


在数字化时代,人工智能成为技术革新与社会发展的关键驱动力。从早期的规则算法发展到深度学习驱动的复杂系统,AI的突破始终与数据爆发和算力跃升密不可分。其中视频数据作为高信息密度的载体发挥关键作用,海量视频数据的涌现推动了视频理解技术的突破,通过智能分类与检索显著提升处理效率与精度,广泛应用于安防监控、智能交通、数字内容生产等领域。
视频数据集为大模型注入时空维度信息,使其能捕捉物体运动、场景演变等动态特征。多样化场景数据显著增强模型泛化能力,尤其在文生视频等前沿任务中。此类数据集构建了文本与视觉序列的映射基础,为应对现实世界复杂性提供重要支撑。
视频字幕数据集概述
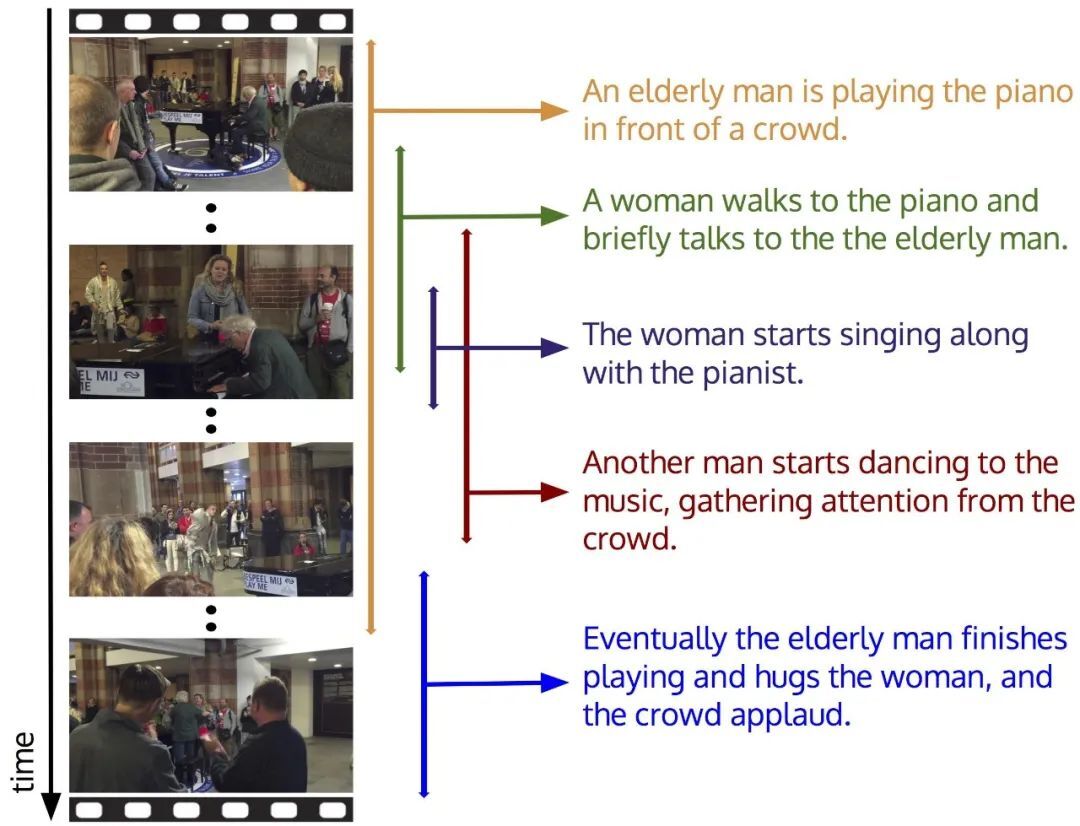
视频字幕数据集(Video Captioning Datasets)作为连接视觉与语言的桥梁,不仅是多模态模型的“燃料”,更是推动AI从“感知”迈向“认知”的关键基石。其核心目标是通过文字描述(如句子、标题或标签)为视频内容提供语义标注,帮助模型建立视觉与语言之间的跨模态关联。和其他类型的数据集相比,这类数据集提供更丰富的语义描述,通常包含视频片段、时间戳、自然语言描述及辅助元数据,形成“视觉 – 语言 – 时序”三位一体的训练素材。视频字幕数据集在生成式 AI 模型训练中扮演着多维度的关键角色,其价值不仅体现在数据规模的支撑,更在于以下三个方面:
-
多模态对齐学习:视频字幕数据集通过精确到帧级的时间戳标注,模型建立视觉内容与语言符号的时空映射关系。训练过程中,模型需同步处理动态画面(如人物动作)、音频线索(如对话)和文本标签(如场景描述),这种多模态输入迫使模型学习跨模态对齐的潜在表征。
-
强化时序理解与动态建模:视频字幕数据集特有的时间标注机制,为生成式模型提供了天然的时序监督信号。使模型学习事件序列的因果关系与时间逻辑,能够在生成描述时自动捕捉动作的先后顺序,提升模型对视觉叙事节奏的理解能力。
-
推动复杂场景解析:大规模视频字幕数据集涵盖日常至专业场景,其中电影级高复杂度标注(如角色互动/场景转换)驱动模型突破简单描述,实现复杂叙事解析。模型通过对时空关系和因果逻辑的深层理解,提升推理能力,配合开放域训练强化泛化能力,可应对现实世界未知场景。
视频字幕数据集
1. MSVD(Microsoft Video Description Dataset)
-
发布方:Microsoft Research,University of Texas at Austin
-
下载地址:https://www.cs.utexas.edu/~ml/clamp/videoDescription/
-
发布时间:2011年
-
简介:MSVD(Microsoft Video Description Dataset)是一个广泛用于视频字幕任务的基准数据集,包含 1,970 个短视频片段,总时长约 10 小时,平均每个视频片段时长 10 秒。其标注形式为每个视频片段对应40条人工撰写的自然语言描述,以JSON格式存储,标注内容覆盖视频中的核心动作、物体交互及场景信息。该数据集的核心特点包括:1)内容多样性高,涵盖日常活动、人物互动等场景,如烹饪、运动、对话等;2)标注密集且质量高,每个视频提供多视角描述,增强模型对语义丰富性的理解;3)广泛用于视频-文本对齐、字幕生成等任务,常与MSR-VTT等数据集结合评估模型泛化能力。数据集共划分为 1,200 个训练样本、100 个验证样本和 670 个测试样本,其标注复杂度与场景覆盖度为视频理解模型提供了关键挑战。

