
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


潜空间第六季活动开始报名!!

资讯
南大周志华团队获奖,AAAI 2025杰出论文奖出炉
AAAI 2025 于 2 月 25 日在美国宾夕法尼亚州费城开幕,持续至 3 月 4 日。此次会议共有 12957 篇有效投稿,最终录取 3032 篇,录取率为 23.4%。其中,Oral 论文占比 4.6%。本届会议的杰出论文奖已正式公布,表彰在技术贡献和阐述方面具有最高标准的论文。
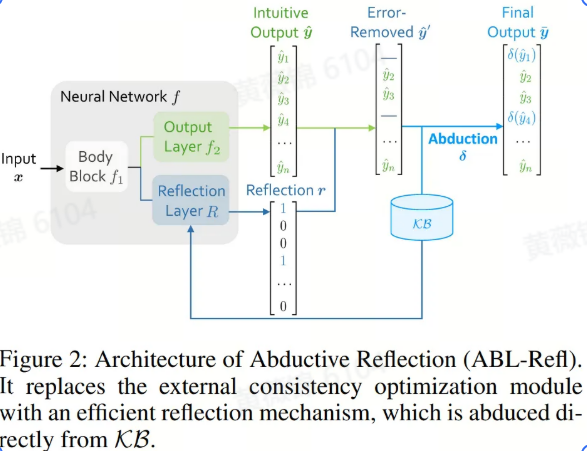
三篇杰出论文分别来自南京大学、多伦多大学和波尔多大学等机构。南京大学的论文《Efficient Rectification of Neuro-Symbolic Reasoning Inconsistencies by Abductive Reflection》由周志华团队主编,提出了一种改进神经符号 AI(NeSy)系统的方案。该方案通过引入基于溯因学习的溯因反射(ABL-Refl),提高了系统的推理一致性和效率。实验结果显示,ABL-Refl 在减少训练资源消耗的同时,超越了当前的最先进方法。
多伦多大学的论文《Every Bit Helps: Achieving the Optimal Distortion with a Few Queries》探讨了多智能体系统中的排序匹配问题。作者提出了一种新型的排序算法,可以在有限查询次数内实现渐近最优的扭曲度,大大提高了系统的效率。这种方法在单边匹配和投票问题中均取得了显著的改进。
波尔多大学的论文《Revelations: A Decidable Class of POMDPs with Omega-Regular Objectives》则提出了两类部分可观测马尔可夫决策过程(POMDPs)的可判定算法。该算法通过将弱揭示和强揭示问题简化为对有限信念支持马尔可夫决策过程的分析,为一类 POMDP 提供了高效的解决方案。实验结果表明,作者的算法在解决揭示 POMDP 时优于基于深度强化学习的方法。
此外,AAAI 2025 还颁发了 AI 对社会影响特别奖,获奖论文《DivShift: Exploring Domain-Specific Distribution Shifts in Large-Scale, Volunteer-Collected Biodiversity Datasets》由斯坦福大学等机构的团队撰写,研究了如何利用志愿者收集的生物多样性数据来监测气候变化对生物多样性的影响。文章提出了一个名为 DivShift 的框架,并分析了数据偏差对深度学习模型性能的影响。
https://mp.weixin.qq.com/s/eAr9MMIXY6eqKIFylmMLag
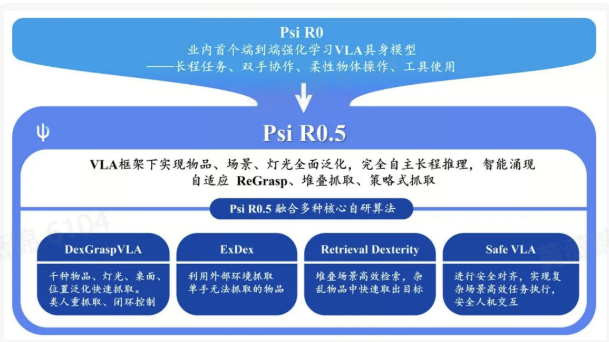
灵初智能发布端到端VLA模型Psi R0.5
近日,Figure发布了端到端VLA具身大模型Helix,该模型采用分层架构,兼具高频控制和高泛化能力,引发业内关注。与此同时,中国的灵初智能发布了基于强化学习的Psi R0.5模型,较去年底的Psi R0实现了重大升级。Psi R0.5在复杂场景的泛化能力、灵巧性、CoT(推理能力)、长程任务能力上都有显著提升,而且其完成泛化抓取训练所需的数据量仅为Helix的0.4%。这标志着灵初智能在全球范围内实现了泛化灵巧操作与训练效率的双重领先。
