AI代理做出不当假设或未能提出澄清问题,可能会导致次优结果、安全风险(如工具误用)以及计算资源的浪费。
本研究探讨了大语言模型(LLM)代理在交互式代码生成环境中处理模糊指令的能力,具体通过评估专有和开源模型在以下三个关键步骤中的表现:(a) 利用交互来提高在模糊场景中的性能,(b) 检测模糊性,以及 (c) 提出针对性问题。研究发现,模型难以区分明确和不明确的指令。然而,当模型与用户进行交互以处理不明确输入时,它们能够有效地从用户那里获取关键信息,从而显著提高性能,强调了有效交互的价值。本研究揭示了当前最先进的模型在处理复杂软件工程任务中的模糊性方面的关键不足,并通过将评估结构化为不同步骤,为有针对性的改进提供了可能。

原文链接:https://arxiv.org/abs/2502.13069
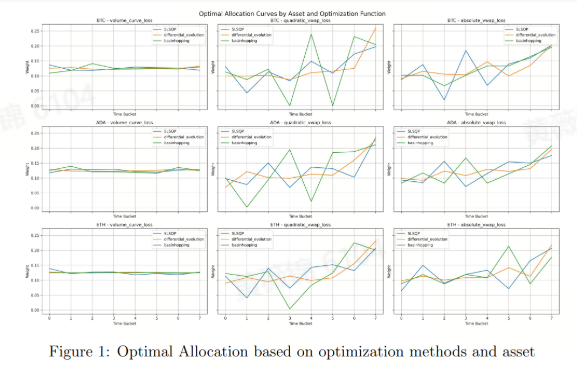
Deep Learning for VWAP Execution in Crypto Markets: Beyond the Volume Curve
成交量加权平均价格(VWAP)是交易执行中的关键基准,但其实现因依赖动态变化的成交量和价格而具有挑战性。传统方法侧重于预测成交量曲线,但在波动性较大的市场(如加密货币市场)中效果不佳。本研究提出了一种深度学习框架,通过直接优化VWAP执行目标,绕过成交量曲线预测,利用自动微分和自定义损失函数调整订单分配,以最小化VWAP滑点。实验结果表明,该方法在降低VWAP滑点方面优于传统方法,即使使用简单的线性模型也是如此。这一框架不仅在加密货币市场中表现出色,其基本原理也适用于其他资产类别,如股票,展示了深度学习在复杂金融系统中的潜力,特别是在直接目标优化方面。
原文链接:https://arxiv.org/abs/2502.13722
2. 「理论与实践」AIPM 张涛:关于Diffusion你应该了解的一切
3. 「奇绩潜空间」吕骋访谈笔记 | AI 硬件的深度思考与对话
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/02/43124.html