2. Tumblr GIF(TGIF)
-
发布方:University of Rochester, Yahoo Research
-
下载地址:https://raingo.github.io/TGIF-Release/
-
论文地址:https://openaccess.thecvf.com/content_cvpr_2016/papers/Li_TGIF_A_New_CVPR_2016_paper.pdf
-
发布时间:2016年
-
简介:TGIF 数据集是一个专门用于动画GIF理解与描述的大规模基准数据集,包含 100,000 个从Tumblr平台收集的动画GIF片段,每个GIF片段对应1至3条人工标注的自然语言描述,总计 120,000 条。该数据集的核心特点包括:1)聚焦动态场景理解,涵盖日常活动、物体交互等高复杂度视觉内容;2)标注类型多样化,支持多模态问答任务(如动作识别、数量统计、帧级细节推理);3)数据场景真实,包含大量社交媒体中常见的快节奏、低帧率动图,挑战模型对时序动态与语义关联的捕捉能力;4)推动动画描述、视频问答等任务的技术发展,广泛用于评估模型在短时序视频理解中的性能。

3. Charades-Ego
-
发布方:Carnegie Mellon University,Univ. Grenoble Alpes · Inria,Allen Institute for Artificial Intelligence
-
Homepage:https://prior.allenai.org/projects/charades-ego
-
论文地址:https://arxiv.org/pdf/1804.09626v2
-
发布时间:2018年
-
简介:Charades-Ego 是 CVPR 2018 年发布的首个成对视角行为识别数据集,包含 7860 个日常室内活动视频,涵盖 157 个动作类别的 68536 个时间注释。每个视频片段同步提供第一视角与第三视角的双模态数据。核心特点包括:1)成对视角对齐,支持跨视角行为理解与时空对齐研究;2)标注覆盖多标签行为识别与细粒度动作定位,每个视频平均包含 6.2 个动作片段;3)数据场景真实,聚焦日常家庭活动(如烹饪、清洁),包含复杂交互与遮挡情况;4)与 Charades 数据集形成互补,提供跨视角分析基准,推动第一人称视角动作识别模型的发展。该数据集广泛用于多视角动作检测、跨模态特征学习等任务,其标注复杂度与视角多样性为模型的鲁棒性与泛化能力提供了关键挑战。