灵初智能团队发布了四篇高质量论文,展示了其在具身智能领域的最新成果,涵盖了高效泛化抓取、堆叠场景物品检索、外部环境协作抓取、VLA安全对齐等多个方面。团队提出的DexGraspVLA框架,能够通过少量数据(仅需约2小时)在上千种物体、位置、光照变化下实现灵巧抓取,且相较于Figure的模型,数据利用效率提升了250倍。DexGraspVLA的优势在于其强大的语言指令理解能力,能够在复杂环境中进行精准抓取,并通过CoT推理自动完成多个抓取目标的任务。
此外,灵初的Retrieval Dexterity系统通过强化学习解决了堆叠场景中物品检索效率低的问题,不仅能够高效完成训练过物体的抓取任务,还能在未见过的新物体上进行泛化。该系统与传统方法相比,操作步骤减少了38%-90%,极大提升了效率。
ExDex模型则解决了物品尺寸超过机器人末端执行器最大开度时无法抓取的问题,通过强化学习利用外部环境特征,帮助机器人完成那些无法直接抓取的任务。经过大量实验验证,ExDex展现了超越人类遥操作水平的灵巧性,并能够成功将仿真训练策略迁移至实际机器人中。
在安全性方面,灵初智能与北京大学PAIR-Lab团队合作开发了SafeVLA模型。该模型引入了安全对齐机制,能够在复杂环境中保证人机交互的安全性,尤其在面对环境干扰时展现了出色的鲁棒性。SafeVLA通过将安全约束融入仿真环境,实现了任务执行效率和安全性的双重突破,成功提高了83.58%的安全性和3.85%的任务执行效率,且在OOD(分布外)测试中表现优异。
https://mp.weixin.qq.com/s/55l129vnMl3ysoXRFBpp3w
无问芯穹FlightVGM获FPGA’25最佳论文
在2025年FPGA国际会议上,最佳论文奖首次颁发给完全由中国大陆团队主导的研究——无问芯穹与上海交通大学、清华大学联合提出的“FlightVGM”视频生成大模型推理IP。这是该会议首次授予亚太国家团队这一殊荣。FlightVGM在FPGA上实现了视频生成模型(VGM)的高效推理,相较于NVIDIA 3090 GPU,在AMD V80 FPGA上的性能提升达1.3倍,能效提升达到4.49倍。
这项研究通过创新硬件架构,提升了视频生成模型的计算效率,尤其在生成高分辨率、长时长视频时,解决了计算量和内存消耗过大的问题。FlightVGM的核心创新在于如何充分利用视频生成过程中的时空冗余性,采用了三项关键技术:时间-空间激活值在线稀疏化方法,浮点-定点混合精度DSP58扩展架构,以及动态-静态自适应调度策略。通过这些方法,FlightVGM能够有效减少计算负担,并提高硬件利用率。
技术上,FlightVGM在计算过程中通过稀疏化减少不必要的计算,通过余弦相似度检测相似性,从而跳过冗余的部分。特别是在浮点-定点混合精度方面,FlightVGM采用了一种新的硬件架构,允许在FP16与INT8精度间切换,从而最大化硬件资源的利用。这些创新使得在处理复杂视频生成任务时,FPGA能够提供优于传统GPU的性能和能效。
在实验评估中,FlightVGM在保持模型精度的同时,显著提升了计算性能和能效。与GPU相比,尽管V80 FPGA的峰值算力差距超过21倍,FlightVGM依然能够在性能和能效上超过GPU,体现了FPGA在视频生成模型加速中的潜力。
未来,随着VGM计算需求的不断增长,FPGA有望在视频生成任务中发挥更大的作用。通过进一步探索新的FPGA架构,如AI引擎与高带宽内存(HBM)结合的方式,FPGA可能成为更高效的计算平台,推动大模型的应用与落地。