4. ActivityNet Captions
-
发布方:Stanford University
-
下载地址:https://cs.stanford.edu/people/ranjaykrishna/densevid/
-
论文地址:https://openaccess.thecvf.com/content_ICCV_2017/papers/Krishna_Dense-Captioning_Events_in_ICCV_2017_paper.pdf
-
发布时间:2017年
-
简介:ActivityNet Captions 是一个用于视频语义理解的大规模数据集,扩展自原始 ActivityNet 数据集,专为识别任务设计。ActivityNet Captions 包含 20,000 个视频片段,总时长约 4,800 小时,每个视频平均含有 3.65 条时序定位的自然语言描述,总标注量达 100,000 条。其标注形式为每个视频片段对应多个时间戳对齐的文本描述。该数据集的核心特点包括:1)事件描述的密集性与多样性,涵盖日常活动、运动、对话等场景,支持多事件交叉分析;2)时序标注的精细化,要求模型同时处理时间定位与语义表达;3)广泛应用于视频字幕生成、事件检测及跨模态检索任务,推动长视频序列理解与多事件上下文建模的技术发展。
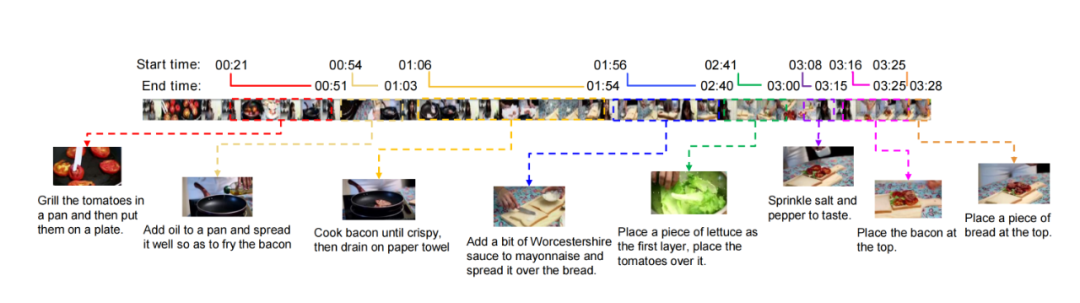
5. YouCook2
-
发布方:University of Michigan, University of Rochester
-
Homepage:http://youcook2.eecs.umich.edu/
-
论文地址:https://arxiv.org/pdf/1703.09788v3
-
发布时间:2018年
-
简介:YouCook2 是一个包含来自YouTube的 2,000 个烹饪视频的数据集,视频时长从几分钟到十几分钟不等,适用于学习复杂的烹饪过程中分步骤定位任务,尤其有助于提升具有挑战性的长视频中多步骤动作的分割和定位。
6. MovieNet
-
发布方:香港中文大学
-
Homepage:https://movienet.github.io/
-
论文地址:https://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123490681.pdf
-
发布时间:2020年
-
简介:MovieNet 是一个聚焦于电影级复杂场景理解的大规模多模态数据集,提供电影关键帧和相关元数据的全面收集,用于电影理解和推荐系统研究,其数据规模与标注复杂度为长视频序列理解与跨模态推理提供了重要基准。MovieNet 包含 1,100 部电影的关键帧、预告片、字幕、剧情简介及多维度标注信息。其标注形式以IMDb电影ID为索引,通过JSON文件提供多层次结构化标签:
-
场景划分:包含 42,000 个场景的时间边界、地点标签及行为片段; -
镜头类型标注:涵盖5种景别(如特写、全景)和3种运动方式(如静态、平移); -
人物信息:包含300余部电影中 130 万个人物边界框及 763,000 个演员身份标签; -
MovieNet 数据集的特点包括:1)多模态融合,整合视频、音频、文本及元数据;2)标注粒度精细,支持场景级语义分析与镜头语言理解;3)真实电影场景覆盖,包含复杂叙事结构与专业拍摄手法;4)跨任务支持,适用于视频检索、事件检测及电影美学分析等任务。

7. LSMDC(Large-Scale Movie Description Challenge)
-
发布方:加州大学伯克利分校·马克斯普朗克信息学研究所
-
Homepage:https://sites.google.com/site/describingmovies/
-
下载地址:https://sites.google.com/site/describingmovies/download?authuser=0
-
简介:LSMDC(Large-Scale Movie Description Challenge)是一项专注于电影内容理解与描述生成的大规模视频语言多模态挑战任务,于2015年首次提出。作为视频描述生成领域的标杆性挑战,其核心目标是解决传统视频理解任务中存在的语义粒度不足和跨模态对齐困难问题。通过结合电影这一富含复杂叙事、人物交互和时空动态的场景,LSMDC要求模型不仅识别视频中的物体与动作,还需理解事件逻辑、角色关系及上下文关联,最终生成自然且连贯的文本描述,推动视频理解技术从简单的动作识别向复杂语义推理和连贯叙事生成发展。
-
数据集规模与构成:LSMDC 数据集的原始数据来自 202 部电影,从中提取了约 118,081 个短片段(每个片段时长2-5秒),覆盖多样化的场景类型(如对话、动作、情感冲突等)。每个片段标注了单句或多句描述,描述内容来源于电影剧本或为视障人群设计的描述性语音服务(DVS),确保语义的丰富性和准确性。
-
标注任务:LSMDC 包含多个子任务,涵盖从基础描述生成到复杂推理的不同层次,包括视频描述生成(Video Captioning)、视频填空(Video Fill-in-the-Blank, ViFitB)、身份感知多句子描述(Identity-Aware Description),对模型提出了多维度挑战。
8. MAD(Movie Audio Descriptions)
-
发布方:King Abdullah University of Science and Technology,Adobe Research
-
下载地址:https://github.com/Soldelli/MAD
-
论文地址:https://arxiv.org/pdf/2112.00431
-
发布时间:2022年
-
简介:MAD(Movie Audio Descriptions)数据集是一个专门用于视频语言定位任务的大规模电影音频描述数据集,包含来自 650 部电影的 1,200 多小时连续视频片段及 384,000 条自然语言描述,覆盖22个电影类型,涵盖从经典到现代的多样化场景。该数据集的核心特点包括:1)长形式定位设置,支持复杂长视频序列的语义对齐;2)大型语言词汇表,包含电影对话中丰富的场景、动作和地点描述;3)挑战性标注要求,需同时处理时间定位精度与语义多样性;4)跨模态融合,结合视频、音频及文本信息,重点提供给视障人士的音频描述。

9. ViTT(Video-Timeline-Tags)
-
发布方:Mila & University of Montreal,Google Research
-
下载地址:https://github.com/google-research-datasets/Video-Timeline-Tags-ViTT
-
论文地址:https://aclanthology.org/2020.aacl-main.48.pdf
-
发布时间:2020年
-
简介:ViTT(Video-Timeline-Tags)数据集是一个专注于密集视频理解的人工标注基准数据集,包含 8,169 个视频片段,总标注量覆盖约 1,200 小时视频内容。其标注形式以时间轴标签为核心,每个视频被划分为多个时间片段(平均每个视频包含4-6个事件),每个片段对应精确到秒级的时间边界及1-3条自由文本描述,总计约 40,000 条。标注文件以JSON和TXT格式存储,包含视频ID、片段起止时间、描述文本及标注质量评分。ViTT 数据集的特点包括:1)密集时序标注,支持多事件定位与细粒度语义分析;2)场景多样性,覆盖日常活动、运动、对话等真实场景;3)标注形式灵活,兼容开放域文本描述与结构化时间信息;4)推动视频字幕生成、事件检测及多模态预训练模型的发展。ViTT 被广泛用于评估模型在复杂视频序列中同步处理时间定位与语义表达的能力,包含带有短暂时态本地化描述的教学视频,适用于视频摘要和指导生成。

视频字幕数据集通过构建多模态、时序化的训练信号、精心设计的标注体系,引导模型学习人类理解视频的认知逻辑。随着生成式 AI 向多模态、长序列方向演进,视频字幕数据集将呈现三大发展趋势:一是融合多模态标注,如结合眼动数据、3D场景信息增强语义表达;二是强化长时序标注,支持数小时级视频的连贯描述生成;三是探索少样本/无监督标注范式,利用大语言模型自动生成伪标签,降低标注成本。这些发展将进一步释放视频字幕数据集的潜力,推动生成式 AI 在智能监控、影视创作等领域的落地应用,为实现通用人工智能提供关键的数据基础设施。
整数智能信息技术(杭州)有限责任公司,起源自浙江大学计算机创新技术研究院,致力于成为AI行业的数据合伙人。整数智能也是中国人工智能产业发展联盟、ASAM协会、浙江省人工智能产业技术联盟成员,其提供的智能数据工程平台(MooreData Platform)与数据集构建服务(ACE Service),满足了智能驾驶(Automobile AI)、生成式人工智能(Generative AI)、具身智能(Embodied AI)等数十个人工智能应用场景对于先进的智能标注工具以及高质量数据的需求。

目前公司已合作海内外顶级科技公司与科研机构客户2000余家,拥有知识产权数十项,通过ISO 9001、ISO 27001、ISO 27701等国际认证,也多次参与人工智能领域的标准与白皮书撰写,也受到《CCTV财经频道》《新锐杭商》《浙江卫视》《苏州卫视》等多家新闻媒体报道。






原创文章,作者:整数智能,如若转载,请注明出处:https://www.agent-universe.cn/2025/03/43803.html