https://mp.weixin.qq.com/s/SE4Fh6Rmr6Hm1JA7VJTgfw
推特
Altman:GPT-4.5 是人们首次如此热情地发来邮件,要求我们承诺绝不停止提供某个特定模型
GPT-4.5 是人们首次如此热情地发来邮件,要求我们承诺绝不停止提供某个特定模型,甚至不能用更新版本来替换它
干得好@Kai,@Rapha,@Amelia Glaese

https://x.com/sama/status/1896231850093551878
Raschka分享新视频:文本数据处理,来自“从零开始构建大型语言模型”系列
我“从零开始构建大型语言模型”系列中的新视频现已上线。在这段教程里,我将讲解文本数据处理,它对理解和训练 LLM 都是十分重要的组成部分。
在视频中,我主要介绍了以下内容:
• 将原始文本进行分词并转换成词元 ID 的过程
• 如何加入特殊的上下文词元以及应用 Byte Pair Encoding (BPE)
• 使用滑动窗口进行数据采样的技巧
• 在 PyTorch 中设置数据加载器以实现高效训练
无论你是出于研究、学习还是生产目的来了解 LLM 的工作原理,我都希望这次对文本数据处理的探讨能为你提供有益的见解!
你可以在这里观看完整视频:https://youtube.com/watch?v=341Rb8fJxY0
供参考,以下是视频目录:
00:00 文本分词
14:02 将词元转换为词元 ID
23:56 添加特殊的上下文词元
30:26 Byte Pair Encoding
44:00 使用滑动窗口进行数据采样
1:07:10 创建词元嵌入
1:15:45 编码词的位置
https://x.com/rasbt/status/1896208257884066027
原子思维Atom of Thoughts: 与人类依靠独立单元进行思考不同,现有模型会存储完整的推理历史
推理模型缺乏原子化思维 ⚛️
与人类依靠独立单元进行思考不同,现有模型会存储完整的推理历史 🤔
引入原子思维(Atom of Thoughts, AOT):
将 GPT-4o-mini 在 HotpotQA 上的 F1 分数提升至 80.6%,超越了 o3-mini 和 DeepSeek-R1!
最棒的是?它可以无缝接入任何框架 🔌
为什么需要原子化思维?🤔
当前所有推理方法——无论是模型(o3, R1…)还是框架(CoT, ToT, GoT…)——都存在相同的问题:
它们始终保留完整的推理历史
这带来了两个主要弊端:
💰 计算成本高昂
🚫 容易受到干扰
AOT 是如何工作的?⚙️
对于每一步推理:
1. 将问题分解为 有向无环图(DAG)
2. 将子问题合并为 新的、更简单的问题
3. 迭代进行,直至得到 原子化问题
就像 马尔可夫过程:每个新问题 仅依赖于前一状态!🎯
AOT 插件的强大之处 🔌
AOT 适用于任何方法:o3、R1、CoT、ToT、GoT、Self-Consistency,甚至 Agentic Workflow!
它能 简化输入,同时 保持高质量的解决方案 💡
尝试将 AOT 集成到你最喜欢的推理方法中吧!

https://x.com/didiforx/status/1895902471635288252
Viber 3D: 现代化的 3D 浏览器游戏入门套件
我为 Cursor ai 创建了一个 3D 游戏入门套件!
🎮 最新 React 19 + React Three Fiber
🤖 预定义 .cursor/rules
📏 TypeScript 支持
快速入门视频见评论区 👇
https://x.com/kregenrek/status/1896215301483823297
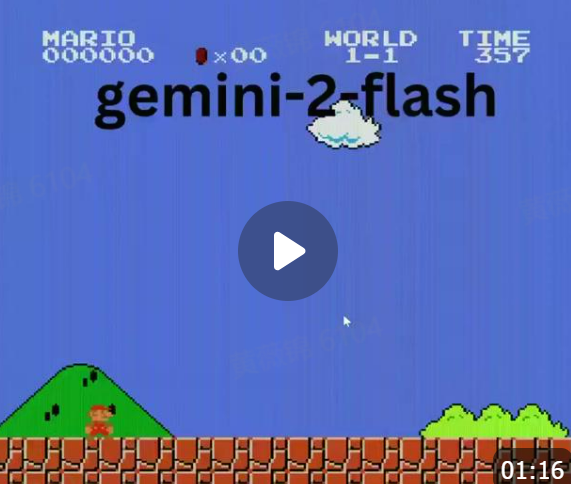
大预言模型游玩超级马里奥?GamingAgent —— 个人电脑游戏智能代理
使用 LLM 玩 Pokémon 已成为一个基准测试,但 超级马里奥 呢?
事实证明,@GoogleDeepMind 的 Gemini 2.0 Flash 能够 实时玩超级马里奥,得益于其 低延迟、多模态输入和长上下文!🎮
Gemini 2.0 Flash 接收游戏的截图,并为每一帧生成 Python 代码(PyAutoGUI 指令) 来控制游戏操作,持续 1 到 2 秒。
只需加上一个 while 循环,它就能 实时游玩!🤯
https://x.com/_philschmid/status/1896109334527926663
产品
Chikka.ai 借助智能 AI 语音访谈工具
想了解用户反馈、员工想法或朋友的意见吗?
只需 5 分钟即可设置您自己的 AI 语音代理,与真实用户亲切互动,并在自然对话中提出有价值的问题。之后,您只需点击一下,即可获得可行的洞察!
工作原理如下:
-
创建您的首次访谈:使用 AI 生成的模板,或者根据自身需求自定义问题。
-
让 Ava 主导:在任何数字平台(电子邮件、WhatsApp、Instagram 等)上分享您独特的访谈链接,然后观看 Ava 与受访者进行流畅的对话。
-
即时解锁洞察:获取实时转录文本、分析结果以及可行的建议,助力您做出决策 。
Chikka.ai 的优势:
-
借助我们强大的 AI 语音访谈工具,深入了解用户。
-
实时获取可行的洞察,节省您的时间和精力。
-
无需培训,几分钟即可创建动态访谈!
HuggingFace&Github
Phi-4-mini-instruct:轻量级开源模型
https://huggingface.co/microsoft/Phi-4-mini-instruct
Phi-4-mini 是一个轻量级开源模型,该模型属于 Phi-4 系列,支持 128K 令牌上下文长度。该模型经过增强过程,通过监督微调和直接偏好优化。Phi-4-mini-instruct 基于 Phi-3 系列的用户反馈。Phi-4-mini 模型采用了新的架构以提高效率,扩大了词汇量以支持多语言,并且使用了更好的后训练技术来跟踪指令、调用函数以及获取更多数据。
应用场景:
-
内存/计算受限的环境
-
延迟受限场景
-
数学和逻辑推理
投融资
杭州投资智谱,支持GLM国产大模型技术发展
智谱完成新一笔金额超10亿元人民币的战略融资,参与投资方包括杭州城投产业基金、上城资本等。 融资将推动国产基座GLM大模型的技术创新和生态发展,更好服务浙江省和长三角地区蓬勃发展的经济实体,发挥区域人工智能产业布局优势,助力基于人工智能技术的数字产业转型升级。
https://mp.weixin.qq.com/s/O66XmezmJmBOGoeRQzQvNA
— END —
2. 「理论与实践」AIPM 张涛:关于Diffusion你应该了解的一切
3. 「奇绩潜空间」吕骋访谈笔记 | AI 硬件的深度思考与对话
快速获得3Blue1Brown教学动画?Archie分享:使用 Manim 引擎和 GPT-4o 将自然语言转换为数学动画
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2025/03/43197.html